
以图搜图:Python实现dHash算法

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
期研究了一下以图搜图这个炫酷的东西。百度和谷歌都有提供以图搜图的功能,有兴趣可以找一下。当然,不是很深入。深入的话,得运用到深度学习这货。Python深度学习当然不在话下。
这个功能最核心的东西就是怎么让电脑识别图片。
这个问题也是困扰了我,在偶然的机会,看到哈希感知算法。这个分两种,一种是基本的均值哈希感知算法(dHash),一种是余弦变换哈希感知算法(pHash)。dHash是我自己命名的,为了和pHash区分。这里两种方法,我都用Python实现了^_^
哈希感知算法基本原理如下:
1、把图片转成一个可识别的字符串,这个字符串也叫哈希值
2、和其他图片匹配字符串
算法不是耍耍嘴皮子就行了,重点是怎么把图片变成一个可识别的字符串。(鄙视网上那些抄来抄去的文章,连字都一模一样)拿一张图片举例。

首先,把这个图片缩小到8x8大小,并改成灰度模式。这样是为了模糊化处理图片,并减少计算量。
8x8的图片太小了,放大图片给大家看一下。

x8大小的图片就是有64个像素值。计算这64个像素的平均值,进一步降噪处理。
像素值=[
247, 245, 250, 253, 251, 244, 240, 240,
247, 253, 228, 208, 213, 243, 247, 241,
252, 226, 97, 80, 88, 116, 231, 247,
255, 172, 79, 65, 51, 58, 191, 255,
255, 168, 71, 60, 53, 69, 205, 255,
255, 211, 65, 58, 56, 104, 244, 252,
248, 253, 119, 42, 53, 181, 252, 243,
244, 240, 218, 175, 185, 230, 242, 244]
平均值=185.359375
得到这个平均值之后,再和每个像素对比。像素值大于平均值的标记成1,小于或等于平均值的标记成0。组成64个数字的字符串(看起来也是一串二进制的)。
降噪结果=[
1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 0, 0, 0, 0, 1, 1,
1, 0, 0, 0, 0, 0, 1, 1,
1, 0, 0, 0, 0, 0, 1, 1,
1, 1, 0, 0, 0, 0, 1, 1,
1, 1, 0, 0, 0, 0, 1, 1,
1, 1, 1, 0, 0, 1, 1, 1]
64位字符串 =
'1111111111111111110000111000001110000011110000111100001111100111'
由于64位太长,比较起来也麻烦。每4个字符为1组,由2进制转成16进制。这样就剩下一个长度为16的字符串。这个字符串也就是这个图片可识别的哈希值。
哈希值 = 'ffffc38383c3c3e7'
Python代码如下:
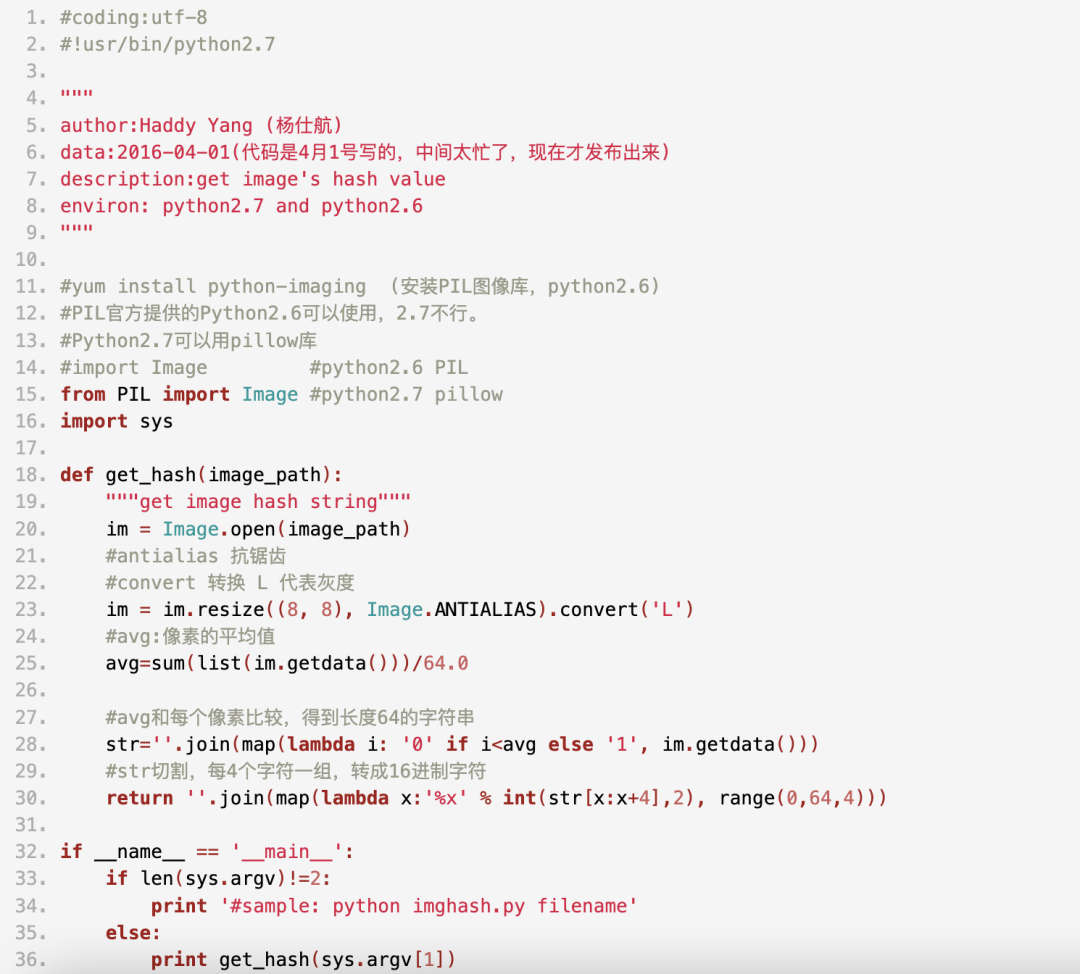
看看其他图片的哈希值:



这3张图片的哈希值分别和a.jpg(举例的那张图片)的哈希值对比。对比方法用汉明距离:相同位置上的字符不同的个数。例如a.jpg和b.jpg对比

有11个位置的字符不一样,则汉明距离是11。汉明距离越小就说明图片越相识。超过10就说明图片很不一样。
a.jpg和c.jpg的汉明距离是8;
a.jpg和d.jpg的汉明距离是7。
说明在这3张图片中,d.jpg和a.jpg最相似。
大致算法就是这样,汉明距离的代码我没给出,这个比较简单。一般都是在数据库里面进行计算,得到比较小的那些图片感知哈希值。
当然,实际应用中很少用这种算法,因为这种算法比较敏感。同一张图片旋转一定角度或者变形一下,那个哈希值差别就很大。不过,它的计算速度是最快的,通常可以用于查找缩略图。
现有3张图片,用前面的dHash均值哈希感知算法计算哈希值。



Hash均值哈希感知算法计算结果:
1.jpg:270f078fd1fdffff
2.jpg:f8f0e1f0eaefcfff
3.jpg:e70f058f81f1f1ff
1.jpg和2.jpg(旋转90度)的汉明距离是13;1.jpg和3.jpg(旋转5度)的汉明距离是5。(汉明距离是两个字符串对应位置对比,总共不同的个数)
很明显,旋转了90度汉明距离变得很大。在dHash算法中,它们是不同的。而我们肉眼可以看出其实是一样的。前面说过dHash算法比较较真、比较敏感。若要处理一定程度的变形,得要调整一下这个算法。
pHash算法就是基于dHash算法调整而来的,用第一次计算得到的值进行余弦变换。所以命名为余弦哈希感知算法。它可以识别变形程度在25%以内的图片。
大致原理和处理过程是这样:
把图片缩小到32x32的尺寸,并转为灰度模式。

得到这个平均值之后,再和每个像素对比。像素值大于平均值的标记成1,小于或等于平均值的标记成0。组成64个数字的字符串(看起来也是一串二进制的)。
降噪结果 = [
0, 1, 1, 1, 0, 0, 1, 1,
0, 1, 1, 0, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1,
0, 0, 0, 1, 1, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]
64位字符串 = '0111001101100001000000000000000011111111111111110001110000000000'
每4个数字,由2进制转成16进制,得到哈希值 = '73610000ffff1c00'
Python代码如下:


用这个算法计算2.jpg和3.jpg的哈希值和与1.jpg对比的汉明距离分别是:
2.jpg:7ffc0000ffffe000,汉明距离是5
3.jpg:7fff0000fffff800,汉明距离是5
很明显,pHash算法得到的汉明距离更加符合我们的要求。
原文地址
https://yshblog.com/blog/44
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx