
Kubernetes 4000节点运维经验分享
在 PayPal,我们最近开始试水 Kubernetes。我们大部分的工作负载都运行在 Apache Mesos 上,而作为迁移的一部分,我们需要从性能方面了解下运行 Kubernetes 集群以及 PayPal 特有的控制平面。其中最主要的是了解平台的可扩展性,以及通过调整集群找出可以改进的地方。
本文最初发布于 PayPal 技术博客。
在 PayPal,我们最近开始试水 Kubernetes。我们大部分的工作负载都运行在 Apache Mesos 上,而作为迁移的一部分,我们需要从性能方面了解下运行 Kubernetes 集群以及 PayPal 特有的控制平面。其中最主要的是了解平台的可扩展性,以及通过调整集群找出可以改进的地方。
与 Apache Mesos 不同的是,前者无需任何修改即可扩展到 10,000 个节点,而扩展 Kubernetes 则非常具有挑战性。Kubernetes 的可扩展性不仅仅体现在节点和 Pod 的数量上,还有其他多个方面,如创建的资源数量、每个 Pod 的容器数量、服务总数和 Pod 部署的吞吐量。本文描述了我们在扩展过程中遇到的一些挑战,以及我们如何解决这些问题。
我们的生产环境中有各种不同规模的集群,包含数千个节点。我们的设置包括三个主节点和一个外部的三节点 etcd 集群,所有这些都运行在谷歌云平台(GCP)上。控制平面前面有一个负载平衡器,所有数据节点都与控制平面属于相同的区域。
为了进行性能测试,我们使用了一个开源的工作负载生成器 k-bench,并针对我们的场景做了修改。我们使用的资源对象是简单的 Pod 和部署。我们按不同的批次大小和部署间隔时间,分批次连续对它们进行部署。
开始时,Pod 和节点数量都比较少。通过压力测试,我们发现可以改进的地方,并继续扩大集群的规模,因为我们观察到性能有所改善。每个工作节点有四个 CPU 内核,最多可容纳 40 个 Pod。我们扩展到大约 4100 个节点。用于基准测试的应用程序是一个无状态的服务,运行在 100 个服务质量(QoS)有保证的毫核(millicores )上。
我们从 1000 个节点、2000 个 Pod 开始,接着是 16000 个 Pod,然后是 32000 个 Pod。之后,我们跃升到 4100 个节点、15 万个 Pod,接着是 20 万个 Pod。我们不得不增加每个节点的核数,以容纳更多的 Pod。
事实证明,API 服务器是一个瓶颈,有几个到 API 服务器的连接返回 504 网关超时,此外还有本地客户端限流(指数退避)。这些问题在扩展过程中 呈指数级 增长:
I0504 17:54:55.731559 1 request.go:655] Throttling request took 1.005397106s, request: POST:https://<>:443/api/v1/namespaces/kbench-deployment-namespace-14/Pods..I0504 17:55:05.741655 1 request.go:655] Throttling request took 7.38390786s, request: POST:https://<>:443/api/v1/namespaces/kbench-deployment-namespace-13/Pods..I0504 17:55:15.749891 1 request.go:655] Throttling request took 13.522138087s, request: POST:https://<>:443/api/v1/namespaces/kbench-deployment-namespace-13/Pods..I0504 17:55:25.759662 1 request.go:655] Throttling request took 19.202229311s, request: POST:https://<>:443/api/v1/namespaces/kbench-deployment-namespace-20/Pods..I0504 17:55:35.760088 1 request.go:655] Throttling request took 25.409325008s, request: POST:https://<>:443/api/v1/namespaces/kbench-deployment-namespace-13/Pods..I0504 17:55:45.769922 1 request.go:655] Throttling request took 31.613720059s, request: POST:https://<>:443/api/v1/namespaces/kbench-deployment-namespace-6/Pods..
API 服务器上限制速率的队列的大小是通过 max-mutating-requests-inflight 和 max-requests-inflight 更新的。1.20 版本中引入的 优先级和公平性 特性测试版,就是在 API 服务器上这两个标记的控制下将队列的总大小在不同的队列类别之间进行划分。例如,群首选举请求的优先级比 Pod 请求高。在每个优先级中,都有可配置队列的公平性。未来还可以通过 PriorityLevelConfiguration&FlowSchema API 对象做进一步调优。
控制器管理器负责为副本集、命名空间等本地资源以及数量众多的部署(由副本集管理)提供控制器。控制器管理器与 API 服务器同步其状态的速度是有限的。有多个调节器用于调整这一行为:
kube-api-qps -- 控制器管理器在一秒钟内可以向 API 服务器进行查询的次数。
kube-api-burst -- 控制器管理器突发流量峰值,是 kube-api-qps 之上另一个并发调用数。
concurrent-deployment-syncs -- 部署、复制集等对象同步调用的并发性。
当作为一个独立的组件单独测试时,调度器可以支持每秒 1000 个 Pod 的高吞吐率。然而,在将调度器部署到一个在线集群中时,我们注意到,实际的吞吐量有所降低。etcd 实例速度慢导致调度器的绑定延迟增加,使得待处理队列的大小增加到数千个 Pod 的程度。我们的想法是在测试运行期间将这个数值保持在 100 以下,因为数量比较大的话会影响 Pod 的启动延迟。此外,我们最后还调整了群首选举参数,以应对短暂的网络分区或网络拥堵引发的虚假重启。
etcd 是 Kubernetes 集群中最关键的一部分。这一点从 etcd 在整个集群中引发的、以不同方式表现出来的大量问题可以看出来。经过非常仔细的研究,我们才找到根本原因,并扩展 etcd 以匹配我们预期的规模。
在扩展过程中,许多 Raft proposal 开始失败:
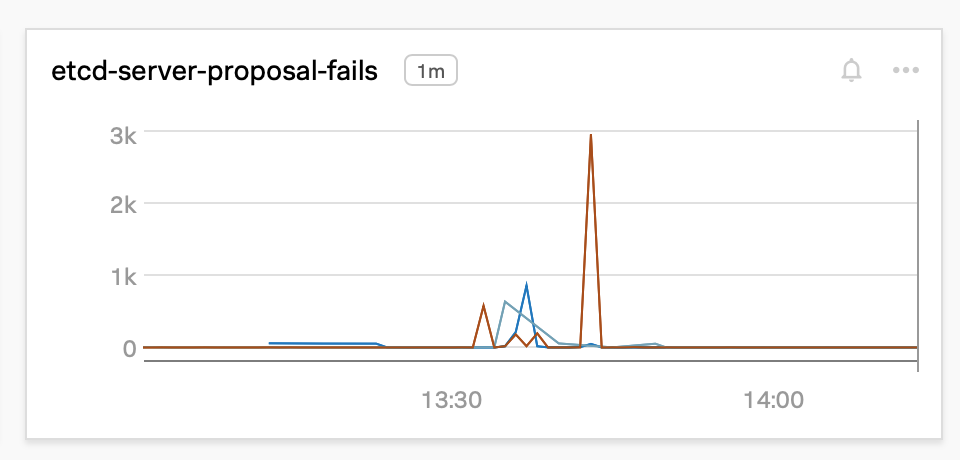
通过调查分析,我们发现,GCP 将 PD-SSD 磁盘的吞吐量限制在每秒 100MB 左右(如下图所示),我们的磁盘大小为 100G。GCP 没有提供增加吞吐量限制的方法——它只 随着磁盘的大小增加。尽管 etcd 节点只需要不到 10G 的空间,我们首先尝试了 1TB PD-SSD。然而,当所有 4k 个节点同时加入 Kubernetes 控制平面时,磁盘再大也会成为一个 瓶颈。我们决定使用本地 SSD,它的吞吐量非常高,代价是在出现故障时丢失数据的几率略高,因为它 不是持久化的。
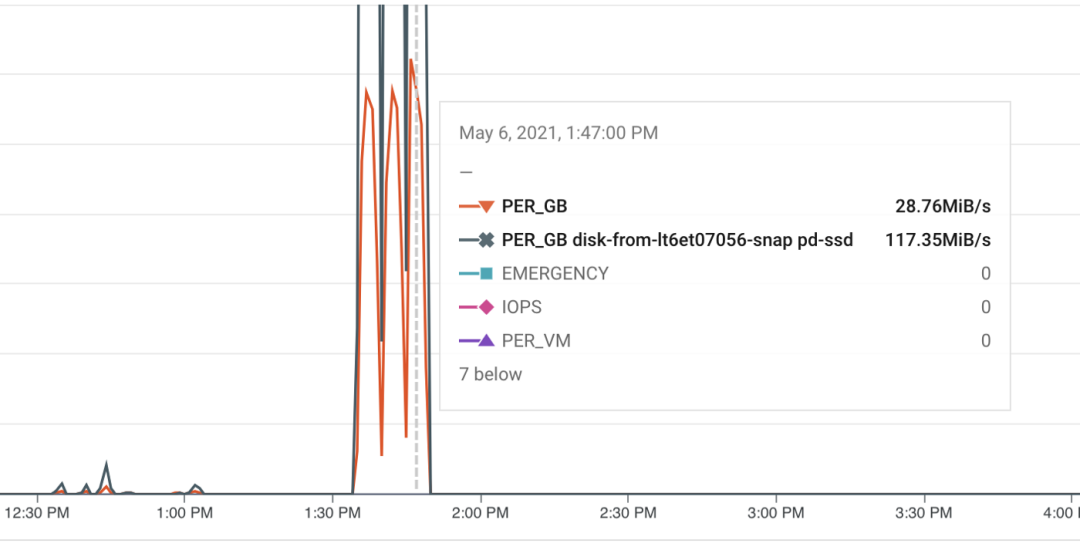
在迁移到本地 SSD 后,我们并没有看到最快的 SSD 带来了预期的性能。我们用 FIO 直接在磁盘上做了一些基准测试,数值在意料之中。但是,对于所有成员的写入并发,etcd 基准测试讲述了一个不同的故事:
Plain TextLOCAL SSDSummary: Total: 8.1841 secs. Slowest: 0.5171 secs. Fastest: 0.0332 secs. Average: 0.0815 secs. Stddev: 0.0259 secs. Requests/sec: 12218.8374PD SSDSummary:Total: 4.6773 secs.Slowest: 0.3412 secs.Fastest: 0.0249 secs.Average: 0.0464 secs.Stddev: 0.0187 secs.: 21379.7235
本地 SSD 的表现更差!经过深入调查,这是由 ext4 文件系统的写屏障缓存提交导致的。由于 etcd 使用写前日志,并在每次提交到 Raft 日志时调用 fsync,所以可以禁用写屏障。此外,我们在文件系统级和应用程序级有 DB 备份作业,用于 DR。在这样修改之后,使用本地 SSD 的数值提高到了与 PD-SSD 相当的程度:
Plain TextLOCAL SSDSummary: Total: 4.1823 secs. Slowest: 0.2182 secs. Fastest: 0.0266 secs. Average: 0.0416 secs. Stddev: 0.0153 secs. Requests/sec: 23910.3658这一改进的效果在 etcd 的 WAL 同步持续时间和后端提交延迟上体现了出来,如下图所示,在 15:55 左右这个时间点上,WAL 同步持续时间和后端提交延迟降低了 90% 以上:
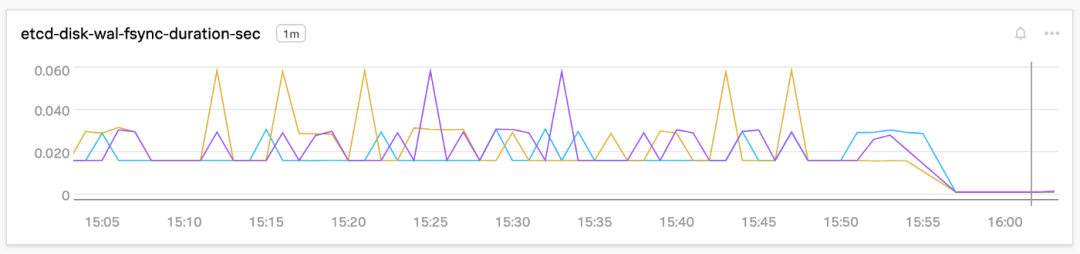
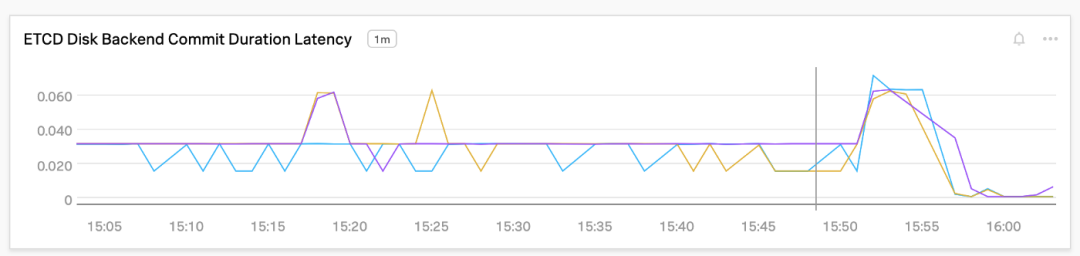
etcd 中默认的 MVCC 数据库大小为 2GB。在 DB 空间不足的告警被触发时,这个大小最大会增加到 8GB。由于该数据库的 利用率约为 60%,所以我们能够扩展到 20 万个无状态 Pod。
经过上述这些优化,在预期的规模下,集群更加稳定了,然而,在 API 延迟方面,我们的 SLI 还差很多。
etcd 服务器还会偶尔重启,仅一次重启就会破坏基准测试结果,尤其是 P99 值。仔细观察发现,v1.20 版的 etcd YAML 中有一个存活探针 Bug。为了解决这个问题,我们采用了一个变通办法,即增加失败阈值的计数。
在用尽所有方法对 etcd 进行了垂直扩展之后,主要是在资源方面(CPU、内存、磁盘),我们发现,etcd 的性能受到范围查询的影响。当范围查询很多时,etcd 的表现并不好,对 Raft 日志的写入也受到影响,增加了集群的延迟。以下是一次测试运行中影响性能的每个 Kubernetes 资源的范围查询的数量:
Plain Textetcd$ sudo grep -ir "events" 0.log.20210525-035918 | wc -l130830etcd$ sudo grep -ir "Pods" 0.log.20210525-035918 | wc -l107737etcd$ sudo grep -ir "configmap" 0.log.20210525-035918 | wc -l86274etcd$ sudo grep -ir "deployments" 0.log.20210525-035918 | wc -l6755etcd$ sudo grep -ir "leases" 0.log.20210525-035918 | wc -l4853etcd$ sudo grep -ir "nodes" 0.log.20210525-035918 | wc -l由于这些查询很耗时,etcd 的后端延迟受到了很大的影响。在事件资源上对 etcd 服务器进行分片管理后,我们看到,在 Pod 高度竞争的情况下,集群的稳定性有所提高。将来,还可以进一步在 Pod 资源上对 etcd 集群进行分片。配置 API 服务器联系相关的 etcd 以与分片的资源进行交互很容易。
在对 Kubernetes 的各种组件做完优化和调整后,我们观察到,延迟有大幅改善。下图展示了随着时间的推移,为满足 SLO 而实现的性能提升。其中,工作负载是 150k 个 Pod,每个部署 250 个副本,10 个并发工作进程。只要 Pod 启动的 P99 延迟在 5 秒之内,按照 Kubernetes SLO,我们就算是很好了。
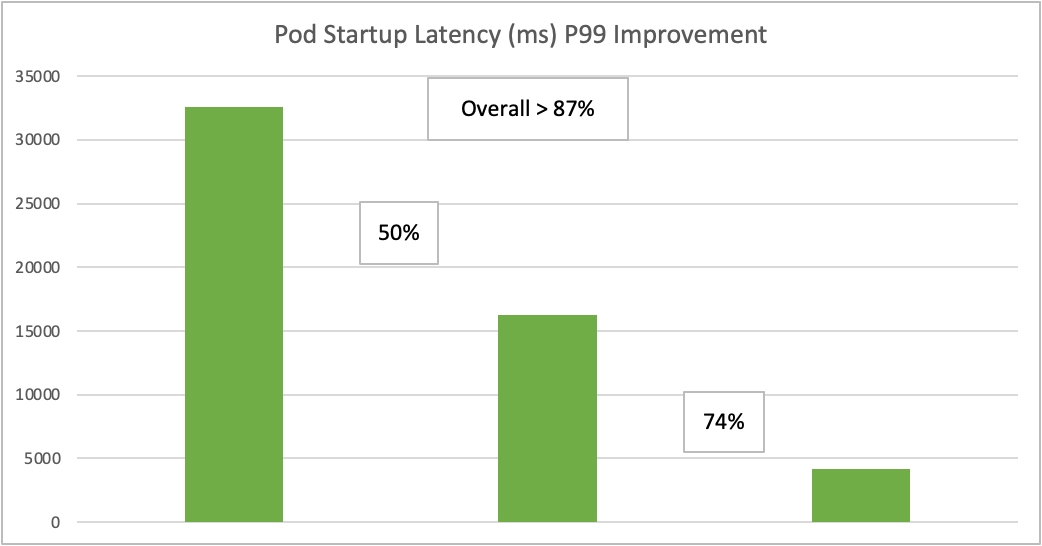
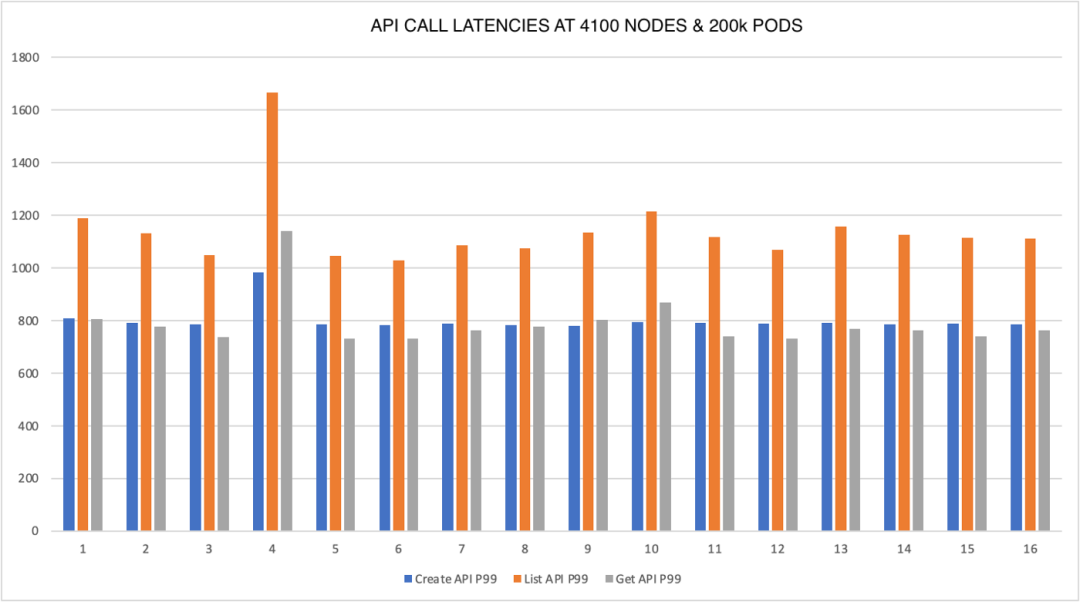
下图显示了当集群有 20 万个 Pod 时,API 调用延迟完全符合 SLO。
_ 我们还实现了 20 万个 Pod P99 启动延迟为 5 秒左右,而 Pod 部署速率远远高于 K8s 针对 5k 节点测试时所声称的 3000 个 Pod/ 分钟。_
Kubernetes 是一个复杂的系统,必须深入了解控制平面,才能知道如何扩展每个组件。通过这次操练,我们学到了很多东西,并将继续优化我们的集群。
- END -
推荐阅读 Kubernetes 生态架构图 基于Nginx实现灰度发布与AB测试 在Kubernetes上部署一套 Redis 集群 Linux 系统日常巡检脚本 K8s kubectl 常用命令总结(建议收藏) 搭建一套完整的企业级 K8s 集群(kubeadm方式)
点亮,服务器三年不宕机

