
万字长文细说工业缺陷检测
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
作者丨皮特潘
编辑丨极市平台
导读
本文主要内容还是围绕着场景分析与数据理解、方法论与算法设计、工具链与部署落地等方面进行展开,重点关注的是顶层设计。
注意:本文从我的一个PPT整理而来,行文可能比较随意,很多细节没有写清楚,后续有时间会持续修改。
上次说到,要写一个系列,最后整理才发现,还是合成一篇比较好一点。
皮特潘:AI 工业缺陷检测 —— 写在前面的话
https://zhuanlan.zhihu.com/p/375383384
主要内容还是围绕着场景分析与数据理解、方法论与算法设计、工具链与部署落地等方面进行展开。重点关注的还是顶层设计,因此涉及到的很多具体的细节没有说太多,仁者见仁智者见智吧。在平时工作中和思考问题上,我喜欢用简单粗暴的手段去分析,比如:本质上,和某某没有区别,说白了就这等语气。目的就是透过现象看本质,抓住主要矛盾。
皮特潘:谈一谈我对AI项目落地的看法
https://zhuanlan.zhihu.com/p/336671388
内容提要
本文大致的脉络是按照场景、数据分析,方法论算法设计,工具链与部署等进行展开。行文中一些比较重要点的,会单独开篇幅进行展开。包含以下论点:
主要难点
场景分析
缺陷归纳
简单粗暴的可行性分析
数据的四大难点
数据生成
场景VS数据
方法论
算法积木
任务拆分
定制分类模型
定制语义分割模型
语义分割利器dice loss
定制目标检测模型
正常样本建模
工具链
技术壁垒
总结
(一) 主要难点
我认为缺陷检测没有啥难的,基本上都可以做。那为啥槽点还那么多?我认为很大一部分是AI的槽点,因为目前使用AI来做是主流,或者说只传统方法搞不定的,没办法,只有上AI的方法。AI的槽点有很多,例如:
多少人工就有多少智能,太依赖于标注的数据;
过拟合严重,泛化能力差;
容易被攻击到,没有提取到真正的特征;
提取特征太多抽象,可解释性差,大家都是“黑盒子”玩家;
经验学、尝试学,没有建立起方法论,trick太多,很多都是马后炮强行解释;
“内卷”严重,nlp领域的sota 拿到CV,各种模改就work了?甚至都使用mlp进行返租现象,让我们一时半会摸不到方向。
当然,学术界和工业界也有一条巨大的鸿沟。学术界在于新,有创新点,在开源数据上各种尝试。工业界强调的是精度、成本、落地。再者场景过于分散,没办法达成一致的共识,场景、数据、需求等均是如此。
单单从工业界来看,在“缺陷检测”这一个细分的场景(其实也不是啥细分场景,所有找异常的都可以叫缺陷检测)。也有很多的槽点或者坑点,我认为原因如下:
方法论没做好:例如迭代中涉及多个环节,管理容易混乱,或没有意识到baseline数据集的重要性,敏捷开发变成扯皮甩锅。
demo难做:业务场景分散,没有现成的可以直接展示。方案涉及光学硬件,做demo耗时耗力,关键的是最后不一定能拿下。
更换型号难做:光学+标注+训练+部署一条龙,对工具链的用户体验要求非常高。有时别提用户体验了,甚至一个项目现做一套也不夸张。
高度定制:还是那句话,业务场景分散,推广困难,复制基本等于重做。
精度需求:用户期待高,动辄要求100%?超过人类?
检测时间:人工一个小小的动作,自动化执行超级复杂。尴尬的是面对的产品价值可能很低,比如几毛钱的一个塑料制品。
AI+传统:AI信不过,传统来兜底。结果超参过多,运维困难。单纯AI有时也会存在模型过多的情况。
从业务、工具、管理上来说,有三大难点:
业务难点:场景分散,更换型号困难,大规模标注困难,理解数据需要一个过程。
工具难点: 工具都有,但是整合困难。
管理难点:更新迭代,敏捷开发,需要需求、光学、标注、算法、运维等多方人员协同完成。
(二)场景分析
本文讨论的是工业场景,那就先和自然场景比一比吧!如下:
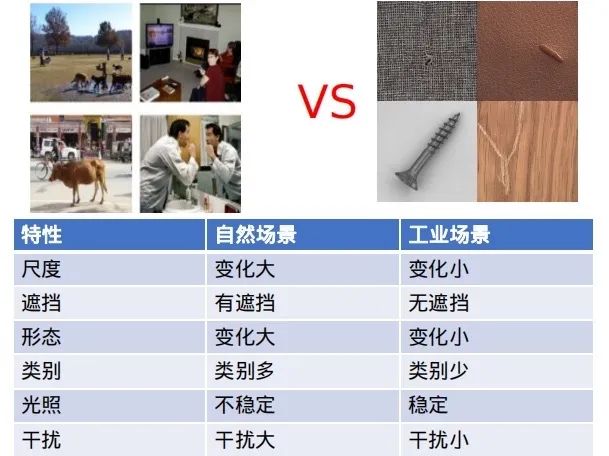
当然有一个非常重要的特性没有说:
自然场景一般是强语义信息,缺陷检测一般为弱语义信息。近期利用轻量级语义分割训练缺陷检测不好使有感而发。缺陷检测不需要特别大的感受野,一般为纹路上的缺陷,局部区域就可以判别。
貌似难度比自然场景少不少,再仔细分析一下,工业场景其实有以下几个特点:
业务场景过于分散 ,对标一下“人脸”,甚至“OCR”等领域,缺陷检测场景还是非常分散的,难以归纳。
受限、可控 ,有比较的大人工干预空间。例如可以利用一些光学、机械结构等设计降低场景的复杂,使得我们面临的场景更加纯粹。
一般面临目标比较微弱 ,这个目标缺陷的形态、颜色等有关。有时还会有一些例如黑色纹理上的黑色缺陷,强烈吃视角的缺陷等;
需求不太明确,很多时候做不到非黑即白的“一刀切。其实仔细思考,并不是客户给不粗明确的需求,而是场景和数据本身的固有属性,需求在执行的时候很难做到一致性,这点下面的数据分析会细说。
精度指标要求比较高,动辄100%还是比较夸张的。不过以我个人的经验,100%需求的地方,还是比较好做的。一般1个点的漏检,2到3个点的误检也算比较理想的结果了。不过有一点值得说明的是,非常明显的漏检和误检就是低级错误,要不得的。
以上是工业缺陷检测场景的固有属性。针对该场景,主要有以下三点需求:
捡出NG和GOOD,这个是最基础的任务,不然不能称之为缺陷检测;
定位缺陷的位置,方便归因分析、指标统计、设备升级、维修等;
给出缺陷的量化指标,例如面积、长度、对比度;一般对应的上层任务有缺陷分级、需求定制或变更。
(三)缺陷归纳
做好缺陷的归类,才容易下手。这里给出三种归纳方法:
归纳一:
纹理缺陷:替代原始样本纹路表现,位置、大小、形态不固定;划痕、脏污等;
结构缺陷:与目标结构有关,其位置、形态较固定,可能不存在量化的概念(错漏反);
其他缺陷:例如医学图像、一些红外热成像、超声波成像等,可能无法靠肉眼建立精准的对应关系
综合以上
归纳二(站在正常样本建模的角度):
纹理(一般指重复的结构,可能存在颗粒比较大的纹理)
非纹理对齐:与结构相关,但是可以做到对齐
非纹理无法对齐:与结构无关,但是很难对齐
综合以上
归纳三(形态上):
加法:脏污、异物、附着、
减法:残缺、划痕、破损
替换:混色、异色、杂质、混淆
变形:扭曲、尺寸、褶皱
(四)简单粗暴的可行性分析
需求非常多,有时甚至来不及打光验证。因此我有一套简单粗暴的可行性分析办法。主要针对业务场景来说。当然这只是粗糙的可行性分析,只能建立大致的、初步的印象。具体能不能做,还要从光学、结构复杂度、成本、运维、打开市场、推广等多个维度进行评估。
简单粗暴包括以下两个点:

明显:缺陷清晰可见,肉眼容易辨别,同时也是对光学成像提出要求;
明确:缺陷标准定义明确,没有争议,是对需求进行筛选;
基本上满足以上两点,就可以认为该case是可行的,基本可以做的。不过实际的情况是比较复杂的。仅仅靠“明显”和“明确”会把很多机会拦截在外。这种定义无可厚非,但是不够深入,给算法设限。缺陷检测,很难做到这两点的理想情况。且看下一小结数据的详细分析。
(五)数据的四大难点
难分、多样性、不平衡、数据脏。把握难点,针对举措。
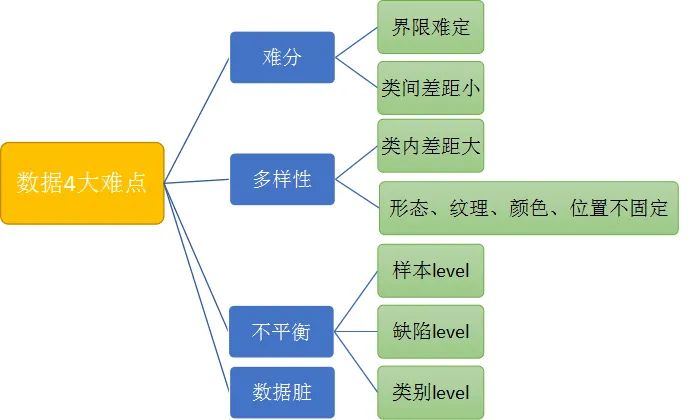
5.1 数据难分
直接后果就是标准难定,学术一点来说就是正负样本类间差距较小,不是非黑既白的一刀切能够搞定的,很难有一个一致性的标注将正负样本分开。也就是需求标准难定,即便是人工也很难保证。标准可能还比较好定,但是执行起来较为困难。
这个放到第一点,因为它是场景和数据的固有属性,人工很难改变,这也是大家吐槽缺陷检测难做的主要原因。不管用任何手段去描述缺陷,都不能做到明显可分。比如按照面积、灰度值等绘制其直方图,中间过渡区域永远存在一定量的样本,处于灰色地带,模棱两可。不管你是多人标注也好,不管你是做量化指标也好,总很难有好的办法改变这一现状。
有人可能会说,直接给阈值进行一刀切或两刀切,阈值交给客户来定。不过我们自己本身要想明白这个事情:不管是AI,还是人工,都会检出灰色地带。该场景存在这种情况,那么说明其需求本应该能够接受灰色地带的数据分错。
标注测试集就很难做,例如甲方合同明确要给出准确率。该问题的存在,很难达到理想的指标。所以如果面临该场景,建议在统计指标上,给出明显漏、明显误等。不然会陷入“清洗数据”、“更改需求”、“重复试验”的死循环,无法解脱。
能否给出对应的量化指标,也是很大的问题,比如明显的缺陷判分很低,微弱的缺陷置信度又很高。降低客户的期望也好,让客户理解AI判定过程也好,总之就是既然想让AI代替人工,我是可以做到。
针对该场景,我们要做的是:易分样本(也就是明显缺陷和明显不是缺陷)不能出错,然后在漏检和误检的tradeoff寻求一个平衡。一般客户会有“直通率”这个概念,可以多次磨合,多次迭代,趋向用户期待。
5.2 多样性不够
这点表现为类内差异过大。比如同样是划痕,表现形式各种各样,有的发白,有的发黑,有的吃视角,有的发生在边缘地带等等,出现在不同位置,表现形式都不一样。因此导致一个问题:你很难收集到全部形态的缺陷样本,所以在测试集上很难有一个不错的表现。也就是你的训练集和测试集存在的明显影响性能的偏差,这里的偏差不是标注导致的,而是数据本身导致的。这种情况还是比较高频率能够遇到,比如和客户聊一个需求的时候,对于某一种缺陷,他会说比较大概率发生在A处,但是不能排除发生在其他地方的概率。问题就是目前很难收集到样本,即便收集到样本,也很难覆盖所有的情况。
一般我们做一个任务,会有一份标准测试集,方便我们的方案、算法进行迭代。没有测试集,精度指标无从谈起。由于缺陷表现的多样性问题,我们的标准测试集可能就没有那么的“标准”。实际数据集构建的过程中,尽量保证较大的覆盖率。多样性图片拿不到,但是“缺陷描述”还是可以拿得到的。因此需要结合一些正常样本学习和数据生成的方法来降低“多样性不够”带来的影响。
5.3 样本不平衡
表现在3个方面:
从样本级别来看,是不平衡的,大量的都是正常样本,NG样本占比较小;每天会收集海量的图,有缺陷的比较少。
从缺陷实例级别来看,缺陷占整体较小,例如500w相机拍摄图片,25002000pix尺度上,缺陷尺度可能小到1010pix的水平。缺陷过小会带来一个严重问题。没办法进行resize(当然使用高分辨率的相机本意也是更精准的检测尺度小的缺陷)。导致的问题是:测试的时候,1是耗时,2是比较难控制误检的。例如siliding window检测,即便每一个patch预测准确率是99.9%,综合起来,性能下降的非常厉害。
从类别上来看是不平衡的,会存在某一类占比较大,有些缺陷占比较小。实践证明:只要有足够多的样本,即便是非常微弱的缺陷(这里的定义是肉眼可判别),网络也可以识别。应对方法很多,无外乎是数据生成、数据增强、过采样、loss上设计、训练策略上等等。
5.4 数据脏
工程上的问题,必须考虑数据脏的情况。
数据脏就是标注的时候把标注类别搞错。搞错大家一般会认为是数据难分的原因,其实不然,数据难分,也就是标准难定或者无法清晰给出,因此这部分导致的原因不能单纯归纳为数据脏。但是这里为了便于分析,我们区别对待。脏数据会对网络训练带来不利的影响,强行训练会有过拟合的风险。因为网络提取通用特征,拟合不到缺陷只能去拟合其他噪声了。不过也有说法是,脏数据作为噪声,也能给网络带来好的收益,让网络搜索参数的时候增加扰动,避免陷入局部最优,却能防止网络过拟合。不过一般任务:数据还是越干净越好。
那就是数据清洗,例如交叉验证。学术上也有一些噪声样本学习的方案。数据脏还比较好办,归根到底是数据标注的问题。随着训练迭代以及人工清洗,可以很好的改善这一情况。
(六)数据生成
虽然是工业场景,数据会源源不断过来。但是上文提到数据的几大问题,例如样本不平衡等,所以有时我们会需要生成一部分的数据。还有一种情况,在项目初期,我们往往“打样”。所谓demo阶段,是拿不到足够多的数据的。另外,数据肯定是多多益善,如果我们有生成数据的巧妙方法,训练从中受益的话,也很大程度上降低了数据收集、标注、清洗的成本。
数据生成有传统方法和深度学习方法两种可用。传统方法可以进行一些图像融合,例如直接将缺陷裁剪下来到处贴,为了保证生成的逼真一点,还是需要一些融合的手段,例如泊松融合和边缘融合等。当然,有些场景,直接修改图片局部的灰度值也可以生成逼真的缺陷。我就单单利用修改图片的灰度和对比度就生成了很多以假乱真的图片。深度学习方法一般用GAN和VAE等生成模型可用,利用GAN可以直接从噪声生成数据,不过产生新的对网络训练有受益的信息比较有限。可以利用类似pix2pix的方案进行图片编辑。传统方法中的图片融合也可以利用GAN来做。
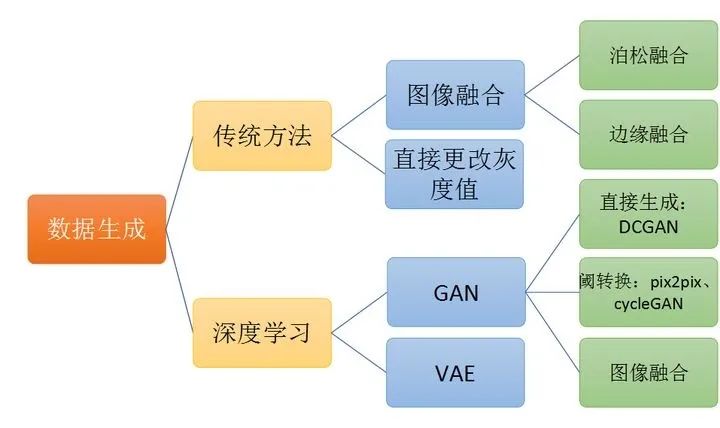
(七)场景VS数据
前面主要说了场景和数据的一些东西,这里对比再看一下。场景是客观的,固有属性,你做与不做,它都在那里。
数据是有主观的成分在里面:从其光学设计、标准执行等上来说,有很大人为因素。也是上文说的可控。具有很大的操作和设计空间。
但是有时还要思考:值不值得做?可能是时间、成本、性价比、大规模推广等方面的原因。当然,大部分场景还是很容易做的,因为在工业领域,至少是受限的和可控的场景。关键要分清主要矛盾和次要矛盾。
(八)方法论
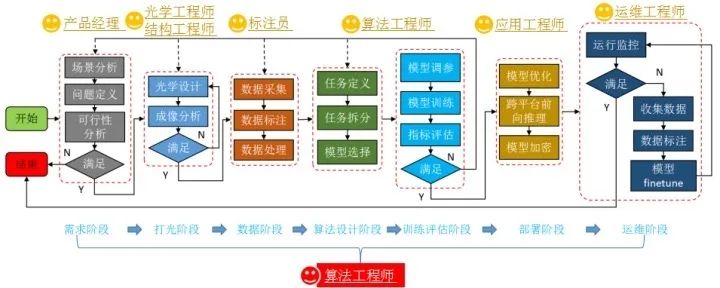
缺陷检测是整个系统工程,每个阶段都有不同的人参与,而算法工程师几乎要从头打到尾。
这里重要要建设四种意识,要进行全员建设。从产品经理、光学工程、结构工程师、算法工程师、应用工程师、运维工程师,当然也包括决策者:
版本管理意识:不光代码有版本管理,算法、数据、环境甚至硬件都要有版本管理的概念。
baseline意识:baseline也就是我们版本管理的起点,不断优化的基石。
闭环意识:既然用AI,数据驱动的工程,那么请问能够一次性给到我完美的数据集?如果不能,请具备闭环意识,做好更新迭代、持续优化的工作。
tradeoff意识:精度和时间是tradeoff,准确率和召回率是tradeoff,虚检和漏检是tradeoff。tradeoff的意思就是要综合考虑。
在进行需求挖掘和可行性分析的时候,有一些一些值得思考点
用户理解上,建立一致性的期望。全员更加理性认识AI方案。
用户可能给不出明确的需求,要共同发掘一致性的需求。
需求、光学确定以后,建立标准测试集。
对于算法难以界定的灰色地带,接不接受人工二次复检?
是否涉及更换型号?
什么是绝对不能容忍的错误,算法的下限在哪里?
对时间上的要求?
标准确认上,采用多人标注,便于评估数据的一致性。
(九)算法积木
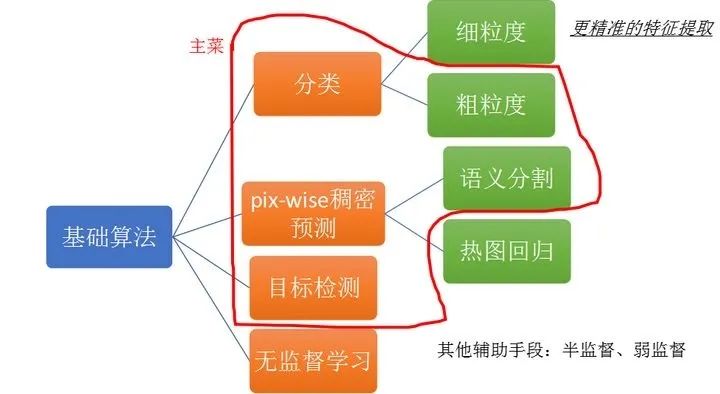
如上图所示,我们能用到的深度学习算法积木很多,首先是分类、分割、检测三大任务,这是我们的主菜。当然还有一些别的方法,例如分类算法中有细粒度分类,可以更加精准的提取微弱的特征,细粒度算法一般会用到打乱和注意力机制,对纹理上的缺陷识别会更优一点。另外,应用语义分割任务做缺陷检测,其实缺陷检测并不局限语义分割,它更像提取一张高斯热图,有缺陷的地方概率高,背景区域概率低。因此有一些热图回归的做法也可以应用。除了监督方案,在应对缺陷样本少的场景,我们还可以选择无监督学习方案。
当然,上面也说了,数据场景复杂,一致性问题难以保证。而且面临的数据量比较大,因此你还可以使用一些半监督、弱监督的手段来降低标注的工作量。
(十)任务拆分
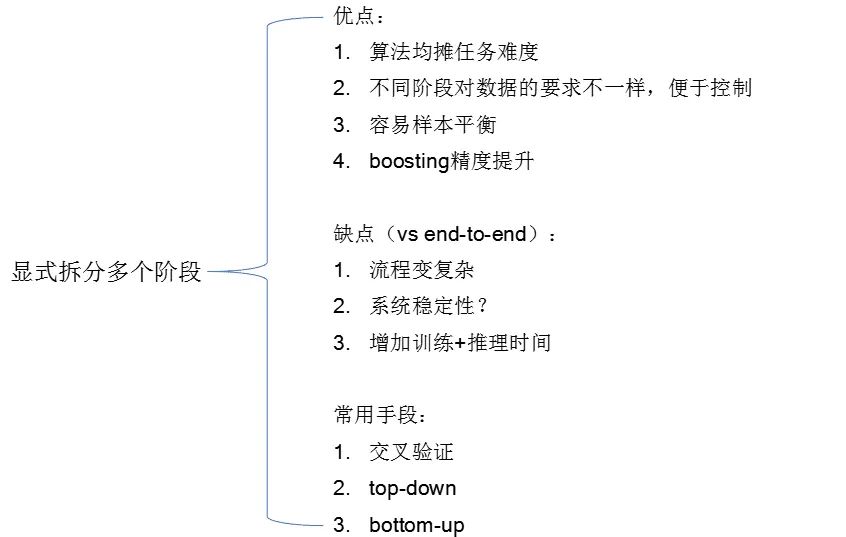
任务拆分,可以降低算法的难度。多个结果进行分摊任务难度,另外不同阶段对数据的依赖不一样,多个阶段拆分更容易控制,尤其是在样本平衡方面。多个阶段对标的是端到端,可以做到精度方面的提升。
(十一)定制语义分割模型
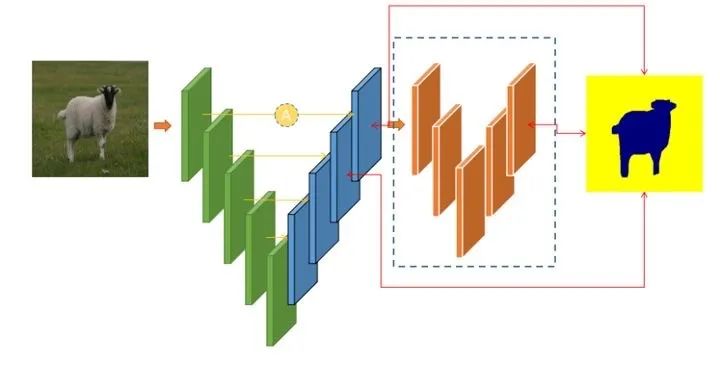
语义分割容易扩展,可以输出最精准的逐像素特征,依赖样本更少(当然标注量比较大),非常适合来做缺陷检测任务。下面给出一些经常叫魔改也好,定制也好的特性。
定制特性:
多通道输入:适配多个光源的复杂场景
骨架任意切换:resnet、effecientnet
多个head:多任务,处理互斥类别
attention辅助head: aspp、danet、senet、non_local
中继监督:增强梯度信息
refine module(Cascaded):结果精修,过滤虚检
不对等输出:256256 > 88等,加速,牺牲定位精度,降低拟合难度
attention机制:通道、空间、nonlocal,提升全局感知能力
通道剪枝:手动,network-slimming
当然再配合一些训练tricks,可以达到事半功倍的效果:
过采样:进行正负样本平衡,非常基础和常用的手段,经常使用crop的手段。
动态平衡dataset:其实和过采样有异曲同工之妙,不过该方法是随着训练过程动态调整的,可以理解为作用在数据层面的难样本挖掘。
标签平滑:语义分割标注是有偏差的,主要体现在边界上,所以可以进行标签平滑策略。
diceloss:样本不平衡神器,必须好好利用;
难样本挖掘:
loss截断:同样应对标注偏差的情况
对抗训练:预防对抗攻击
(十二)dice loss 10 问
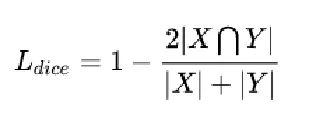
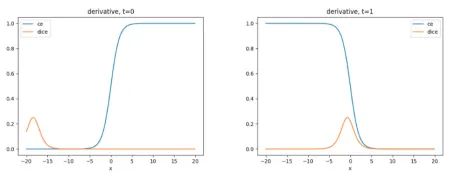
众所周知,diceloss是语义分割,尤其是应对正负样本不平衡的一把利器。但是它也有一些槽点,因此必须整明白。下面提出diceloss十问,暂时不给出答案。之前也写过一个diceloss的深度解析,可以参考一下:
皮特潘:语义分割之dice loss深度分析(梯度可视化)
https://zhuanlan.zhihu.com/p/269592183
和ce的区别?
label为0的像素区域有无监督?
正常样本有无作用?
正负样本比例的影响、怎么设置?
epsilon的影响?
有无梯度消失或饱和的现象?
能否不使用sigmoid激活函数?
能否通过权重初始化改善梯度消失?
震荡的本质原因?
预测边缘更锐利?
(十三)定制分类
分类是最简单的任务,当然缺陷检测可能会对它提出了更高的要求。例如下面这个方法
皮特潘:DCL细粒度分类网络小记
https://zhuanlan.zhihu.com/p/328377321
分类任务有时会结合交叉验证、多模型boosting、弱监督语义分割。
(十四)定制目标检测
很多技巧性的东西,都是通用的目标检测技巧,例如:尺度问题、形变问题等等;本文不再叙述。
(十五)正常样本建模
传统方法:(场景受限,需要调参数,可用于防呆,明显缺陷没问题,微弱缺陷效果不行)
对齐+对减
对齐+GMM
深度学习:
基于特征统计
基于GAN
基于样本生成
对场景进行筛选,从简单、对齐入手。注意:可以利用监督学习寻找算法的上限

(十六)工具链
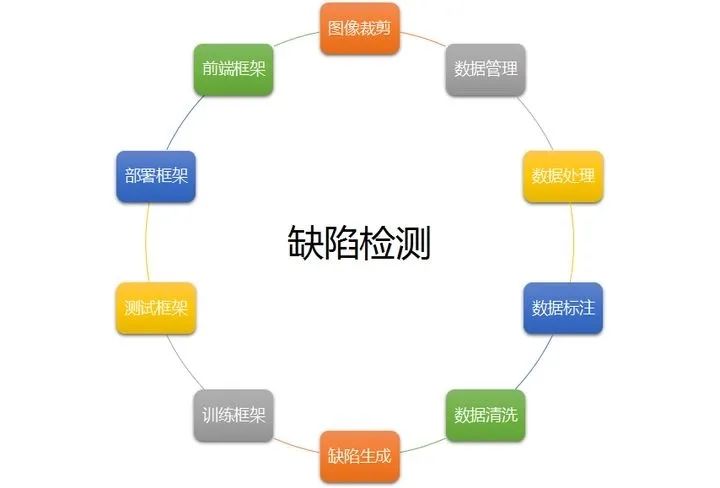
如上图,缺陷检测落地需要非常多的工具支撑:
图像采集:相机、运动设备、光学控制;
数据托管:服务器、数据库、版本管理、数据积累;
数据处理:图像分析、定位、裁剪;
数据标注:适配各种任务、半自动标注;
数据清洗:半自动、交叉验证、一致性分析;
缺陷生成:传统方法、融合、GAN;
训练框架:分类、分割、检测、热图回归等;
测试框架:多模型测试、指标统计、可视化;
部署平台:模型融合、模型加速、平台移植;
前端框架:GUI、数据持续收集、用户体验;
难点:整合散乱的工具,甚至完全交给用户。市面是有很多做自动训练软件的,例如比较知名的VIDI,国内也有AIDI、Alpha等。可能大家选择的模型不是非常先进,但是从标注到训练,再到模型导出,用户体验和跨平台做的比较好。工业场景,特定场景特定算法,工具做好,不必追求SOTA模型,SOTA模型只是提高了自然场景精度的上限,而我们需要把握模型的下限。
(十七)部署
部署没啥可说的,可其他任务没有太大区别,这里列举一些总结的点吧!
部署两大任务:
平台移植
模型加速
模型加速:
模型轻量化:mobilenet, EfficientNet
量化:INT8、INT16、2BIT
剪枝:network-slimming
蒸馏:Knowledge Distillation
部署的两种方式:
服务端:服务器、云端(微信小程序)、工控机
边缘设备:jetson, NPU,rk, arm
常用推理库:
c、c++原生态:darknet
pytorch原生态:libtorch、torch.jit
中间转换:onnxruntime
GPU: tensorRT、onnxruntime-GPU、TVM
CPU: openvino、onnxruntime-CPU
ARM: ncnn TNN MNN等
(十八)技术壁垒
系统工程:硬件、光学、算法、部署,稳定、可靠
数据积累:用户理解、场景理解、数据理解,在专用领域形成数据积累
工具链:可以支撑项目快速落地
成本控制:开发周期、硬件成本、运维成本
所以缺陷检测不单单是一个算法模型的问题,而是整个系统工程。可能不需要非常前言的算法,但是需要成熟的工具链。即便是基础的算法、看似容易的场景,也可以形成技术壁垒。如果想复刻,也没有那么轻松。很多时候,不是不能做,而是值不值得做?
Nothing is impossible, what you want is simply expensive
(十九)总结
场景分散,硬件结构、光学强相关,复刻难度大,高度定制、推广成本高。任务可行性分析,系统工程层面(整套方案、数据)形成技术壁垒;
数据一致性问题:难分、类内差异大、样本不平衡、数据脏等,难以在一个标注测试集上输出比较好的指标。需求理解、数据理解、数据管理;
不需要特别前沿的算法;
问题模型定制、训练技巧、任务拆分;
工具链完善;
最后,缺陷检测都是可以做的。那些非常难的,AI是目前最好的方案。
本文亮点总结
1.缺陷检测没有啥难的,基本上都可以做。那为啥槽点还那么多?很大一部分是AI的槽点,因为目前使用AI来做是主流,或者说只传统方法搞不定的,没办法,只有上AI的方法。
2.数据是有主观的成分在里面:从其光学设计、标准执行等上来说,有很大人为因素。也是上文说的可控。具有很大的操作和设计空间。但是有时还要思考:值不值得做?可能是时间、成本、性价比、大规模推广等方面的原因。当然,大部分场景还是很容易做的,因为在工业领域,至少是受限的和可控的场景。关键要分清主要矛盾和次要矛盾。
努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看