数据分析方法和思维—RFM用户分群

01
在运营场景中, 经常需要对用户进行分层, 把整体的用户分层不同的层次的用户, 然后针对不同层次的用户采取不同的运营策略, 也被称作精细化运营。但是如何运用科学的方法对用户进行划分呢。
经常遇到的例子是这样的, 比如针对抖音的打赏的用户, 把这些用户按照不同的价值度进行划分, 然后针对不同价值的用户发放不同的优惠套路, 比如充值多少优惠多少
经常产品就会按照单一的月付费次数规则去划分, 比如如下, 我们就可以得到三种不同价值的用户, 这种划分的方法简单来看是没有大问题的, 但是对于数据分析师来说并不是科学的方法。
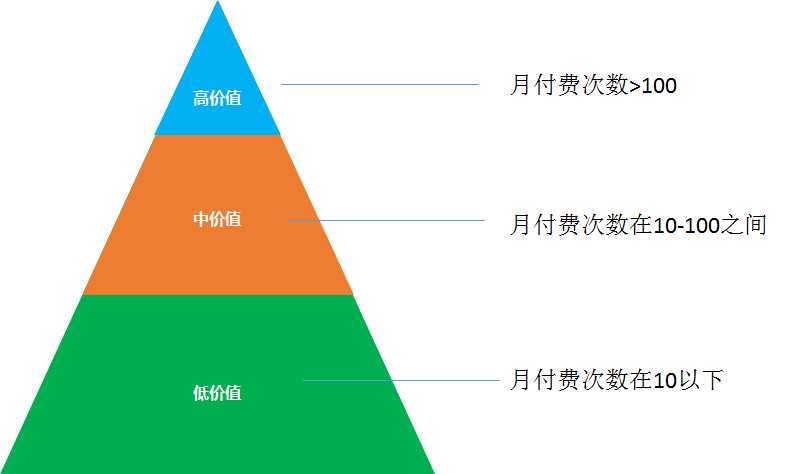
主要的缺点有两个, 首先是只用单一的付费次数来衡量用户的价值度, 没有考虑用户的付费金额, 一个用户假如付费的次数很频繁, 但付费的金额小, 那么他的价值度可能不如另外一个用户付费次数小于他的 但付费金额比他高很多。
另外人为定的划分的标准比如用付费次数 10, 100作为两个划分的临界点, 没有科学性, 很容易分出来的几乎绝大多数都变成高价值的用户, 这样肯定是不合理的。
一般来说, 肯定是高价值的用户的数量远远小于低价值的用户, 但这种数量是跟我们划分的标准紧密相关的, 不同的人定的划分的数值标准是不一样的, 那么定出来的高价值和低价值的差别就会较大, 所以我们需要去用一种科学的, 通用的划分方法去做用户分群。
而RFM作为用户价值的划分的经典模型, 就可以解决这种分群的问题。
02
什么是RFM
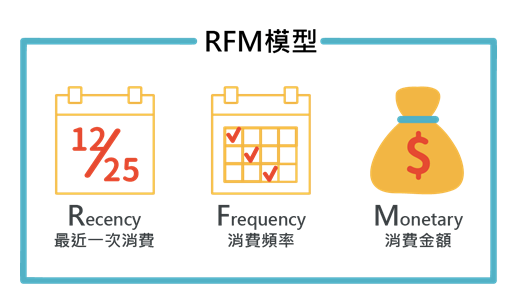
RFM 模型是利用 R, F, M 三个特征去对用户进行划分的。
其中R是表示最后一次付费的日期距离现在的时间, 比如你在 12月20号给一个主播打赏过, 那么到现在的距离的天数是5 那么R就是5, R是用来刻画用户的忠诚度, 一般来说R越小, 代表用户上一次刚刚才付费的, 这种用户的忠诚度比较高。
F是表示一段时间的付费频次, 也就是比如一个月付费了多少次, 这个是用来刻画用户付费行为的活跃度, 我们认为用户的付费行为频次越高, 一定程度上代表他的价值度
M是表示一段时间的付费金额, 比如一个月付费了10000元, M=10000, M主要是用来刻画用户的土豪程度。
以上我们就从用户的忠诚度, 活跃度, 土豪度三个方面去刻画一个用户的价值度。
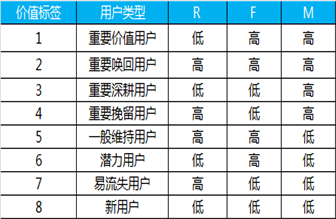
根据RFM的值, 我们就可以把用户划分为以下不同的类别:
重要价值用户: R 低, F 高, M 高, 这种用户价值度非常高, 因为忠诚度高, 付费频次高, 又很土豪
重要召回用户: R 低, F 低 M 高, 因为付费频次低, 但金额高, 所以是重点召回用户
重要发展用户: R 高, F 低, M 高 因为忠诚度不够, 所以需要大力发展
重要挽留用户: R 高 F 低 M高 因为 忠诚度和活跃度都不够 很容易流失 所以需要重点挽留
还有四种其他用户就不一一列举
03
RFM如何进行用户分群
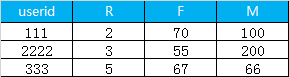
1.首先是利用sql 计算 每一个用户的 R, F, M, 最终得到的数据格式如下
2. 读取数据和查看数据
pay_data= pd.read_csv('d:/My Documents/Desktop/train_pay.csv')# 路径名 'd:/My Documents/Desktop/train_pay.csv' 填写你自己的即可pay_data.head() # 查看数据前面几行
3. 选取我们要聚类的特征
pay_RFM = pay_data[['r_c','f_c','m_c']]4. 开始聚类, 因为我们用户分群分的是八个类别, 所以k =8
# 创建模型model_k = KMeans(n_clusters=8,random_state=1)# 模型训练model_k.fit(pay_RFM)# 聚类出来的类别赋值给新的变量 cluster_labelscluster_labels = model_k.labels_
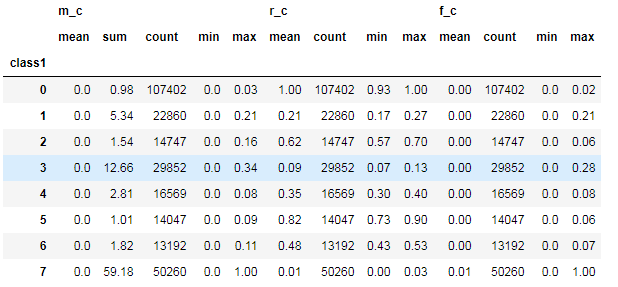
5. 对聚类的结果中每一个类别计算 每个类别的数量 最小值 最大值 平均值等指标
rfm_kmeans = pay_RFM.assign(class1=cluster_labels)num_agg = {'r_c':['mean', 'count','min','max'], 'f_c':['mean', 'count','min','max'],'m_c':['mean','sum','count','min','max']}rfm_kmeans.groupby('class1').agg(num_agg).round(2)
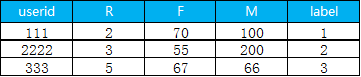
6. 把聚类出来的类别和用户id 拼接在一起
pay_data.assign(class1=cluster_labels).to_csv('d:/My Documents/Desktop/result.csv',header=True, sep=',')下面就是最终结果, label 表示用户是属于哪一个细分的类别
04
RFM模型的应用
重要价值客户:占比11.7%,处于正常水平,RFM都很大,对这部分优质客户要特殊保护
重要唤回客户:占比13.28%,交易金额和次数多,但最近无交易,需要运营/业务人员对其进行唤回(可用红包、奖励、优惠券等方式)
重要深耕客户:占比16.12%,该类客户占比最多,近期有交易且平均交易金额也多,交易频次低,所以需要对其识别后进行个性化推荐,增加用户付费次数,提高粘性
重要挽留客户:占比9.02%,该类客户占比最少,交易金额多于平均值,其付费能力较强,但最近无消费、消费频率低,可能是我们的潜在客户或易流失客户,可以找到该部分用户让其给出反馈建议等
潜力客户:占比11.11%,交易次数多近期也有消费,但整体消费金额低,可能是对价格较敏感或付费能力不足,可对该部分用户进行商品关联推荐
新客户:占比14.79%,最近有消费,交易频率和金额也不高,可对该部分用户增加关怀,推送优惠信息,增加粘性
一般维持客户:占比13.7%,累计单数高,近期无消费,交易金额不高,该部分客户可能快要流失,可低成本营销
流失客户:占比10.28%,三项指标均低于平均值,已经流失,有可能不是目标客户,若经费有限可忽略此类用户
文章点赞超过100+
我将在个人视频号直播(老表Max)
带大家一起进行项目实战复现
扫码即可加我微信
老表朋友圈经常有赠书/红包福利活动
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了 “点赞”就是对博主最大的支持