
七夕将至, RFM数据分析法帮你分析男朋友值不值得嫁
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

一、写在前面
马上就要到七夕了, 本来我是准备写RFM分析方法在互联网产品中是如何帮助我们进行用户分群的, 但可能比较无聊, 就借这个节日分享一下这个方法怎么在生活中的应用。
大家可以将这个方法学会了以后再运用的各自的行业中, 无论你是互联网, 还是零售, 还是电商, 只要涉及到用户分群, 都可以用这个方法, 这个方法当时我朋友用一顿烤肉收买我, 我都没有告诉她
二、分析思路
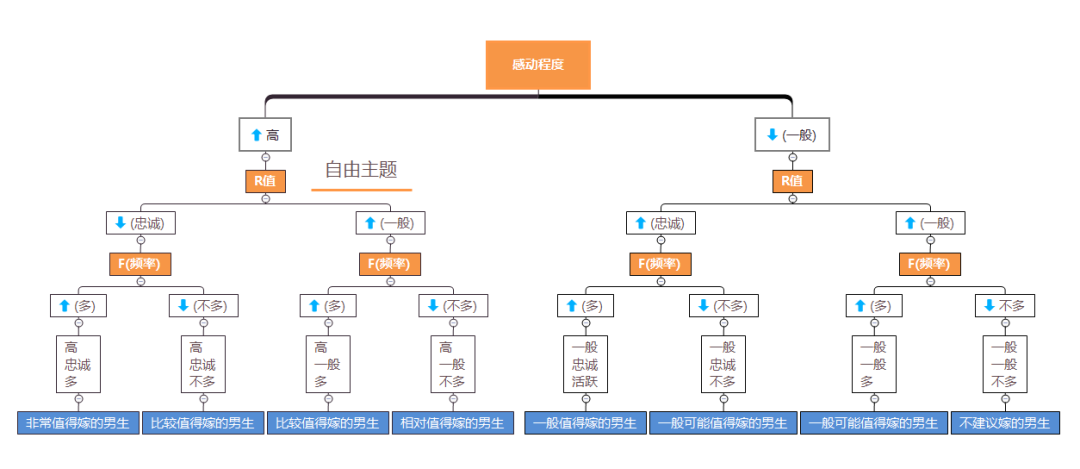
因为从男生的视角来说, 决定一个男生该不该嫁主要可以把这个男生划分成靠谱细心程度和令你感动以及喜欢的程度, 如果这个男生靠谱程度高, 感动程度高, 令你心动喜欢的程度高, 那肯定非嫁不可了 。
。
但就是这种男生非常少, 大多数可能就是这几个特质只符合几个, 比如可能没那么靠谱细心但你很喜欢(颜值很高?), 又或者只是靠谱细心但还没有心动的感觉, 这时候就要去分析到底你的男朋友是属于在哪一个层次, 也就决定了你要不要嫁。
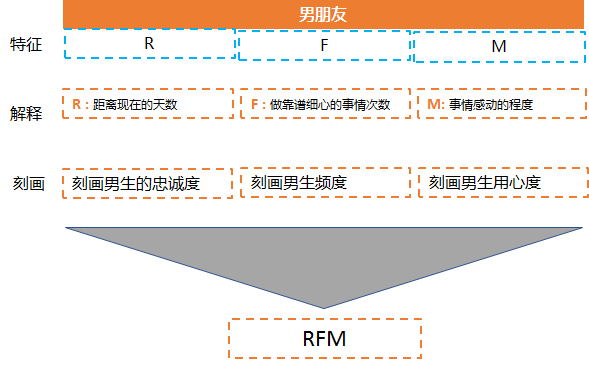
首先我们需要知道这里的 RFM 中的 R, F,M 分别值得是什么。
R 就是男生做的让你感觉到靠谱细心的事情的日期距离现在的天数, 比如他在8.20 那一天凌晨1点给你买了一个冰可乐距离现在是4天, R 就是4。
F就是男生在一段时间内做的让你感觉到靠谱细心的事情的频次, 比如一个月做了五次 和 一次 是肯定不一样的, F 就是frequency 频次.
M 就是做的这些事情每一件事情中让你感动喜欢的程度, 比如同样做靠谱细心的事情, 但是你感动的程度不一样, 给你拧开瓶盖肯定是没有深夜帮你买冰可乐来的感动吧 。
。
如下图所示
根据这个模型的框架, 我们就可以对你的男朋友进行嫁的的程度进行划分, 如下图所示
三、分析过程
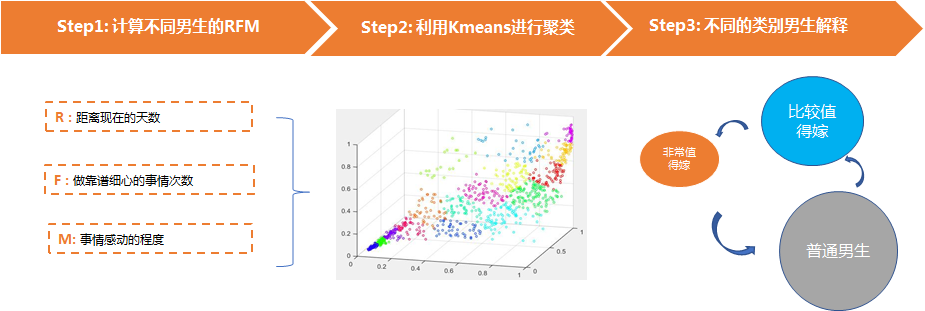
首先我们会计算不同的男生的 R, F, M 这三个指标, 得到每一个男生的这三个数据。
然后利用kmeans 的计算方法, 把R,F, M 放进模型中进行聚类, 模型就会根据每个人的特征, 把他们分到对应的群体中去。
3. 当知道你们的男朋友属于哪一个群体中去了的时候, 比如属于非常值得嫁的那一个群体, 或者属于不太值得嫁的那一个群体, 我们可以做下一步的分析, 非常值得嫁的这一部分群体, 他们都有什么样的特点。
比如 都是生长在背景良好的家庭里, 受过良好的教育, 颜值一般等特点, 而不值得嫁的那一部分群体可能就是生长在一般的家庭, 喜欢去玩, 换女朋友速度很快等等
四、分析结果和分析
将R, F, M 三个特征 利用kmeans 聚类的方法就可以把男生聚成八个类别,
以下是对应的不同的类别的解读

当我们通过聚类的方法将每一种类别的用户进行很好的分层了以后, 属于叫做建模分层的过程, 那么我们需要对每一个不同类型的用户进行特点的刻画。
一般我们会分析他们的年龄, 好友的个数, 地域, 家庭背景, 学历, 教育背景等静态属性的数据, 去帮我们完整的去刻画一个人。
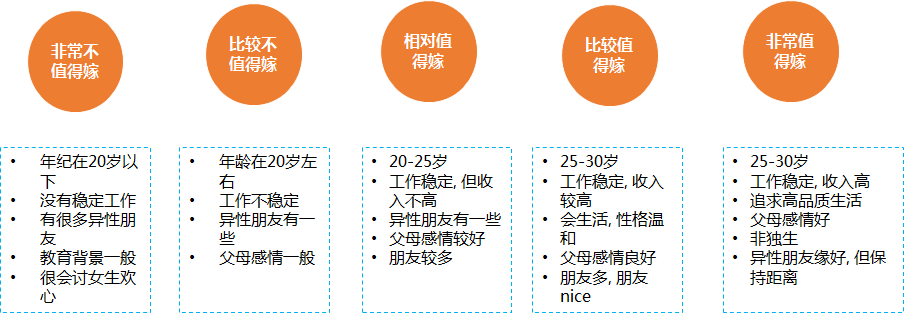
当我们做完对男生的特点分析的时候, 就会对每一个群体有一个清晰的认识, oh 原来好男人值得嫁的男人有这些XXX的特点 。
。
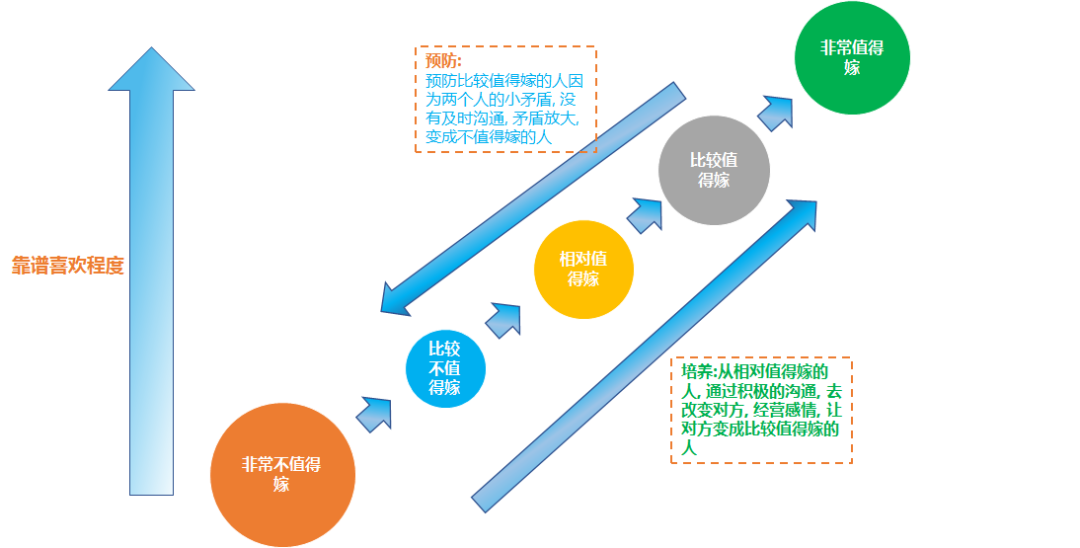
在现实生活中, 假如你的男朋友已经是适合嫁的人, 你就要预防因为一些很小的矛盾, 矛盾没有及时沟通, 从而矛盾无限放大, 变成不值得嫁的人。
同时你也要做好培养, 男生是一个成长的过程, 可能你的男朋友现在是相对值得嫁的类型, 可能当你们好好经营感情的时候比如打卡情侣应该做的100件事情等等, 遇到事情多沟通 有同理心, 多为对方着想, 慢慢的 你的男朋友可能就会变成比较值得嫁的类型, 然后再变成非常值得嫁的类型, 如下图所示。
附录RFM实现的代码
: pay_datauser r_c f_c m_c7688 0.000000 0.008763 7.275781e-0420037 0.566667 0.000250 7.450600e-0530010 0.066667 0.002253 3.689527e-0441232 1.000000 0.000000 2.108058e-0653165 1.000000 0.000000 1.916416e-07放进模型数据集的名字:pay_RFMr_c f_c m_c0.008763 7.275781e-040.000250 7.450600e-050.002253 3.689527e-041.000000 0.000000 2.108058e-061.000000 0.000000 1.916416e-07# 从pay_data 中抽取 r_c, f_c, m_c 三个特征的数据pay_RFM = pay_data[['r_c','f_c','m_c']]# 开始聚类# 选出K,利用拐点from sklearn.cluster import KMeansem=[]ks=range(1,10)for k in ks:kc=KMeans(n_clusters=k, random_state=1)kc.fit(pay_RFM)em.append(kc.inertia_)plt.plot(ks,em)# 进行聚类model_k = KMeans(n_clusters=8,random_state=1)model_k.fit(pay_RFM)= model_k.labels_# 每个类别的进行计算类别的个数, 每个类别的均值, 最小, 最大值rfm_kmeans = pay_RFM.assign(class1=cluster_labels)num_agg = {'r_c':['mean', 'count','min','max'], 'f_c':['mean', 'count','min','max'],'m_c':['mean','sum','count','min','max']}rfm_kmeans.groupby('class1').agg(num_agg).round(2)# 将聚类的结果写入到文档中, 为了得到每一个user 对应的类别=cluster_labels).to_csv('d:/My Documents/Desktop/result.csv',header=True, sep=',')# finish