
拒绝遗忘:高效的动态规划算法
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

来自 | medium
作者 | Meet Zaveri
乔治·桑塔亚纳说过,“那些遗忘过去的人注定要重蹈覆辙。”这句话放在问题求解过程中也同样适用。不懂动态规划的人会在解决过的问题上再次浪费时间,懂的人则会事半功倍。那么什么是动态规划?这种算法有何神奇之处?本文作者给出了初步的解答。
假设你正在使用适当的输入数据进行一些计算。你在每个实例中都进行了一些计算,以便得到一些结果。当你提供相同的输入时,你不知道会有相同的输出。这就像你在重新计算之前已经计算好的特定结果一样。
那么问题出在哪里呢?你之前计算某些结果的宝贵时间被浪费掉了。你可以通过保存之前的计算结果去轻易地解决这个问题。比如通过使用恰当的数据结构。举个例子,你可以将输入输出作为键值对映射保存起来。
那些遗忘过去的人注定要重蹈覆辙 ~ 动态规划
现在通过分析这个问题,我们可以将新的输入(或者不在数据结构中的输入)与其对应的输出存储下来。或者在字典中查找输入并返回相应的输出结果。这样当你在进行一些计算时,你可以检查数据结构中是否存在该输入,如果数据输入存在的话就可以直接获得结果。我们将与这种方法相关的技巧称作动态规划。
现在让我们更详细地介绍动态规划。
简而言之,我们可以说动态规划主要用来解决一些希望找到问题最优解的优化问题。
一种可以用动态规划解决的情况就是会有反复出现的子问题,然后这些子问题还会包含更小的子问题。相比于不断尝试去解决这些反复出现的子问题,动态规划会尝试一次解决更小的子问题。之后我们可以将结果输出记录在表格中,我们在之后的计算中可以把这些记录作为问题的原始解。
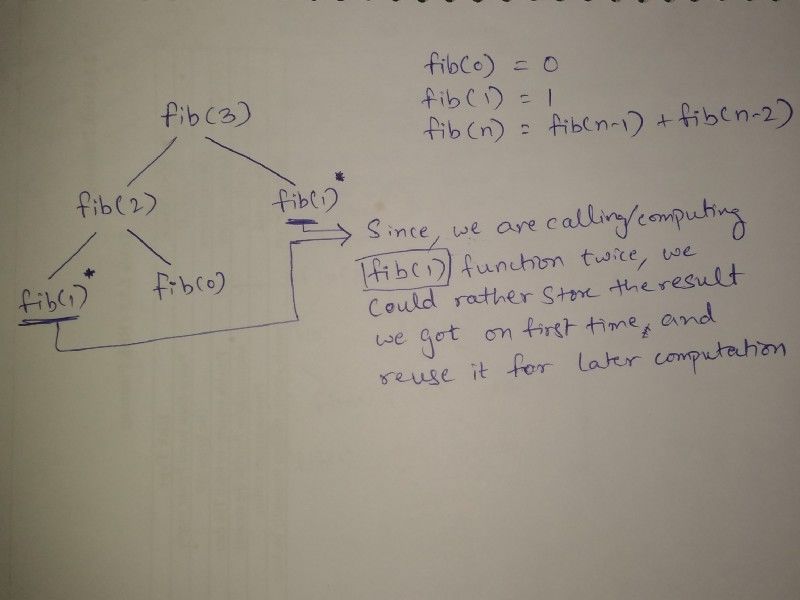
举个例子,斐波那契数列 0,1,1,2,3,5,8,13,…有着一个相当简单的描述方式,它的每个数字都与前两个紧邻的数字相关。如果 F(n) 是第 n 个数字,那么我们会有 F(n) = F(n-1) + F(n-2)。这个在数学上称作*递归方程*或者*递推关系*。为了计算后面的项,它需要前面项的计算结果作为输入。
大多数动态规划问题都能被归类成两种类型:
优化问题
组合问题
优化问题希望你选择一个可行的解决方案,以便最小化或最大化所需函数的值。组合问题希望你弄清楚做某事方案的数量或某些事件发生的概率。
以下是两种不同的动态规划解决方案:
自上而下:你从最顶端开始不断地分解问题,直到你看到问题已经分解到最小并已得到解决,之后只用返回保存的答案即可。这叫做记忆存储(*Memoization*)。
自下而上:你可以直接开始解决较小的子问题,从而获得最好的解决方案。在此过程中,你需要保证在解决问题之前先解决子问题。这可以称为表格填充算法(*Tabulation,*table-filling algorithm**)。
至于迭代和递归与这两种方法的关系,自下而上用到了迭代技术,而自上而下则用到了递归技术。

图片中的展示在理论上可能并不完全正确,但这是一种可以理解的展示方式。
这儿有一个普通方法和动态规划方法的比较,你可以看到两者时间复杂度的不同。
Jeff Erickson 在他的笔记中这样描述斐波那契数列:
递归算法之所以速度慢,是因为它一遍又一遍地计算了相同的斐波那契数列。

来自 Jeff Erickson 笔记:http://jeffe.cs.illinois.edu/
我们可以通过记录递归调用的结果来加速递归算法,这样在之后需要这些结果时就不必重新计算了。
Memoization 是指缓存和重用之前计算结果的技术。
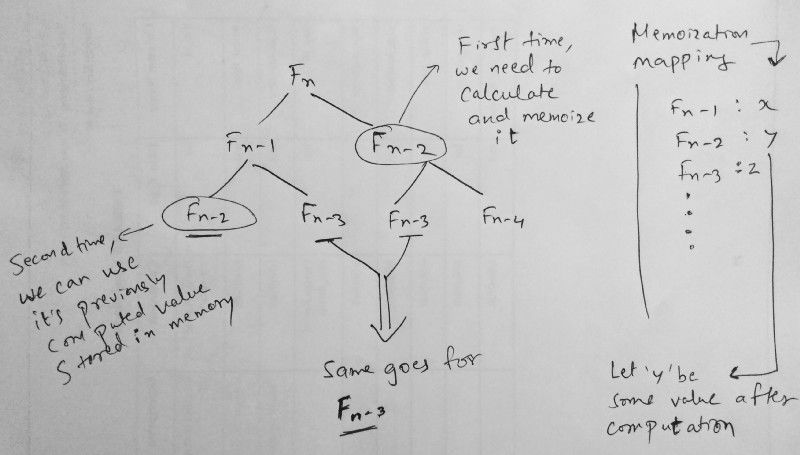
如果你使用 Memoization 来解决问题,可以通过维护已经解决的子问题的映射来实现(正如我们之前讨论的键值对映射)。你首先解决「上层」问题(通常是为了解决子问题而进行递归),这样做是「自上而下」。
*memoization*的伪代码

因此在使用递归的过程中,我们使用额外的内存(即这里的 lookup)来执行操作以存储结果。如果查找命中存储值,我们将直接返回它,或者将其添加到特定索引。
请记住,额外的内存与表格填充之间存在一个权衡。
自上而下的方法
Tabulation:以表格形式填充
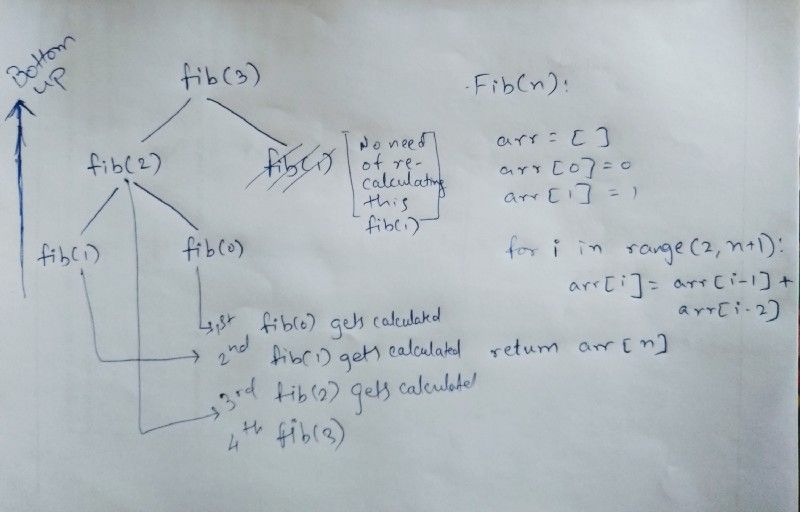
但是一旦我们看到数组(存储的解决方案)是如何被填充的,我们就可以用一个简单的循环替换递归,这个循环有意地按顺序填充数组,而不是依赖于复杂的递归来为我们完成。

来自 Jeff Erickson 的笔记:http://jeffe.cs.illinois.edu/
Tabulation 以「*自下而上*」的方式进行。它更直接,会计算所有值,但需要的开销更少,因为它不必维护映射并以表格形式为每个值存储数据。它还可以计算不必要的值。如果你只想计算问题的所有值,则可以使用此方法。
*tabulation*的伪代码:
斐波那契树的伪代码
正如您可以在图片中看到的伪代码(右侧),它会进行迭代(即循环直到数组结束)。它从 fib(0),fib(1),fib(2),…开始,所以使用 tabulation 方法,我们可以消除递归,只需通过循环元素返回结果。
Richard bellman 是这个概念的提出者。他在 20 世纪 50 年代中期为兰德公司工作时想到了这一点。选择「dynamic programming」这个名字的原因是为了隐藏他为这项研究所做的数学工作。因为他担心他的老板会反对或不喜欢任何类型的数学研究。
所以「programming」这个词只是一个参考,以表明这是一种老式的计划或调度方式,通常是通过逐渐填充表格(以动态方式而不是线性方式)而不是一次全部填入的方式进行。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~