
【精选】数据分析方法论——相关性分析法
01
在数据分析的问题中, 经常会遇见的一种问题就是相关的问题, 比如抖音短视频的产品经理经常要来问留存(是否留下来)和观看时长, 收藏的次数, 转发的次数, 关注的抖音博主数等等是否有相关性, 相关性有多大。
因为只有知道了哪些因素和留存比较相关, 才知道怎么去优化从产品的方向去提升留存率, 比如 如果留存和收藏的相关性比较大 那么我们就要引导用户去收藏视频, 从而提升相关的指标,
除了留存的相关性计算的问题, 还有类似的需要去计算相关性的问题, 比如淘宝的用户 他们的付费行为和哪些行为相关, 相关性有多大, 这样我们就可以挖掘出用户付费的关键行为
这种问题就是相关性量化, 我们要找到一种科学的方法去计算这些因素和留存的相关性的大小,
这种方法就是相关性分析
02
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析(官方定义)
简单来说, 相关性的方法主要用来分析两个东西他们之间的相关性大小
相关性大小用相关系数r来描述,关于r的解读:(从知乎摘录的)
(1)正相关:如果x,y变化的方向一致,如身高与体重的关系,r>0;一般地,
·|r|>0.95 存在显著性相关;
·|r|≥0.8 高度相关;
·0.5≤|r|<0.8 中度相关;
·0.3≤|r|<0.5 低度相关;
·|r|<0.3 关系极弱,认为不相关
(2)负相关:如果x,y变化的方向相反,如吸烟与肺功能的关系,r<0;
(3)无线性相关:r=0, 这里注意, r=0 不代表他们之间没有关系, 可能只是不存在线性关系。
下面用几个图来描述一下 不同的相关性的情况
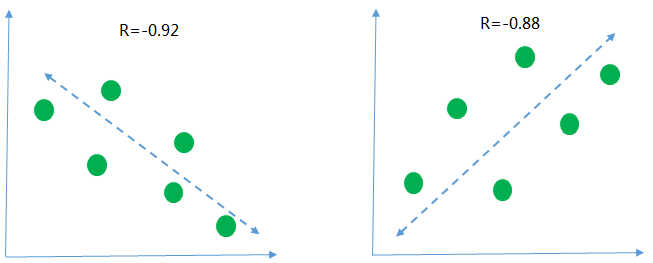
第一张图r=-0.92 <0 是说明横轴和纵轴的数据呈现负相关, 意思就是随着横轴的数据值越来越大纵轴的数据的值呈现下降的趋势, 从r的绝对值为0.92>0.8 来看, 说明两组数据的相关性高度相关
同样的, 第二张图 r=0.88 >0 说明纵轴和横轴的数据呈现正向的关系, 随着横轴数据的值越来越大, 纵轴的值也随之变大, 并且两组数据也是呈现高度相关
03
前面已经讲了什么是相关性分析方法, 那么我们怎么去实现这种分析方法呢, 以下先用python 实现
1. 首先是导入数据集, 这里以tips 为例
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline## 定义主题风格sns.set(style="darkgrid")## 加载tipstips = sns.load_dataset("tips")
2. 查看导入的数据集情况,
字段分别代表
total_bill: 总账单数
tip: 消费数目
sex: 性别
smoker: 是否是吸烟的群众
day: 天气
time: 晚餐 dinner, 午餐lunch
size: 顾客数
tips.head() # 查看数据的前几行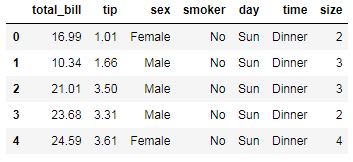
3. 最简单的相关性计算
tips.corr()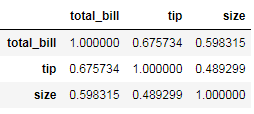
4. 任意看两个数据之间相关性可视化,比如看 total_bill 和 tip 之间的相关性,就可以如下操作进行可视化
## 绘制图形,根据不同种类的三点设定图注sns.relplot(x="total_bill", y="tip", data=tips);plt.show()
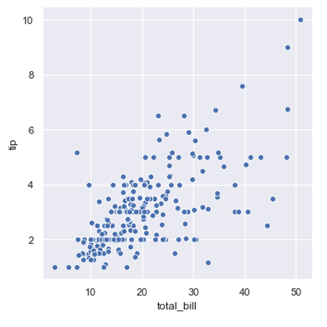
从散点图可以看出账单的数目和消费的数目基本是呈正相关, 账单的总的数目越高, 给得消费也会越多
5. 如果要看全部任意两两数据的相关性的可视化
sns.pairplot(tips)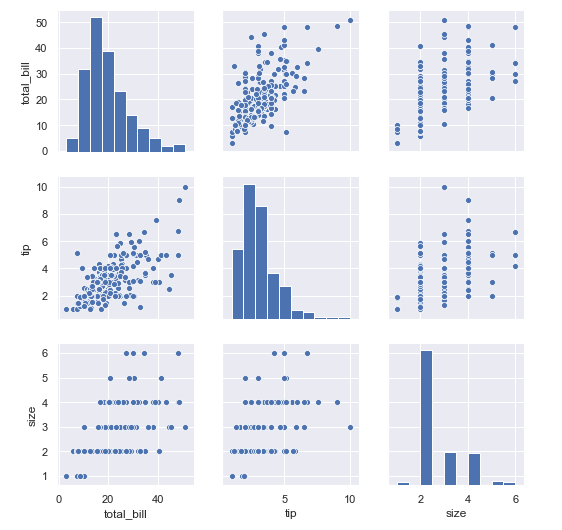
6. 如果要分不同的人群, 吸烟和非吸烟看总的账单数目total_bill和小费tip 的关系。
sns.relplot(x="total_bill", y="tip", hue="smoker", data=tips)# 利用hue 进行区分plt.show()
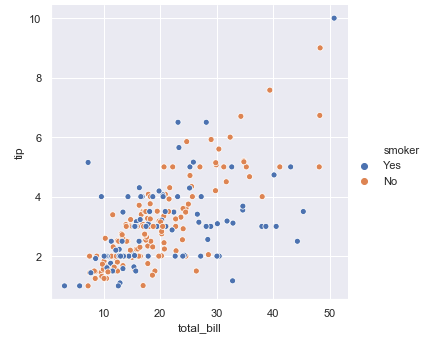
7. 同样的 区分抽烟和非抽烟群体看所有数据之间的相关性,我们可以看到
对于男性和女性群体, 在小费和总账单金额的关系上, 可以同样都是账单金额越高的时候, 小费越高的例子上, 男性要比女性给得小费更大方
在顾客数量和小费的数目关系上, 我们可以发现, 同样的顾客数量, 男性要比女性给得小费更多
在顾客数量和总账单数目关系上, 也是同样的顾客数量, 男性要比女性消费更多
sns.pairplot(tips ,hue ='sex')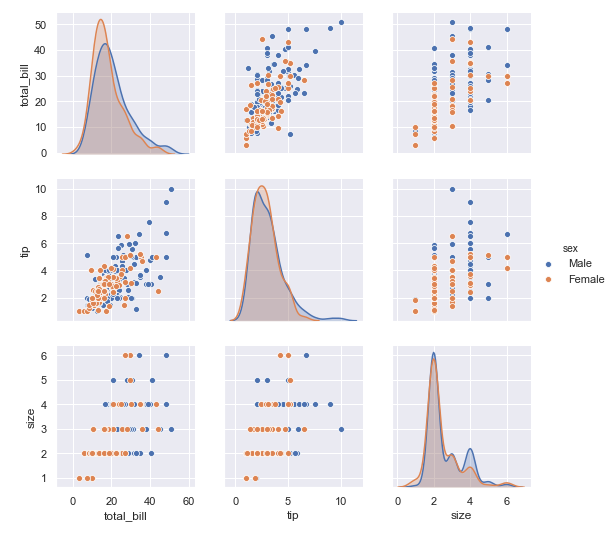
04
问题:
影响B 站留存的相关的关键行为有哪些?
这些行为和留存哪一个相关性是最大的?
分析思路:
找全与留存相关的行为
计算这些行为和留存的相关性大小
首先规划好完整的思路, 哪些行为和留存相关, 然后利用这些行为+时间维度 组成指标, 因为不同的时间跨度组合出来的指标, 意义是不一样的, 比如登录行为就有 7天登录天数, 30天登录天数
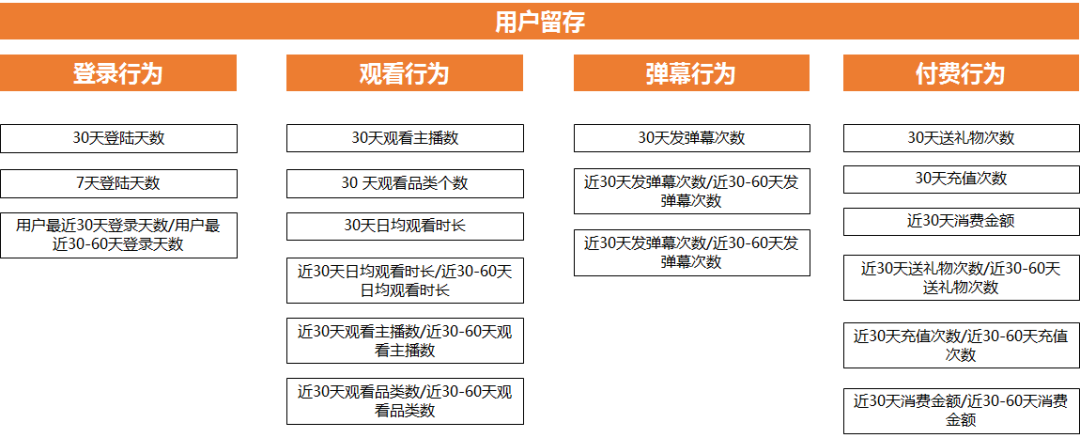
第二步计算这些行为和留存的相关性, 我们用1 表示会留存 0 表示不会留存
那么就得到 用户id + 行为数据+ 是否留存 这几个指标组成的数据
然后就是相关性大小的计算
import matplotlib.pyplot as pltimport seaborn as snsretain2 = pd.read_csv("d:/My Documents/Desktop/train2.csv") # 读取数据retain2 = retain2.drop(columns=['click_share_ayyuid_ucnt_days7']) # 去掉不参与计算相关性的列plt.figure(figsize=(16,10), dpi= 80)# 相关性大小计算sns.heatmap(retain2.corr(), xticklabels=retain2.corr().columns, yticklabels=retain2.corr().columns, cmap='RdYlGn', center=0, annot=True)# 可视化plt.title('Correlogram of retain', fontsize=22)plt.xticks(fontsize=12)plt.yticks(fontsize=12)plt.show()
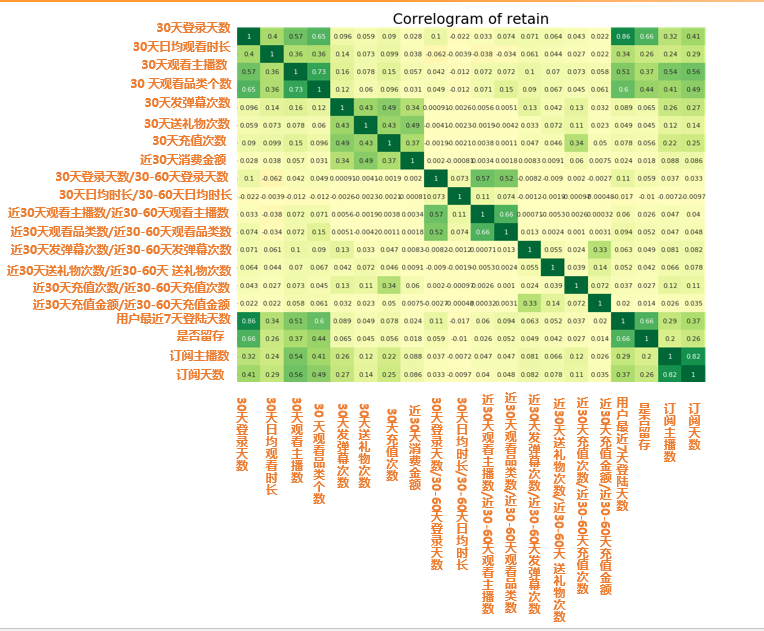
图中的数字值就是代表相关性大小 r 值 所以从图中我们可以发现
留存相关最大的四大因素:
•30天或者7天登录天数(cor: 0.66)
•30天观看品类个数(cor: 0.44)
•30天观看主播数 (cor: 0.37)
•30天日均观看时长(cor: 0.26)

转发扩散,点击好看↓↓