
Kubernetes master 节点快炸了!!!
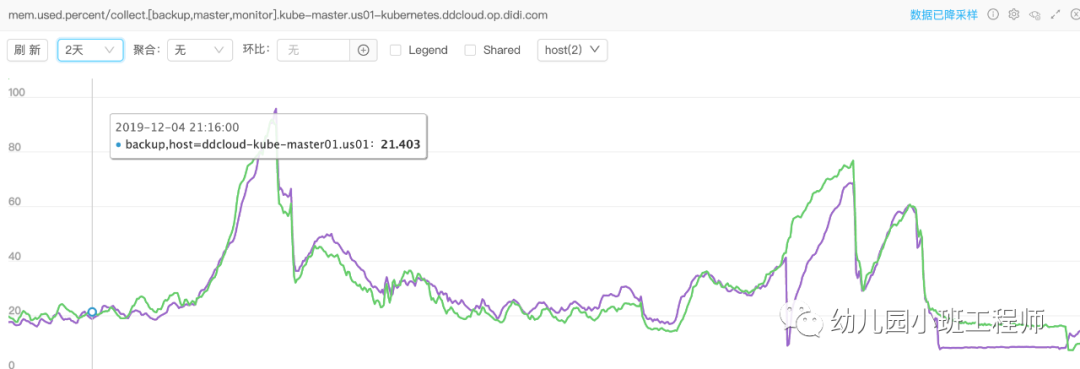
线上 master 的 apiserver 组件内存报警,内存使用量持续增长,监控如下:
排查过程
从监控上看和另外一个程序(管理员平台)的内存使用情况吻合,使用率降下来是因为重启了 apiserver 和管理员平台,且问题只出现在最近两天的晚上,管理员平台中有一段逻辑是定时全量拉取集群数据(设计不合理,后续需要改),管理员平台的日志里显示拉取数据超时,基本猜测和管理员平台调用 k8s api不 合理有关,且 k8s apiserver 应该也有 bug,导致内存泄露或者 goroutine 泄露。但是最近代码都没动过,为啥之前没事呢,后负责管理员平台的同事说近两天美东专线有问题,延迟是之前的3倍,而且出现问题的时间正好匹配,那接下来就查一下具体原因。
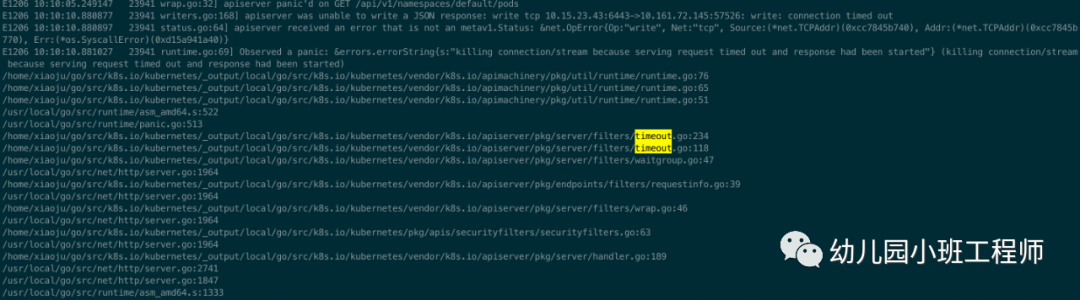
apiserver 错误日志里有大量的上述日志,可以看到是 apiserver 因为响应超时触发的,里面也有详细的函数调用堆栈信息,也有ip的信息,正好对应了 master 和管理员平台的地址,通过 pprof 也可以看到此时的 goroutine 使用量一直在增加,已45000+,确认是产生了 goroutine 泄露。下图为 pprof tree 看到的部分内容,里面显示了占用量最多的地方

同时在浏览器中访问 http://ip:port/debug/pprof/goroutine 可以看到具体 goroutine 数量和执行函数的行号,此处忘记截图了,不过和上面的信息吻合,且更信息因为携带了行号的信息,可以看到是如下代码出的问题(代码版本1.12.4)
// k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/server/filters/timeout.go
func (t *timeoutHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
r, after, postTimeoutFn, err := t.timeout(r)
if after == nil {
t.handler.ServeHTTP(w, r)
return
}
errCh := make(chan interface{})
tw := newTimeoutWriter(w)
go func() {
defer func() {
err := recover()
if err != nil {
const size = 64 << 10
buf := make([]byte, size)
buf = buf[:runtime.Stack(buf, false)]
err = fmt.Sprintf("%v\n%s", err, buf)
}
errCh <- err
}()
t.handler.ServeHTTP(tw, r)
}()
select {
case err := <-errCh:
if err != nil {
panic(err)
}
return
case <-after:
postTimeoutFn()
tw.timeout(err)
}
}
泄露的 goroutine 就是第11行处的,简单解释一下上面的逻辑:生成一个 timeout 的 handler,起一个新的 goroutine 进行后续 handler 的处理,当前 goroutine 中使用 select 进行等待,分为两种 case,分别对应新 goroutine 中 panic 的情况和整个函数超时的情况,分别看两个 case 的内容:
第25行:从 errCh 读取数据,其中 errCh 中的数据是在新的 goroutine 中产生的,对应到实际情况就是22行的代码出发生了 panic,在13行捕获到了,最后在20行把 err 写入到 errCh 中,但是这里需要注意一下这个 errCh 是个无缓存的。
第30行:after 是调用 time.After 后产生的一个 chan,在超时后可以从这个 chan 中获取到数据,然后在32行处会调用 tw.timeout 函数,里面会触发 panic。
那为什么 goroutine 泄露了呢?
问题就出现在了刚才提到的无缓冲的 errCh 上,因为触发了 timeout,代码逻辑没有执行到25行,直接去了30行,然后整个函数 panic,导致20行执行的时候卡住了,从而阻止了11行出的新的 goroutine 的退出,每有一个 timeout 的请求,这里就会泄露一个 goroutine,从而导致内存随之泄露,cpu 的话其实不受什么影响,因为泄露的 goroutine 已经执行过 gopark,不是 runnable 状态的。
解决方案
印象中记得之前看 k8s 版本升级的 release-note 时有提到过修复 apiserver leak 字样的信息,然后就去官方项目中查,结果没找到,然后直接去看了对应文件的最新版本代码,看 history,终于找到了相关的修复的 commit,合入1.17。
case <-after:
defer func() {
// resultCh needs to have a reader, since the function doing
// the work needs to send to it. This is defer'd to ensure it runs
// ever if the post timeout work itself panics.
go func() {
res := <-resultCh
if res != nil {
switch t := res.(type) {
case error:
utilruntime.HandleError(t)
default:
utilruntime.HandleError(fmt.Errorf("%v", res))
}
}
}()
}()
postTimeoutFn()
tw.timeout(err)
可以看到其思想就是在外层 panic 后,新加一个 defer func 用来从之前的 errCh(新版改名为 resultCh)接收数据,从而避免之前的问题。
总结
通过如上修改,确实可以解决 goroutine 泄露的问题,但是也存在一个隐患:第6行新加的 goroutine 会从 resultCh 读数据,因为在上一段代码处有个处理,无论是否 panic,都会往 errCh(resultCh)写入 err,从而可以避免同时泄露两个 goroutine 的情况,但是如果短时间内大量请求到来且处理时间都比较慢直至超时,虽然 goroutine 不会泄露,但是会产生两倍于之前的 goroutine ,可能会在短时间内造成内存暴涨,也算是一个稳定性风险,需要合理设置限流来降低风险。
K8S 进阶训练营

 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习