
SQL实现数据质量DQC实践
Data Observability in Practice Using SQL
1.前言
在本系列文章中,我们会介绍如何从0到1做DQC。
数据可能由于很多原因而出现错误,比如数据重复,schema变动等。DQC是我们保证数据准确性的第一道防线。好的DQC应当在观察到数据出现问题时,能够自动进行报警,进而通知相关人员进行修复。
DQC有五个方面:
Freshness:我的数据是最新的吗? 我的数据是否存在滞后的情况?
Distribution:在字段这个级别上,我的数据是准确的吗?每个字段的值的范围是否都符合预期?
Volume:我的收集到的数据是否有缺失?
Schema:数据的schema是否发生了变更?
Lineage:数据流的依赖是什么样子?如果数据发生了错误,那么会影响哪些上下游?
在技术方面有一句名言,TALK IS CHEAP, SHOW ME CODE。那我们话不多说,开始操作吧。
2.实操
我们使用了一个天文数据集来进行演示。这个数据集用Python生成,生成的过程中,模拟了在生产环境中遇到的各种数据问题。
数据库方面我们使用了SQLite 3.32.3。

演示数据的Schema如下:
• _id: 每个星球的uid
• distance: 该星球与地球的距离,单位是光年
• g: 引力常数。每个星球的重力都是g的倍数
• orbital_period:单个轨道周期的长度,以天为单位
• avg_temp:表面平均温度,单位为开氏度
• date_added:星球被发现的日期
为了尽可能真实地模拟生产环境可能遇到的各种情况,除了_id,其它的字段都有可能是NULL。
我们先来简单看看数据:
sqlite> SELECT * FROM EXOPLANETS LIMIT 5;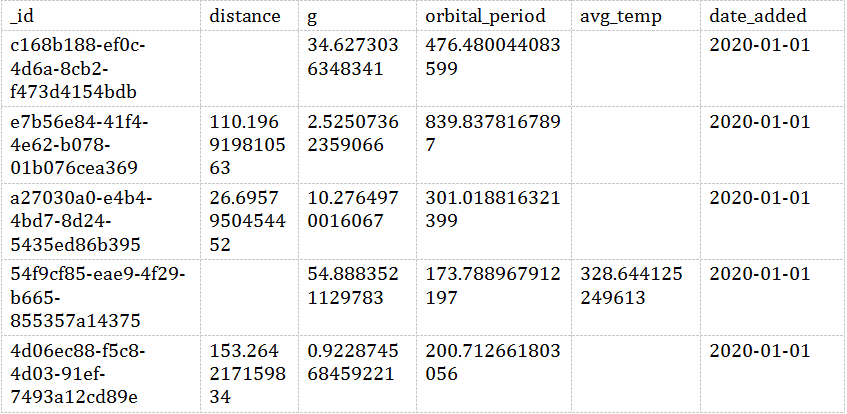
在这篇文章中,我们会演示如何观察数据的Freshness和Distribution。在后面的文章中,我们会考虑演示如何保证剩下的特性。
3.Freshness
要做DQC,我们首先需要保证数据的新鲜程度。它能告诉我们数据上次更新的时间。假如有一个小时报,它的数据看起来和上个小时的一模一样,那我们就要去排查哪儿发生了什么问题了。
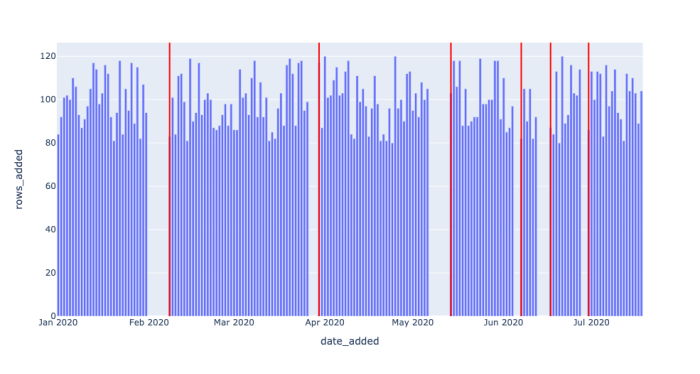
在我们的模拟数据中,我们用date_added这一列表明每颗星球的发现时间。所以我们能看到每天发现的星球数量:
SELECTDATE_ADDED,COUNT(*) AS ROWS_ADDEDFROMEXOPLANETSGROUP BYDATE_ADDED;
结果如下:
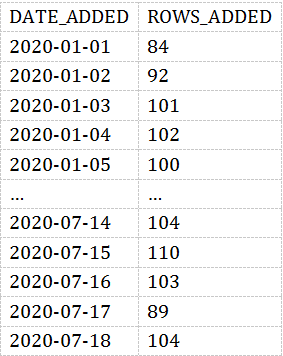
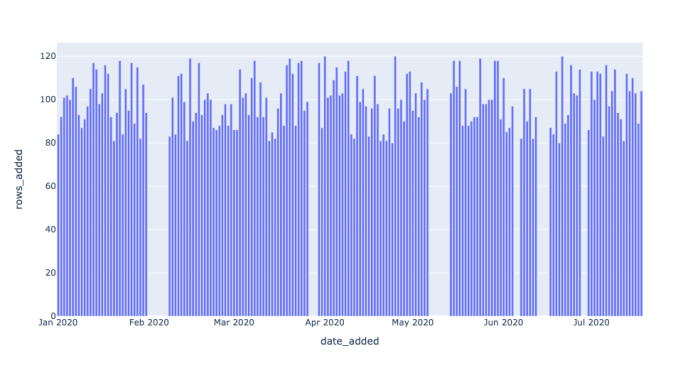
大概每天都会发现100个新的星球。结果用图表展示如下图所示:
那有了上面的结果,我们如何去查看数据是否新鲜呢?
我们可以通过引入一个新的度量值-DAYS_SINCE_LAST_UPDATE。它表示date_added之间的gap。如果数据没有问题,这个值应该每天都是1。当大于1时,说明数据间隔超过了一天。那很明显数据是有问题的。
WITH UPDATES AS(SELECTDATE_ADDED,COUNT(*) AS ROWS_ADDEDFROMEXOPLANETSGROUP BYDATE_ADDED)SELECTDATE_ADDED,JULIANDAY(DATE_ADDED) - JULIANDAY(LAG(DATE_ADDED) OVER(ORDER BY DATE_ADDED)) AS DAYS_SINCE_LAST_UPDATEFROMUPDATES;
这个是用的SQLLite的语法,如果使用其它数据库,那么语法可能有些差异,自己微调一下即可。
结果如下:
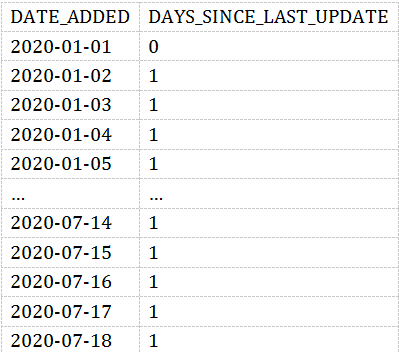
用柱状图表示如下:
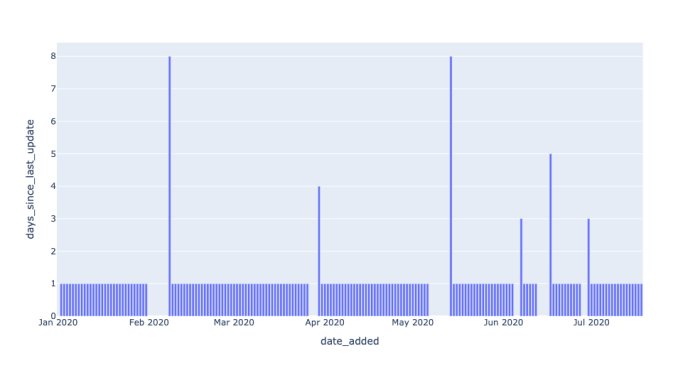
我们可以看到,大多数都是1。但是也有少量凸起。
我们首先找出来数据中差异超过一天的数据:
WITH UPDATES AS(SELECTDATE_ADDED,COUNT(*) AS ROWS_ADDEDFROMEXOPLANETSGROUP BYDATE_ADDED),NUM_DAYS_UPDATES AS (SELECTDATE_ADDED,JULIANDAY(DATE_ADDED) - JULIANDAY(LAG(DATE_ADDED)OVER(ORDER BY DATE_ADDED)) AS DAYS_SINCE_LAST_UPDATEFROMUPDATES)SELECT*FROMNUM_DAYS_UPDATESWHEREDAYS_SINCE_LAST_UPDATE > 1;
结果如下:
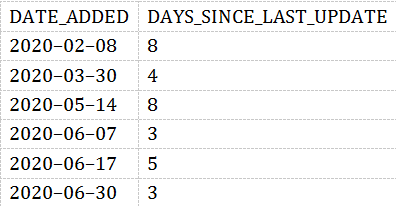
我们可以看到,在2020-05-14,表中最新的数据是8天前的!
那观察到这个结果之后,下一步就是要发送警报了。在发送警报之前,我们需要确定有多少到底数据差异几天才表明有数据有异常。在上面的SQL中, DAYS_SINCE_LAST_UPDATE > 1这里表示我们认为只要间隔超过一天数据就有异常。这个需要根据自己的场景去进行调整。
4.Distribution
接下来我们需要评估每个字段的值的分布情况。这让我们可以早日发现数据里的异常。比如原来一列的NULL值比率是10%,突然有一天到达了90%。那么数据肯定是有问题的。
SELECTDATE_ADDED,CAST(SUM(CASEWHEN DISTANCE IS NULL THEN 1ELSE 0END) AS FLOAT) / COUNT(*) AS DISTANCE_NULL_RATE,CAST(SUM(CASEWHEN G IS NULL THEN 1ELSE 0END) AS FLOAT) / COUNT(*) AS G_NULL_RATE,CAST(SUM(CASEWHEN ORBITAL_PERIOD IS NULL THEN 1ELSE 0END) AS FLOAT) / COUNT(*) AS ORBITAL_PERIOD_NULL_RATE,CAST(SUM(CASEWHEN AVG_TEMP IS NULL THEN 1ELSE 0END) AS FLOAT) / COUNT(*) AS AVG_TEMP_NULL_RATEFROMEXOPLANETSGROUP BYDATE_ADDED;
结果如下:
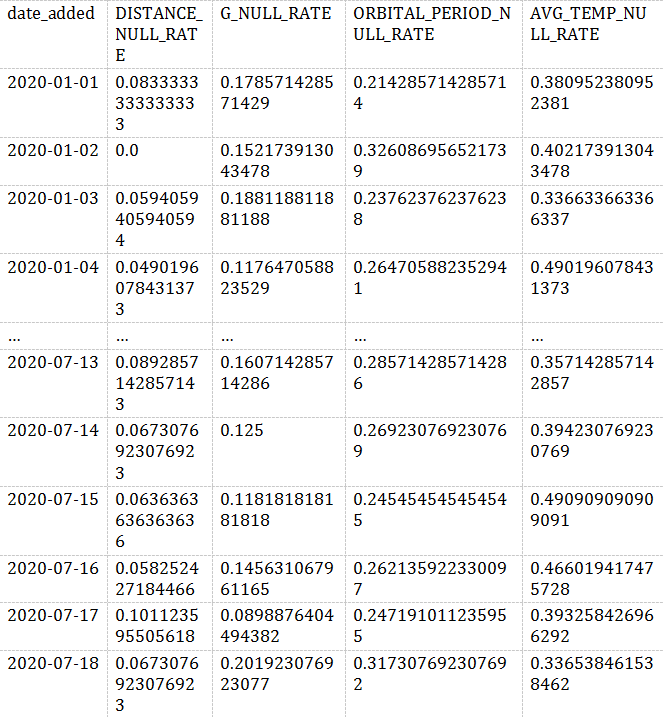
通用公式 CAST (SUM (CASE WHEN SOME _ metric IS NULL THEN 1 ELSE 0 END) AS FLOAT)/COUNT (*) ,按 DATE_ADDED 列分组,我们能看到NULL值得分布情况。
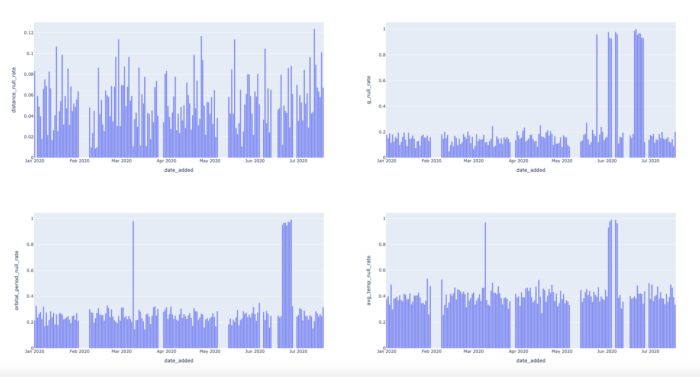
我们可以看到,有一些列上的NULL分布有凸起,所以我们也应当检测。我们现在只看AVG_TEMP这一列。
WITH NULL_RATES AS(SELECTDATE_ADDED,CAST(SUM(CASEWHEN AVG_TEMP IS NULL THEN 1ELSE 0END) AS FLOAT) / COUNT(*) AS AVG_TEMP_NULL_RATEFROMEXOPLANETSGROUP BYDATE_ADDED)SELECT*FROMNULL_RATESWHEREAVG_TEMP_NULL_RATE > 0.9;
我们的检测脚本很简单,只要NULL值在某一天比率超过90%,就报警。
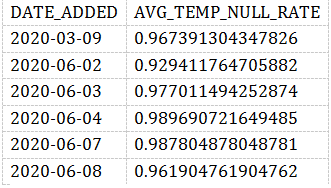
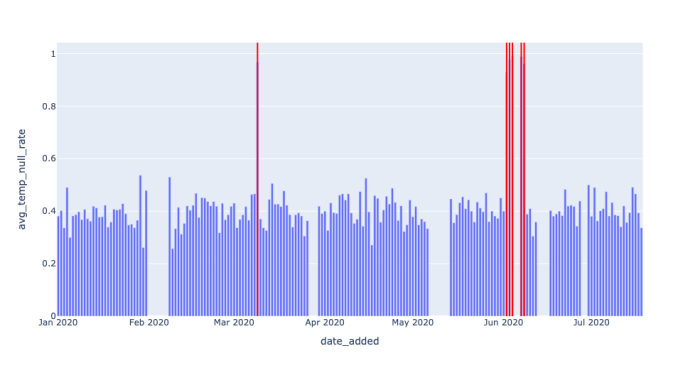
注意,在这两个查询中,阈值都是0.9。我们实际上是在说: “任何高于90% 的无效率都是个问题,我需要了解它。”
但如果我们应用滚动平均值的概念来进行阈值设定,是不是更好一些呢?
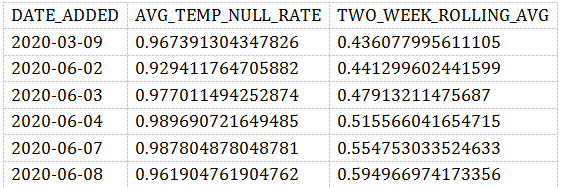
WITH NULL_RATES AS(SELECTDATE_ADDED,CAST(SUM(CASE WHEN AVG_TEMP IS NULL THEN 1 ELSE 0 END) AS FLOAT) / COUNT(*) AS AVG_TEMP_NULL_RATEFROMEXOPLANETSGROUP BYDATE_ADDED),NULL_WITH_AVG AS(SELECT*,AVG(AVG_TEMP_NULL_RATE) OVER (ORDER BY DATE_ADDED ASCROWS BETWEEN 14 PRECEDING AND CURRENT ROW) AS TWO_WEEK_ROLLING_AVGFROMNULL_RATESGROUP BYDATE_ADDED)SELECT*FROMNULL_WITH_AVGWHEREAVG_TEMP_NULL_RATE - TWO_WEEK_ROLLING_AVG > 0.3;
实际上就是当前日期和最近两周内的平均NULL比例做一个对比。
结果如下:
5.思考
可以看到,现在我们的检测都是通过SQL实现,但随着生产环境数据的增加,观测指标的增多,使用机器学习去做是不是更好的呢?
翻译来源:https://www.montecarlodata.com/data-observability-in-practice-using-sql-1/