
与时代共振,AI助力工业缺陷检测

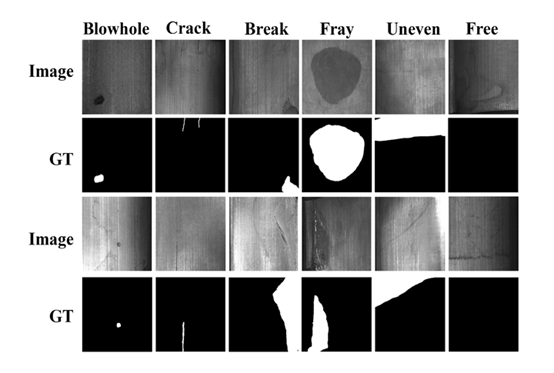
类间差异小,存在模糊地带:以磁瓦缺陷数据集[4]为例,线状物体在多种缺陷或者无缺陷情况都有出现。这是这一数据集的固有属性,也是缺陷检测难做的原因。有一些情况,由于正负样本类内差异小,比如按照面积、灰度值等绘制其直方图,中间过渡区域永远存在一定量的样本,处于灰色地带,很难分辨。 类内差异大:同一类缺陷下,缺陷的大小,形状,位置多变。 样本不平衡:有些数据集中,严重存在着正负样本不平衡的问题,良品多,不良率小。 缺陷级别小:例如在磁瓦缺陷数据集中 ,有些裂痕或者空洞的尺寸很小,对于目标细节的分辨率要求高。

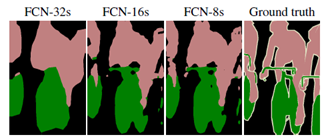

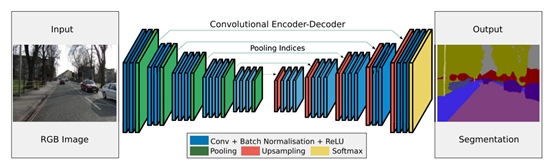
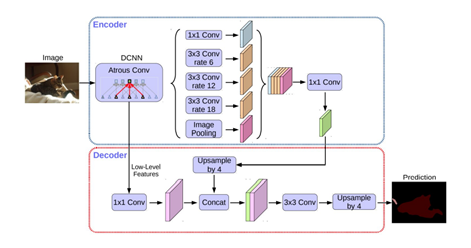
它改善了边界的预测,因为避免了像素位置信息的损失; 它对算力友好,这是由于本身上采样不会参与网络训练; 这种形式的上采样可以合并到任何编码器-解码器结构中。

通道的数量在框的顶部表示。每一层的x-y尺寸在框的左下边缘提供。白框表示复制的特征。箭头表示不同的操作。
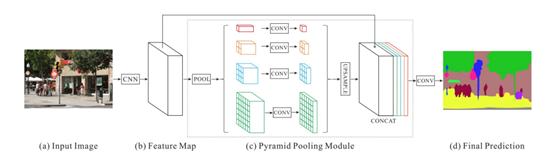
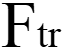 )得到一个大小 (H x W xC) 的特征图U。再经过挤压(
)得到一个大小 (H x W xC) 的特征图U。再经过挤压(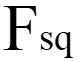 )操作,特征图变成了 1 x 1 x C 的特征向量,特征向量是特征图U在每个通道全局最大池化的结果。经过激活(
)操作,特征图变成了 1 x 1 x C 的特征向量,特征向量是特征图U在每个通道全局最大池化的结果。经过激活(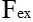 )操作,特征向量的维度没有变,但是向量值变成了新的值。这一步的操作视SEblock的结构而定,常见的有Inception、Resnet等等。这些值通过和U经过尺度变换(
)操作,特征向量的维度没有变,但是向量值变成了新的值。这一步的操作视SEblock的结构而定,常见的有Inception、Resnet等等。这些值通过和U经过尺度变换(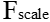 )的值乘积后得到加权的最后结果
)的值乘积后得到加权的最后结果 的维度和特征图U一致。
的维度和特征图U一致。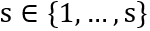 。每个尺度都通过Deeplab(权重值在所有尺度上共享),并生成尺度为s的得分图,表示为
。每个尺度都通过Deeplab(权重值在所有尺度上共享),并生成尺度为s的得分图,表示为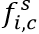 。为了使得不同尺度的得分图具有相同的分辨率,通过双线插差值的办法调整小尺度的得分图。最后通道 c,位置 i 特征图上的值:
。为了使得不同尺度的得分图具有相同的分辨率,通过双线插差值的办法调整小尺度的得分图。最后通道 c,位置 i 特征图上的值: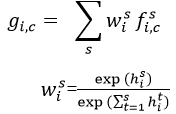
 代表尺度 s 的得分图中位置 i 的得分值。
代表尺度 s 的得分图中位置 i 的得分值。
评论