
【统计学习方法】 第1章 统计学习方法概论(一)

点击上方“公众号”可订阅哦!

“如果我较早地了解这个公众号,也许我将有足够的时间来制定大统一理论。”
Albert Einstein
本章主要简述统计学习方法的一些基本概念
1
●
统计学习
统计学习
统计学习是关于计算机基于数据构建概率统计模型,并运用模型对数据进行预测与分析的一门学科。统计学习包括监督学习、非监督学习、半监督学习和强化学习。
统计学习方法的步骤
得到一个有限的数据集合
确定所包含所有可能的模型的假设空间,即学习模型的集合
确定模型选择的准则,即学习的策略
实现求解最优模型的算法,即学习的算法
通过学习方法选择最优模型
利用学习的最优模型对新数据进行预测或者分析
本书以介绍统计学习方法为主,特别是监督学习方法,主要包括用于分类、标注与回归问题的方法。
2
●
监督学习
1 监督学习的任务是学习一个模型,使模型能够对任意给定的输入,对其相应的输出做一个好的预测。
在监督学习过程中,将输入与输出看作是定义在输入(特征)空间与输出空间上的随机变量的取值。
输入实例记作
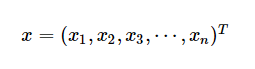
监督学习从训练数据集合中学习模型,对测试数据进行预测,训练数据由输入与输出对组成,训练集通常表示为:
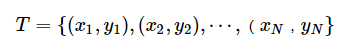
监督学习的模型可以是概率模型或非概率模型,由条件概率分布P(Y|X)或决策函数Y=f(X),表示,随具体学习方法而定。
2 问题的形式化
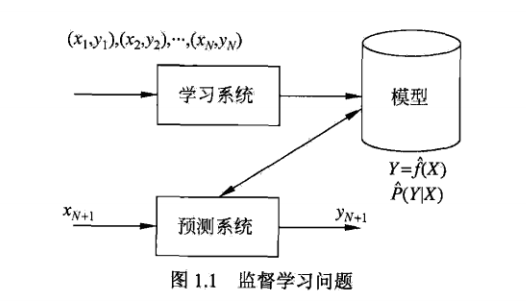
在学习过程中,学习系统(也就是学习算法)试图通过训练数据集中的样本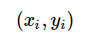 带来的信息学习模型。具体地说,对输入
带来的信息学习模型。具体地说,对输入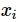 ,一个具体的模型
,一个具体的模型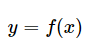 可以产生一个输出
可以产生一个输出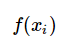 ,而训练数据集中对应的输出是
,而训练数据集中对应的输出是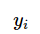 ,如果这个模型有很好的预测能力,训练样本输出的和模型预输出之间的差就应该足够小。学习系统通过不断的尝试,选取最好的模型,以便对训练数据集有足够好的预测,同时对未知的测试数据集的预测也有尽可能好的推广。
,如果这个模型有很好的预测能力,训练样本输出的和模型预输出之间的差就应该足够小。学习系统通过不断的尝试,选取最好的模型,以便对训练数据集有足够好的预测,同时对未知的测试数据集的预测也有尽可能好的推广。
3
●
统计学习三要素
统计学习方法都是由模型、策略和算法构成的,即统计学习方法由三要素构成,可以简单的表示为:
方法 = 模型 + 策略 + 算法
1 模型
统计学习首要考虑的问题是学习什么样的模型。在监督学习过程中,模型就是所要学习的条件概率分布或决策函数。
2 策略
有了模型的假设空间,统计学习接着需要考虑的是按照什么样的准则学习或选择最优的模型。
1)0-1损失函数
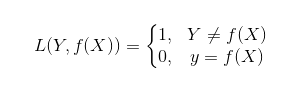
2)平方损失函数
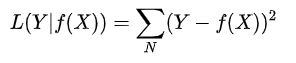
3)绝对损失函数
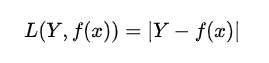
4)对数
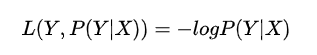
损失函数值越小,模型就越好。
经验风险最小化(ERM)的策略认为,经验风险最小的模型就是最优模型。
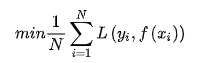
当样本容量足够大时,经验风险最小化能够保证有很好的学习效果,在现实中被广泛采用,比如,极大似然估计就是经验风险最小化的一个例子。但是当样本容量很小时,经验风险最小化的学习效果就未必好,会产生过拟合现象。
结构风险最小化(SRM)是为了防止过拟合而提出来的策略。结构风险最小化等价于正则化。结构风险在经验风险上加上表示模型复杂程度的正则化项。
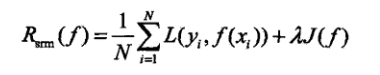
3 算法
算法是指学习模型的具体计算方法。统计学习基于训练数据集,根据学习策略,从假设空间中选择最优模型,最后需要考虑用什么样的计算方法求解最优模型。
4
●
模型评估与模型选择
1 训练误差与测试误差
统计学习的目的是使学到的模型不仅对已知数据而且对未知的数据都有较好的预测能力。不同的学习方法给出不同的模型,当损失函数给定时,基于损失函数的模型的训练误差和模型的预测误差就自然成为学习方法的评估标准。
训练数据平均损失:
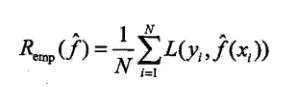
测试数据平均损失:

通常将学习方法对未知数据的预测能力称为泛化能力。
2 过拟合与模型选择
当假设空间含有不同复杂度的模型时,就要面临模型选择的问题。如果意味追求提高对训练数据的预测能力,所选择的复杂度则往往会比真模型更高。这种现象称为过拟合。
3 例:1.1 使用最小二乘法拟合曲线
假定给定一个训练数据集:
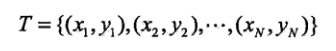
多项式函数拟合的任务是假定给定数据由M次多项式函数生成,,选择最有可能产生这些数据的M次多项式函数,即在M次多项式中选择一个对已知数据以及未知数据都有很好预测能力的函数。
设M次多项式为:
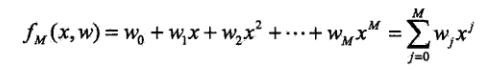
解决这一问题,首先确定模型的复杂度,即确定多项式的次数;然后在给定模型复杂度下,按照经验风险最小化的策略,求解参数,即多项式的次数。具体的策略:
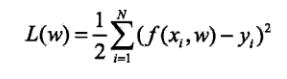
对w进行求导,
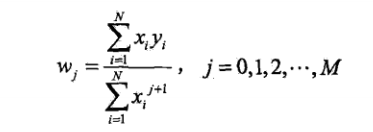
于是求得多项式参数w。
代码实现:
import numpy as npimport scipy as spfrom scipy.optimize import leastsqimport matplotlib.pyplot as plt%matplotlib inline# 目标函数def real_func(x):return np.sin(2*np.pi*x)# 多项式def fit_func(p, x):f = np.poly1d(p)return f(x)# 残差def residuals_func(p, x, y):ret = fit_func(p, x) - yreturn ret# 十个点x = np.linspace(0, 1, 10)x_points = np.linspace(0, 1, 1000)# 加上正态分布噪音的目标函数的值y_ = real_func(x)y = [np.random.normal(0, 0.1) + y1 for y1 in y_]def fitting(M=0):"""M 为 多项式的次数"""# 随机初始化多项式参数p_init = np.random.rand(M + 1)# 最小二乘法p_lsq = leastsq(residuals_func, p_init, args=(x, y))print('Fitting Parameters:', p_lsq[0])# 可视化plt.plot(x_points, real_func(x_points), label='real')plt.plot(x_points, fit_func(p_lsq[0], x_points), label='fitted curve')plt.plot(x, y, 'bo', label='noise')plt.legend()return p_lsq
当M为0时,
p_lsq_0 = fitting(M=0)# outputFitting Parameters: [0.06692556]
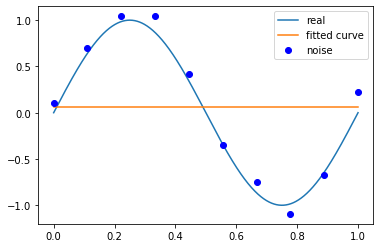
当M为1时,
p_lsq_1 = fitting(M=1)# outputFitting Parameters: [-1.38229915 0.75807514]
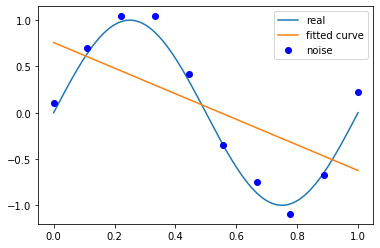
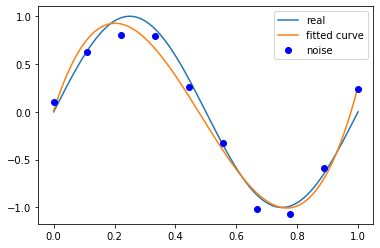
当M为3时,
p_lsq_3 = fitting(M=3)# outputFitting Parameters: [ 2.14584386e+01 -3.11545570e+01 9.94538545e+00 1.16742107e-02]
当M为9时,
p_lsq_9 = fitting(M=9)# outputFitting Parameters: [ 2.29442861e+04 -1.03205713e+05 1.95175642e+05 -2.01717066e+051.23851279e+05 -4.58498524e+04 9.86820576e+03 -1.12115742e+035.45133826e+01 1.05484073e-01]
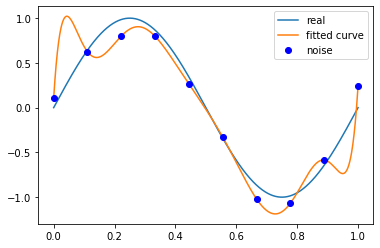
总结,结合M=0,1,3,9时多项式函数拟合的情况。如果,M为0,多项式曲线是一个常数,数据拟合效果很差。如果M为1,多项式曲线是一条直线,数据拟合效果也很差。相反,如果M为9,多项式曲线通过每一个数据点,训练误差为0。从对给定的数据拟合的角度来说,效果是最好的。但是,因为训练数据本身存在噪声,这种拟合的曲线对未知数据的预测能力往往不是最好的,在实际学习中并不可取。这时,过拟合现象就会发生。
当M为3时,多项式曲线对数据拟合效果足够好,模型也比较简单,是一个较好的选择。
END
扫码关注
微信号|sdxx_rmbj