
与时代共振,AI助力工业缺陷检测

1 问题概述:工业缺陷检测场景中的语义分割
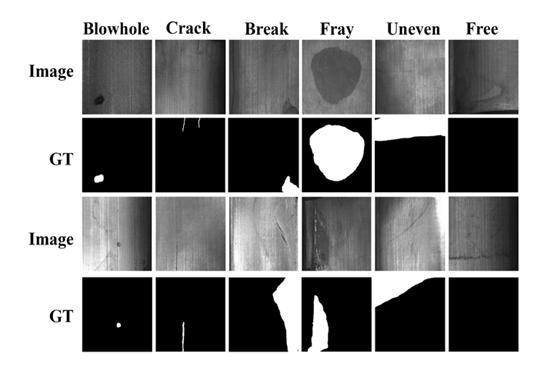
类间差异小,存在模糊地带:以磁瓦缺陷数据集[4]为例,线状物体在多种缺陷或者无缺陷情况都有出现。这是这一数据集的固有属性,也是缺陷检测难做的原因。有一些情况,由于正负样本类内差异小,比如按照面积、灰度值等绘制其直方图,中间过渡区域永远存在一定量的样本,处于灰色地带,很难分辨。
类内差异大:同一类缺陷下,缺陷的大小,形状,位置多变。
样本不平衡:有些数据集中,严重存在着正负样本不平衡的问题,良品多,不良率小。
缺陷级别小:例如在磁瓦缺陷数据集中 ,有些裂痕或者空洞的尺寸很小,对于目标细节的分辨率要求高。
2.选择什么样的网络拓扑可以捕捉目标细节?
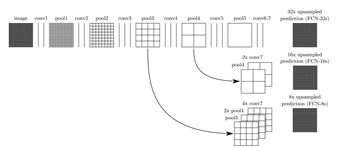
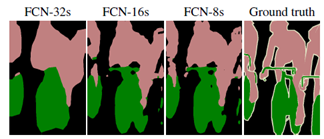

它改善了边界的预测,因为避免了像素位置信息的损失;
它对算力友好,这是由于本身上采样不会参与网络训练;
这种形式的上采样可以合并到任何编码器-解码器结构中。
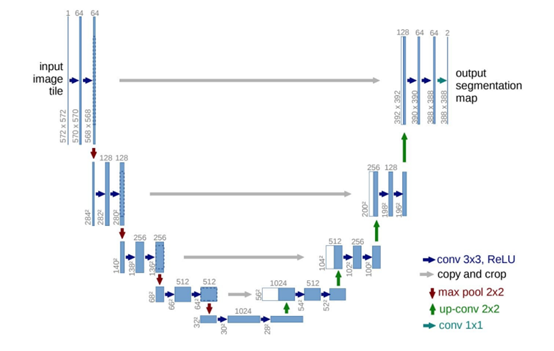
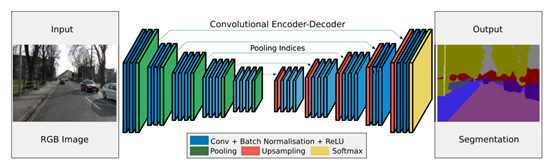
通道的数量在框的顶部表示。每一层的x-y尺寸在框的左下边缘提供。白框表示复制的特征。箭头表示不同的操作。
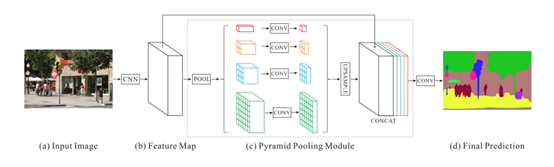
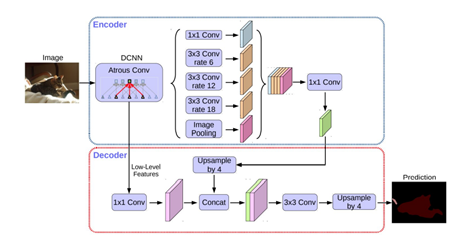
加入特征的全局平均池化。图8中的Image Pooling就是全局平均池化,它的加入是对全局特征的加强。另外,我们也可以把Deeplabv3+模型看成一个编码器-解码器模型。编码器部分可以利用Xception结构,这是一种可以有效减小参数量的深度可分离卷积。[9-11]
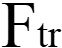 )得到一个大小 (H x W xC) 的特征图U。再经过挤压(
)得到一个大小 (H x W xC) 的特征图U。再经过挤压(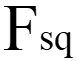 )操作,特征图变成了 1 x 1 x C 的特征向量,特征向量是特征图U在每个通道全局最大池化的结果。经过激活(
)操作,特征图变成了 1 x 1 x C 的特征向量,特征向量是特征图U在每个通道全局最大池化的结果。经过激活(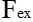 )操作,特征向量的维度没有变,但是向量值变成了新的值。这一步的操作视SEblock的结构而定,常见的有Inception、Resnet等等。这些值通过和U经过尺度变换(
)操作,特征向量的维度没有变,但是向量值变成了新的值。这一步的操作视SEblock的结构而定,常见的有Inception、Resnet等等。这些值通过和U经过尺度变换(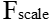 )的值乘积后得到加权的最后结果
)的值乘积后得到加权的最后结果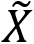 。的维度和特征图U一致。
。的维度和特征图U一致。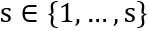 。每个尺度都通过Deeplab(权重值在所有尺度上共享),并生成尺度为s的得分图,表示为
。每个尺度都通过Deeplab(权重值在所有尺度上共享),并生成尺度为s的得分图,表示为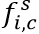 。为了使得不同尺度的得分图具有相同的分辨率,通过双线插差值的办法调整小尺度的得分图。最后通道 c,位置 i 特征图上的值:
。为了使得不同尺度的得分图具有相同的分辨率,通过双线插差值的办法调整小尺度的得分图。最后通道 c,位置 i 特征图上的值: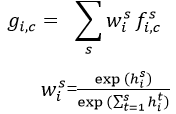
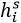 代表尺度 s 的得分图中位置 i 的得分值。
代表尺度 s 的得分图中位置 i 的得分值。3. 缺陷样本少导致样本不平衡怎么办?
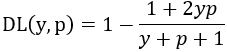
4. 一些思考
参考文献:
[1] S.Minaee, Y. Y. Boykov, F. Porikli, A. J. Plaza, N. Kehtarnavaz, and D.Terzopoulos, "Image segmentation using deep learning: A survey," IEEE Transactions on Pattern Analysis andMachine Intelligence, 2021.
[2] J. Long, E. Shelhamer, and T. Darrell,"Fully convolutional networks for semantic segmentation," in Proceedings of the IEEE conference oncomputer vision and pattern recognition, 2015, pp. 3431-3440.
[3] M. Cordts et al., "The cityscapes dataset for semantic urban sceneunderstanding," in Proceedings ofthe IEEE conference on computer vision and pattern recognition, 2016, pp.3213-3223.
[4] Y. Huang, C. Qiu, and K. Yuan,"Surface defect saliency of magnetic tile," The Visual Computer, vol. 36, no. 1, pp. 85-96, 2020.
[5] W. Liu, A. Rabinovich, and A. C. Berg,"Parsenet: Looking wider to see better," arXiv preprint arXiv:1506.04579, 2015.
[6] O. Ronneberger, P. Fischer, and T. Brox,"U-net: Convolutional networks for biomedical image segmentation," inInternational Conference on Medical imagecomputing and computer-assisted intervention, 2015, pp. 234-241: Springer.
[7] V. Badrinarayanan, A. Kendall, and R.Cipolla, "Segnet: A deep convolutional encoder-decoder architecture forimage segmentation," IEEEtransactions on pattern analysis and machine intelligence, vol. 39, no. 12,pp. 2481-2495, 2017.
[8] H. Zhao, J. Shi, X. Qi, X. Wang, and J.Jia, "Pyramid scene parsing network," in Proceedings of the IEEE conference on computer vision and patternrecognition, 2017, pp. 2881-2890.
[9] L.-C. Chen, G. Papandreou, F. Schroff,and H. Adam, "Rethinking atrous convolution for semantic imagesegmentation," arXiv preprintarXiv:1706.05587, 2017.
[10] L.-C. Chen, G. Papandreou, I. Kokkinos,K. Murphy, and A. L. Yuille, "Deeplab: Semantic image segmentation withdeep convolutional nets, atrous convolution, and fully connected crfs," IEEE transactions on pattern analysis andmachine intelligence, vol. 40, no. 4, pp. 834-848, 2017.
[11] L.-C. Chen, Y. Zhu, G. Papandreou, F.Schroff, and H. Adam, "Encoder-decoder with atrous separable convolutionfor semantic image segmentation," in Proceedingsof the European conference on computer vision (ECCV), 2018, pp. 801-818.
[12] J. Hu, L. Shen, and G. Sun,"Squeeze-and-excitation networks," in Proceedings of the IEEE conference on computer vision and patternrecognition, 2018, pp. 7132-7141.
[13] L.-C. Chen, Y. Yang, J. Wang, W. Xu, andA. L. Yuille, "Attention to scale: Scale-aware semantic imagesegmentation," in Proceedings of theIEEE conference on computer vision and pattern recognition, 2016, pp.3640-3649.
[14] S. Jadon, "A survey of lossfunctions for semantic segmentation," in 2020 IEEE Conference on Computational Intelligence in Bioinformaticsand Computational Biology (CIBCB), 2020, pp. 1-7: IEEE.
[15] C. Shorten and T. M. Khoshgoftaar,"A survey on image data augmentation for deep learning," Journal of Big Data, vol. 6, no. 1, pp.1-48, 2019.
[16] Z. Li and D. Hoiem, "Learningwithout forgetting," IEEEtransactions on pattern analysis and machine intelligence, vol. 40, no. 12,pp. 2935-2947, 2017.
作者简介

王可汗,清华大学机械工程系,摩擦学国家重点实验室。联系方式:wangkehan2018@yeah.net
编辑:黄继彦
校对:林亦霖