
Kubernetes 核心组件原理梳理,运维必备~

1. 核心组件原理 —— pod 核心原理
1.1 pod 是什么
pod 也可以理解是一个容器,装的是 docker 创建的容器,也就是用来封装容器的一个容器;
pod 是一个虚拟化分组, 有自己的 IP 地址和主机名 hostname,利用 namespace 进行资源隔离,相当于一台独立沙箱环境;
pod 相当于一台独立主机,内部可以封装一个或多个容器(通常是一组相关的容器),内部容器之间访问采用 localhost。
1.2 pod 用来干什么
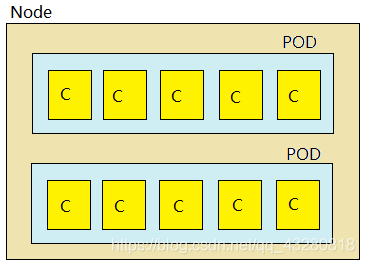
如何理解一组相关的服务?
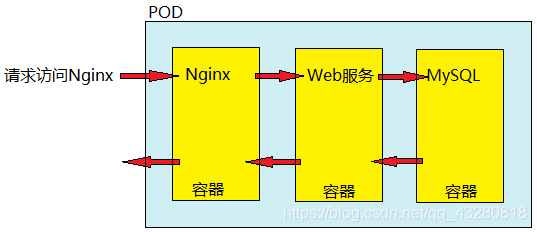
1.3 实现 web 服务集群

1.4 pod 底层网络和数据存储是如何进行的
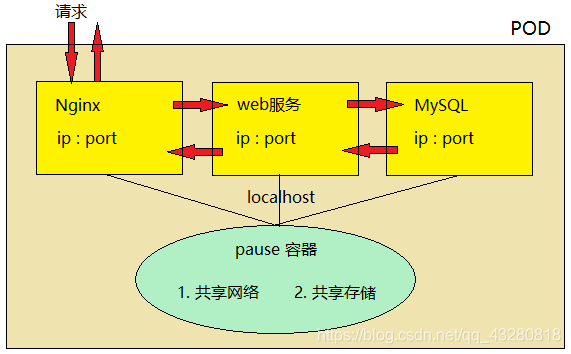
pod 底层
pod 内部容器创建之前,必须先创建 pause 容器。pause 有两个作用:共享网络和共享存储。
每个服务容器共享 pause 存储,不需要自己存储数据,都交给 pause维护。
pause 也相当于这三个容器的网卡,因此他们之间的访问可以通过 localhost 方式访问,相当于访问本地服务一样,性能非常高(就像本地几台虚拟机之间可以 ping 通)。
2. ReplicaSet 副本控制器
2.1 副本控制器基本理解
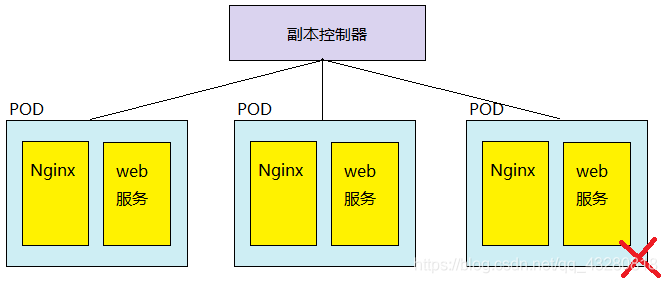
2.2 ReplicaSet 和 ReplicationController 的区别
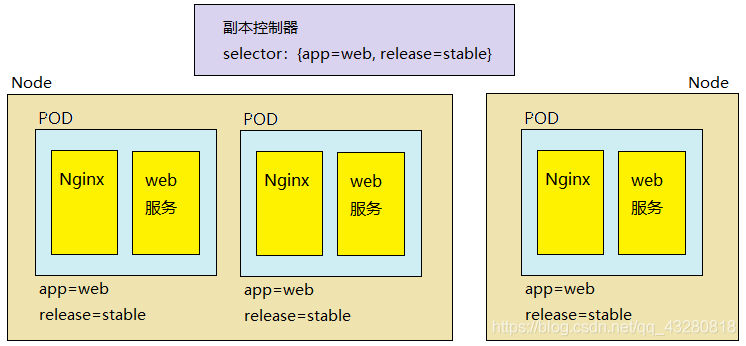
ReplicaSet 和 ReplicationController 都是副本控制器,其中:
相同点:都有前面 2.1 节所描述的功能 不同点:标签选择器的功能不同。ReplicaSet 可以使用标签选择器进行 单选 和 复合选择;而 ReplicationController 只支持 单选操作。
什么意思呢?
假设下面有下面两个不同机器上的 Node 结点,如何知道它们的 pod 其实都是相同的呢?答案是通过标签。
3. Deployment 部署对象
3.1 滚动更新

那是如何滚动更新的呢?涉及到下面要讲到的部署模型。
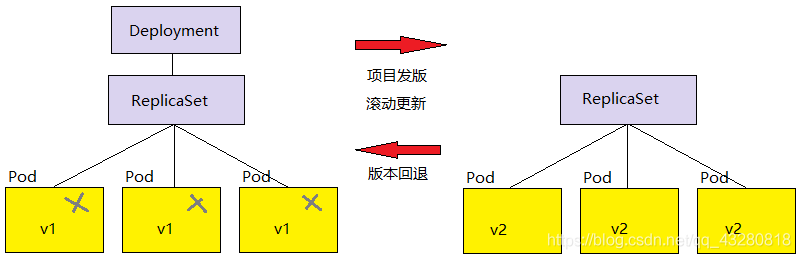
3.2 部署模型
单独的 ReplicaSet 是不支持滚动更新的,Deployment 对象支持滚动更新,通常和 ReplicaSet 一起使用。
需要滚动更新时的步骤:
Deployment 建立新的 Replicaset
Replicaset 重新建立新的 pod
4. StatefulSet 部署有状态服务
4.1 引入定义
容器都是有生命周期的,一旦宕机数据就很可能丢失 pod 也有生命周期的,用 pod 部署时把 pod 集群副本重启以后也可能会出现数据丢失
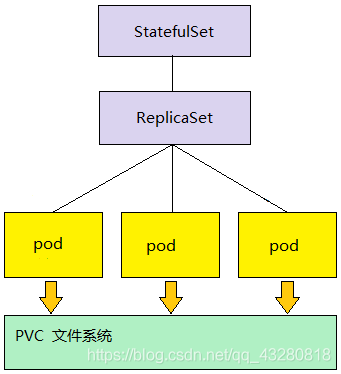
4.2 如何理解状态服务
有状态服务 有实时的数据需要存储 在有状态服务集群中,如果把某一个服务抽离出来,一段时间后再加入回集群网络,此后集群网络会无法使用 无状态服务 没有实时的数据需要存储 在无状态服务集群中,如果把某一个服务抽离出去,一段时间后再加入回集群网络,对集群服务无任何影响,因为它们不需要做交互,不需要数据同步等等。
4.3 部署模型
原文链接:https://blog.csdn.net/qq_43280818/article/details/106910187
往期推荐
有收获,点个在看

评论