我是如何赢得吴恩达首届 Data-centric AI 竞赛的?
共
4003字,需浏览
9分钟
·
2021-11-09 15:44

大数据文摘授权转载自AI科技评论
编辑:黄继彦
校对:林亦霖
吴恩达在今年 6 月的时候宣布首届以数据为中心的人工智能(Data-centric AI)竞赛即将开赛,参赛“作品”的提交日期截止到9月初。10月初,吴恩达在其个人社交平台Twitter上向我们宣布了此次竞赛的获奖者,随后,也在其个人微信公众号上向我们简要介绍了竞赛的参与情况。这次竞赛共有489个参赛个人和团队提交了2458个独特的数据集。仅仅通过改进数据(而不是模型架构,这是硬标准),许多参赛者能够将64.4%的基准性能提高20%以上。最佳性能组的获奖者的成绩在86.034%至86.405%之间。“最具创新力奖”和“荣誉奖”的获奖者则都采用了新颖的方法,也取得了出色的成绩。经过角逐,Divakar Roy, Team Innotescus 和 Team Synaptic-AnN分别获得了最佳性能组的前三名。Mohammad Motamedi, Johnson Kuan 和 Team GoDataDriven 则是最具创新奖的获奖者,此外,Pierre-Louis bessecond 和 Team KAIST-AIPRLab 获得了荣誉奖。吴恩达激动万分地表示对所有参赛者感到骄傲。那么,获奖者对赢得吴恩达首届 Data-centric AI 竞赛的心情是怎样的呢?以下是此次竞赛最佳创新奖得主之一 Johnson Kuan 发布的博文,记录了他参赛时的过程以及获奖后的感受。在过去的几个月里,我有幸参加了吴恩达首届 Data-centric AI 竞赛。在此,我很高兴能和大家分享我是如何凭借“数据增强(Data Boosting)”技术获得最佳创新奖的。这场竞赛真正的独特之处在于,与传统的 AI 竞赛不同,它严格关注如何改进数据而不是模型,从我个人的经验来看,这通常是改进人工智能系统的最佳方式。考虑到有大量的开源机器学习模型库(包括预训练的深度学习模型),模型方面对大多数商业应用程序来说或多或少是一个已解决的问题。我们需要的是新工具和创新技术来系统地改进数据,Andrew显著地将其称为烹饪(训练模型)的高质量食材。3. 这项技术的动机以及如何将它推广到不同的应用程序。在本次竞赛中,每个参与者手里有大小约为 3K 的图像,这些图像是从 1 到 10 的手写罗马数字,我们的任务是优化模型在罗马数字分类方面的性能。此外,我们还获得了一本包含 52 张图像的标签簿,作为我们自己实验的小测试集,本标签簿不用于最终评估。https://worksheets.codalab.org/worksheets/0x7a8721f11e61436e93ac8f76da83f0e6模型架构保持固定(cut off ResNet50)并训练 100 个 epoch,同时根据验证集的准确性在 epoch 中选择模型权重。虽然模型和训练过程是固定的,但我们可以自由改进数据集并更改训练和验证数据分割。我们还可以添加新的图像,但在训练和验证分割中提交的图像组合必须小于10K。提交我们改进的数据集后,参与者将根据隐藏的图像测试集进行评估。考虑到最终提交的图像只能小于 10K,因此,参与者必须专注于在缺乏“大数据”的情况下获取“好数据”,这是因为 Andrew 觉得 “大数据” 在更传统的行业(如制造业、农业和医疗保健)的人工智能应用中非常常见。在进入解决方案的关键部分之前,我做的第一件事是遵循固定标签和删除不良数据的常见做法。
为了简化这个工作流程,我编写了一个 Python 程序来评估给定的数据集(在将其输入固定模型和训练程序之后),并生成一个包含每个图像记录指标的电子表格。该电子表格包含给定标签、预测标签(使用固定模型)和每个图像的损失,这对于分离不准确和边缘情况非常有用。下面举例。由 Python 生成的数据评估电子表格示例,用于简化以数据为中心的 AI 工作流程我最初使用这个电子表格来识别标记错误的图像和明显不是罗马数字 1-10 的图像(例如,在原始训练集中就有一个心脏图像)。
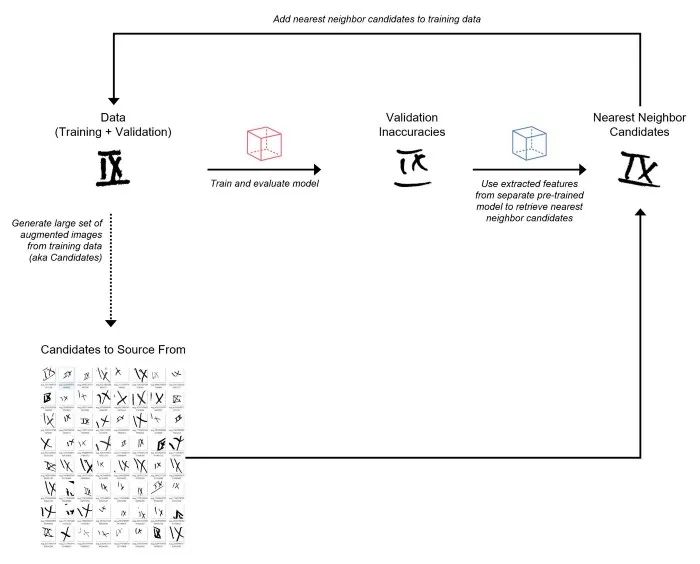
- 从训练数据中生成一组非常大的随机增强图像(将这些视为“候选”来源)。
- 使用另一个预训练模型从验证图像和增强图像中提取特征(即嵌入)。
- 对于每个错误分类的验证图像,利用提取的特征从增强图像集中检索最近邻(基于余弦相似度)。将这些最近邻增强图像添加到训练集。我将这个过程称为“数据增强”。
将来自训练集的增强图像作为候选源的“数据增强”过程- 虽然我在这次竞赛中使用了增强图像,但在实践中我们可以使用任何大的图像集作为数据源。
- 我从训练集中生成了大约 1M 的随机增强图像作为候选来源。
- 数据评估电子表格用于跟踪不准确(错误分类的图像)并注释数据。另外,我还创建了一个带有PostgreSQL 后端的 Label Studio 实例,但由于不必要的开销,我决定不将其用于本次比赛。
- 对于预训练模型,我使用了在 ImageNet 上训练的 ResNet50。
- 每个错误分类的验证图像要检索的最近邻的数量是一个超参数。
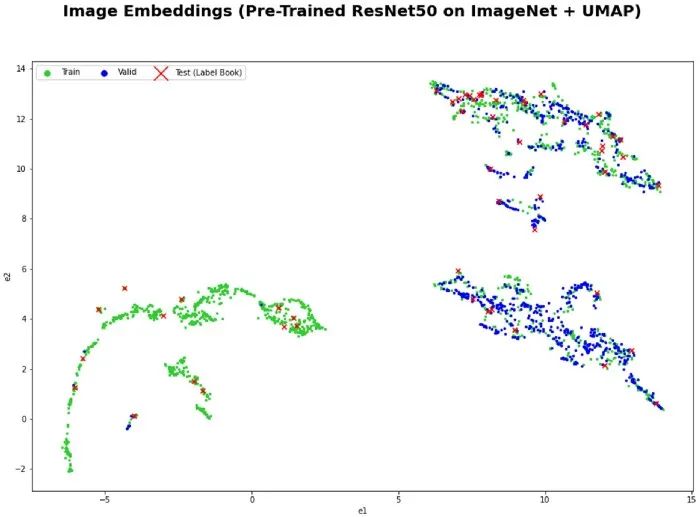
https://github.com/spotify/annoy从图像中提取特征的一件很酷的事情是,我们可以使用 UMAP 在 2D 中将它们可视化,以更好地理解训练和验证集的特征空间。在下面的可视化中,我们可以看到,有趣的是,给定的训练数据分布与给定的验证数据不匹配。在特征空间的左下角有一个区域我们没有验证图像。这表明,在运行上面的“数据增强”过程之前,可以尝试重新调整训练和验证数据分割。- 我在原先的作品(见 2019 年的一篇博文)里构建了一个电影推荐系统,这个系统通过从关键字标签中提取电影嵌入并使用余弦相似度来查找彼此相似的电影。
- 我之前使用过预训练的深度学习模型将图像表示为嵌入。
- 在 Andrej Karpathy 2019 年的演讲中,他描述了如何有效地获取和标记从特斯拉车队收集的大量数据,以解决通常是边缘情况(分布的长尾)的不准确问题。
- 我想开发一种以数据为中心的增强算法(类似于梯度增强),其中模型预测中的不准确之处在每个步骤中通过自动获取与那些不准确之处相似的数据来迭代解决。这就是我称这种方法为“数据提升”的原因。
https://towardsdatascience.com/how-to-build-a-simple-movie-recommender-system-with-tags-b9ab5cb3b616Andrej Karpathy 2019 年的演讲:https://www.youtube.com/watch?v=FnFksQo-yEY&t=1316s当我最初考虑这种“数据增强”的方法时,我需要弄清楚如何自动生成大量新的候选图像作为来源。我决定尝试随机增强原始训练数据,以生成大量增强图像作为候选来源。下一步,我利用预训练模型提取图像嵌入,用于计算图像之间的余弦相似度,从而自动获取与验证集中错误分类图像相似的增强图像。
在这里,使用预训练模型进行一般特征提取是一种迁移学习方法。我假设通过以这种方式获取增强图像,我们可以提高模型从分布的长尾学习模式的机会。正如Andrej Karpathy在2019年特斯拉“自主日”(Tesla’s Autonomy Day)的演讲中所指出的那样:此外,由于竞赛的数据大小限制为 10K 的图像,这种“数据增强”方法是一种确定在给定的约束条件下哪些随机增强图像最好包含在训练集中的方法。我可以看到这种技术推广到我们可以访问的机器学习的不同应用程序中:
- 为实体(例如图像、文本文档)提取嵌入的预训练模型;
- 可供选择的大量候选数据集(例如特斯拉车队、网络上大量的文本语料库、合成数据)。
例如,我可以想象将这种技术推广到文本分类中,我们使用预训练的 Transformer 模型(比如 Bert)来提取文本的嵌入。然后,我们可以从我们的特定域的验证集中获取与不准确性类似的文本(假设有一个大型的在线语料库)。
我希望这篇博文能说服你加入这场以数据为中心的 AI 运动。在更广泛地应用人工智能方面,还有许多令人兴奋的工作要做。我相信,对人工智能系统数据管理的共同关注将使我们实现这一目标。
如果你有任何问题或希望合作,请随时与我们联系。你可以在 LinkedIn 或 Twitter 上找到我。https://towardsdatascience.com/how-i-won-andrew-ngs-very-first-data-centric-ai-competition-e02001268bda
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报