今天为大家分析一个英国在线零售商的交易数据集 img 着重为大家介绍一下如何运用RFM模型对客户进行分类
并且解决如下问题: 1.以星期为单位,周几的销售额最高?请可视化显示。 2.利用 RFM 模型,对 United Kingdom 的用户进行分类,分为如下所述的六类。 a) 选用合适的图形,可视化展示每一类用户数占总数的比例;可视化展示每一类用户消费额占总消费额的比例。 b) 对每一类用户,显示其每个月的消费总额的变化情况。(显示在一个 figure 中 以下是具体的代码 import pandas as pd读取数据,并且对数据格式作出一些调整,方便后续分析 # 读取并且查看数据 "Online Retail(1).csv" )InvoiceNo StockCode Description Quantity InvoiceDate UnitPrice CustomerID Country 0 536365 85123A WHITE HANGING HEART T-LIGHT HOLDER 6 2010/12/1 8:26 2.55 17850.0 United Kingdom 1 536365 71053 WHITE METAL LANTERN 6 2010/12/1 8:26 3.39 17850.0 United Kingdom 2 536365 84406B CREAM CUPID HEARTS COAT HANGER 8 2010/12/1 8:26 2.75 17850.0 United Kingdom 3 536365 84029G KNITTED UNION FLAG HOT WATER BOTTLE 6 2010/12/1 8:26 3.39 17850.0 United Kingdom 4 536365 84029E RED WOOLLY HOTTIE WHITE HEART. 6 2010/12/1 8:26 3.39 17850.0 United Kingdom
# 将时间数据设置为pandas的数据格式 "InvoiceDate" ] = pd.to_datetime(df["InvoiceDate" ])# 注:由于最近一次购物(Recency)是针对某个时间点计算的,而最后订货日期是 2011-12-09,因此 # 我们把 2011-12-10 当作今天,来计算 Recency。 "target_time" ] = pd.to_datetime("2011-12-10" )# 计算 Recency "Recency" ] = pd.to_datetime(df["target_time" ]) - pd.to_datetime(df["InvoiceDate" ])# 计算每个订单的总金额 "total" ] = df["Quantity" ] * df["UnitPrice" ]InvoiceNo StockCode Description Quantity InvoiceDate UnitPrice CustomerID Country target_time Recency total 0 536365 85123A WHITE HANGING HEART T-LIGHT HOLDER 6 2010-12-01 08:26:00 2.55 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 15.30 1 536365 71053 WHITE METAL LANTERN 6 2010-12-01 08:26:00 3.39 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 20.34 2 536365 84406B CREAM CUPID HEARTS COAT HANGER 8 2010-12-01 08:26:00 2.75 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 22.00 3 536365 84029G KNITTED UNION FLAG HOT WATER BOTTLE 6 2010-12-01 08:26:00 3.39 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 20.34 4 536365 84029E RED WOOLLY HOTTIE WHITE HEART. 6 2010-12-01 08:26:00 3.39 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 20.34
设置分析所需的星期、月份等属性,方便按此聚合 df["星期" ] = df["InvoiceDate" ].dt.dayofweek+1"月份" ] = df["InvoiceDate" ].dt.monthInvoiceNo StockCode Description Quantity InvoiceDate UnitPrice CustomerID Country target_time Recency total 星期 月份 0 536365 85123A WHITE HANGING HEART T-LIGHT HOLDER 6 2010-12-01 08:26:00 2.55 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 15.30 3 12 1 536365 71053 WHITE METAL LANTERN 6 2010-12-01 08:26:00 3.39 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 20.34 3 12 2 536365 84406B CREAM CUPID HEARTS COAT HANGER 8 2010-12-01 08:26:00 2.75 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 22.00 3 12 3 536365 84029G KNITTED UNION FLAG HOT WATER BOTTLE 6 2010-12-01 08:26:00 3.39 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 20.34 3 12 4 536365 84029E RED WOOLLY HOTTIE WHITE HEART. 6 2010-12-01 08:26:00 3.39 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 20.34 3 12
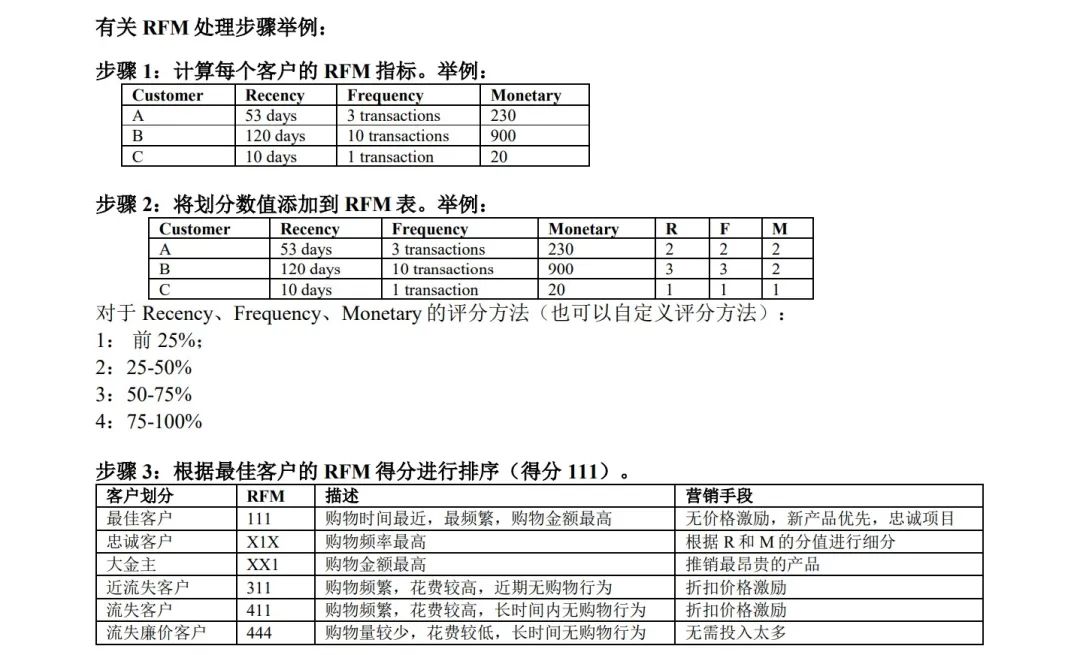
按星期聚合总销售额 df_by_w = df.groupby("星期" ).agg({"total" :"sum" }).reset_index()星期 total 0 1 1588609.431 1 2 1966182.791 2 3 1734147.010 3 4 2112519.000 4 5 1540610.811 5 7 805678.891
from pyecharts import options as opts"星期" ].to_list())"销售额" , df_by_w["total" ].to_list())"销售额对比图" ))以星期为单位,周几的销售额最高?答案是周四 bar.render_notebook()img 利用 RFM 模型,对 United Kingdom 的用户进行分类 按客户ID聚合,对发票订单号进行计数,对每个发票的销售额进行汇总,对recency取最小值(作为该顾客的recency值) df_by_c = df.groupby("CustomerID" ).agg({"InvoiceNo" :"count" , "total" :"sum" , "Recency" :"min" }).reset_index()"CustomerID" ,"Frequency" ,"Monetary" ,"Recency" ]CustomerID Frequency Monetary Recency 0 12346.0 2 0.00 325 days 13:43:00 1 12347.0 182 4310.00 2 days 08:08:00 2 12348.0 31 1797.24 75 days 10:47:00 3 12349.0 73 1757.55 18 days 14:09:00 4 12350.0 17 334.40 310 days 07:59:00
求出各列的四分位数 df_by_c["Frequency" ].quantile([0.25,0.5,0.75])"Monetary" ].quantile([0.25,0.5,0.75])将Recency这列的数据格式转为整数(取day这个属性就可以了) df_by_c["Recency" ] = df_by_c["Recency" ].dt.days"Recency" ].quantile([0.25,0.5,0.75])按照刚才求得的各项指标的四分位数,制定相应的函数,计算RFM的值 def decide_F(score):if score>102:return 1elif score>42:return 2elif score>17:return 3else :return 4if score>1611.725:return 1elif score>648.075:return 2elif score>293.3625:return 3else :return 4if score<16:return 1elif score<50:return 2elif score<143:return 3else :return 4"F" ] = df_by_c.apply(lambda x: decide_F(x.Frequency), axis = 1)"M" ] = df_by_c.apply(lambda x: decide_F(x.Monetary), axis = 1)"R" ] = df_by_c.apply(lambda x: decide_R(x.Recency), axis = 1)看一下求得的值 df_by_c.head()CustomerID Frequency Monetary Recency F M R 0 12346.0 2 0.00 325 4 4 4 1 12347.0 182 4310.00 2 1 1 1 2 12348.0 31 1797.24 75 3 1 3 3 12349.0 73 1757.55 18 2 1 2 4 12350.0 17 334.40 310 4 1 4
根据定义,制定对客户进行类型划分的函数 def decide_type(f, m, r):if f == 1 and m == 1 and r == 1:return "最佳客户" if f == 1 and m == 1 and r == 3:return "近流失客户" if f == 1 and m == 1 and r == 4:return "流失客户" if f == 4 and m == 4 and r == 4:return "流失廉价客户" if f == 1:return "忠诚客户" if m == 1:return "大金主" "客户类型" ] = df_by_c.apply(lambda x: decide_type(x.F, x.M ,x.R), axis = 1)CustomerID Frequency Monetary Recency F M R 客户类型 0 12346.0 2 0.00 325 4 4 4 流失廉价客户 1 12347.0 182 4310.00 2 1 1 1 最佳客户 2 12348.0 31 1797.24 75 3 1 3 大金主 3 12349.0 73 1757.55 18 2 1 2 大金主 4 12350.0 17 334.40 310 4 1 4 大金主
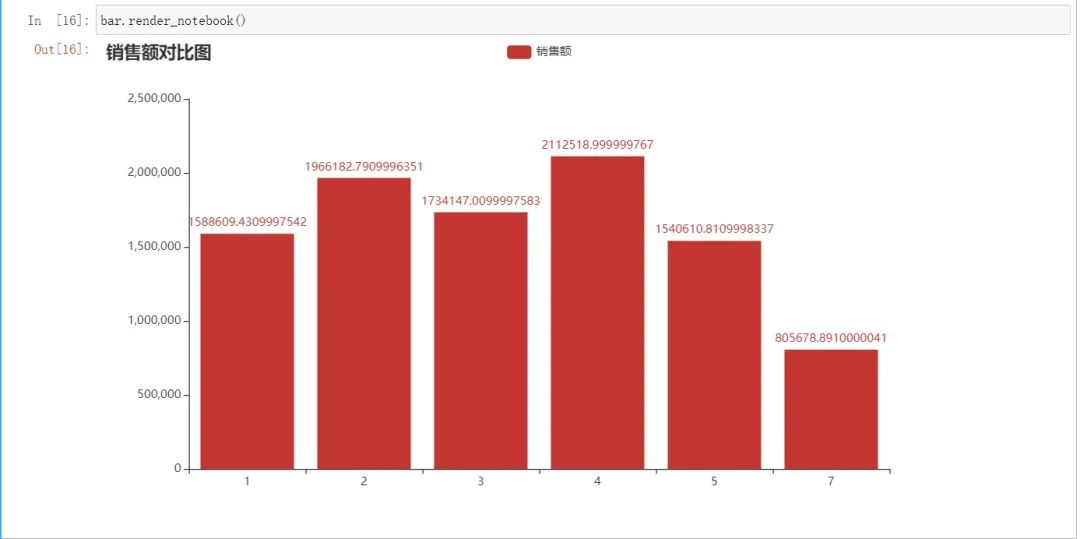
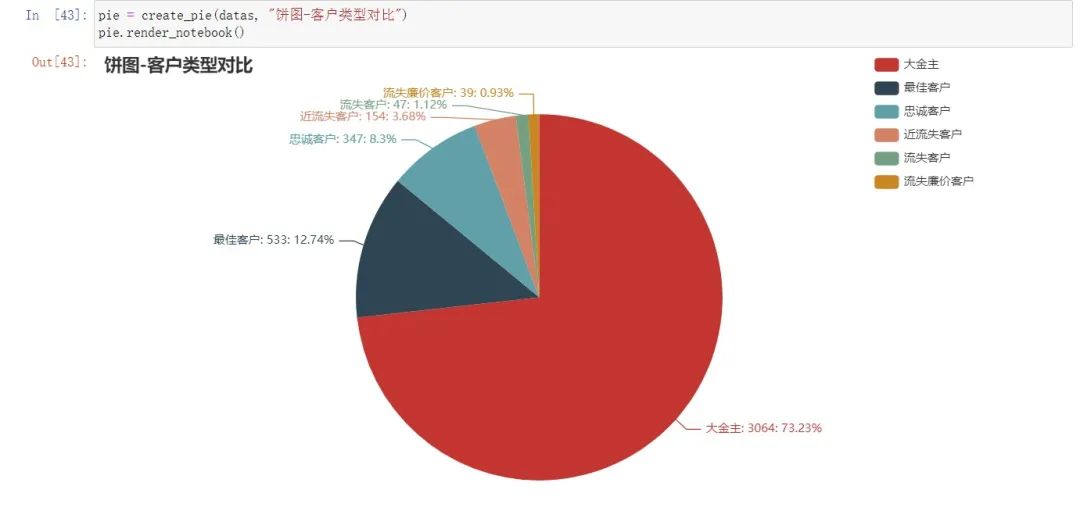
df_by_c_count = df_by_c.groupby("客户类型" ).size().sort_values(ascending=False)'大金主' , 3064),'最佳客户' , 533),'忠诚客户' , 347),'近流失客户' , 154),'流失客户' , 47),'流失廉价客户' , 39)]"" " 创建饼图对象 "" "" , datas)"right" )"{b}: {c}: {d}%" ))return piea)可视化展示每一类用户数占总数的比例 pie = create_pie(datas, "饼图-客户类型对比" )img 取出"CustomerID", "客户类型"这两列,准备与df合并 df1 = df_by_c[["CustomerID" , "客户类型" ]]"CustomerID" )InvoiceNo StockCode Description Quantity InvoiceDate UnitPrice CustomerID Country target_time Recency total 星期 月份 客户类型 0 536365 85123A WHITE HANGING HEART T-LIGHT HOLDER 6 2010-12-01 08:26:00 2.55 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 15.30 3 12 流失客户 1 536365 71053 WHITE METAL LANTERN 6 2010-12-01 08:26:00 3.39 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 20.34 3 12 流失客户 2 536365 84406B CREAM CUPID HEARTS COAT HANGER 8 2010-12-01 08:26:00 2.75 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 22.00 3 12 流失客户 3 536365 84029G KNITTED UNION FLAG HOT WATER BOTTLE 6 2010-12-01 08:26:00 3.39 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 20.34 3 12 流失客户 4 536365 84029E RED WOOLLY HOTTIE WHITE HEART. 6 2010-12-01 08:26:00 3.39 17850.0 United Kingdom 2011-12-10 373 days 15:34:00 20.34 3 12 流失客户
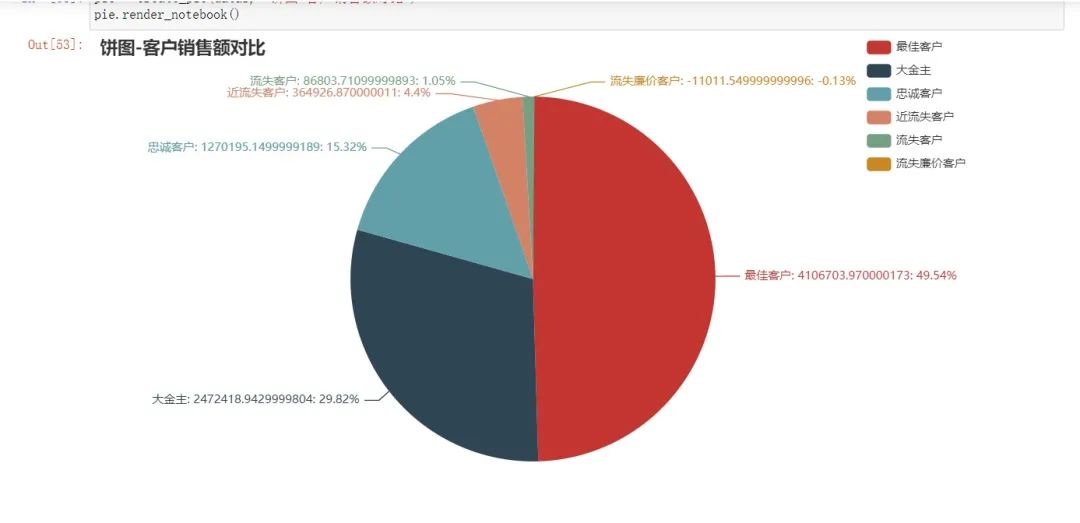
by_c_t = new.groupby("客户类型" )["total" ].sum().sort_values(ascending=False)'最佳客户' , 4106703.970000173),'大金主' , 2472418.9429999804),'忠诚客户' , 1270195.1499999189),'近流失客户' , 364926.870000011),'流失客户' , 86803.71099999893),'流失廉价客户' , -11011.549999999996)]b) 可视化展示每一类用户消费额占总消费额的比例 pie = create_pie(datas, "饼图-客户销售额对比" )img