
SQL规范落地实践
本文由707同学供稿。
1. 概述
数据库在各类生产系统中是不可或缺的中间件,SQL代码作为操作数据库的标准语法,在日常开发中使用比例非常高,几乎每个批次都会有产品涉及,但各开发人员对SQL开发技能的掌握程度参差不齐。
为了规避开发技能不足,而引发SQL质量问题的风险,在最大程度上规范开发方法,由数据库专家团队从历史经验和业界优秀实践中总结出一套SQL代码开发规范。
然而,无法落地的规范,只能是空中楼阁,为了能够让规范顺利落地,我们通过将规范内化在工具中,将一条条规范条文具象化、可验证化,以检查开发人员提交的SQL代码质量。
2. 规范
2.1 整体介绍
为了更好地指导产品SQL设计及开发,避免不恰当的设计、开发带来问题和隐患,同时为了提升开发人员对SQL相关知识的掌握程度,制定了若干SQL规范。
本规范分为SQL设计规范和SQL开发规范两个部分。SQL设计规范重点关注在设计阶段需要考虑的库、表、字段、索引设计,通过充分设计降低后续工程阶段正向及反向实施成本。SQL开发规范重点关注编码、DDL、DML、查询优化,通过明确的规则指导编写合理、高效的SQL语句。
本实践落地的SQL规范为开发规范,具体规范如下,包含DML、DQL和DDL,并且规范分为三个级别:强制、推荐和参考,强制表示必须按照规范实现,推荐表示建议按照规范实现,参考表示仅提供参考。
2.2 DML与DQL规范示例
【强制】SQL关键字大写
【强制】INSERT语句必须要插入的字段名称
【强制】数据行删除/更新使用delete/update时,必须带上WHERE子句
【强制】禁止在UPDATE语句中,将“,”写成AND
【推荐】如果需要清除全表数据,建议使用TRUNCATE TABLE删除所有的行
【推荐】避免使用REPLACE。先采用SELECT判断是否存在记录,然后再考虑INSERT或UPDATE
【参考】如无必要锁定数据,则应避免使用FOR UPDATE
【强制】禁止使用SELECT * 查询
【强制】WHERE 条件中的过滤条件字段上严禁使用任何函数,包括数据类型转换函数
【强制】多表关联查询时,避免使用非索引字段作为关联条件
【强制】禁止使用ORDER BY RAND()
【强制】进行模糊查询时,避免使用左模糊或者全模糊匹配。根据最左前缀原则合理安排查询条件
【推荐】避免使用COUNT(*)作为查询字段
【推荐】相同字段的OR条件大于3个,建议使用IN代替
【推荐】不同字段的OR条件大于3个,建议使用使用UNION ALL代替
【推荐】尽量避免在SELECT子句中使用子查询,替换为连接查询
【推荐】考虑使用IN替代EXISTS做嵌套查询
【推荐】必须进行表关联查询时,控制关联表的个数不超过两个
【推荐】外连接的 SQL 语句,建议一律写成LEFT JOIN(左侧为主表),而不要使用 RIGHT JOIN
【推荐】对MIN(), MAX()等聚合函数,建议利用数据的有序性配合LIMIT 1将SQL等价转化
【推荐】使用WHERE子句代替HAVING子句
【强制】分页查询语句全部都需要带有排序条件,除非业务方明确要求不要使用任何排序来随机展示数据
【强制】多表 JOIN 的分页语句,如果过滤条件在单个表上,先利用索引在子查询中通过分页限定数据范围,再 JOIN
【推荐】大数据量分页查询时,避免直接使用数据库提供的分页命令LIMIT m,n
【强制】SQL语法错误导致的异常
2.3 DDL规范示例
【强制】避免使用存储过程、触发器、函数等,容易将业务逻辑和数据库耦合在一起;
【强制】所有的数据库对象命名,只使用小写字母、数字和下划线的组合,并以字母开头。
【强制】禁止使用SQL关键字进行数据库对象命名。
【强制】所有的数据库对象命名,长度不要超过32个字符。
【推荐】采用如下规则进行索引命名:
非唯一索引按照“idx_字段名称_字段名称[_字段名]”进行命名;
唯一索引按照“uk_字段名称_字段名称[_字段名]”进行命名;
主键按照:pk_表名称。
【强制】明确指定数据库默认的字符集和校验规则;
【推荐】所有表统一使用utf8字符集,排序规则采用utf8_general_ci。特殊情况如:需要存Emoji表情,则可选utf8mb4,校对规则采用对应的utf8mb4_general_ci。
【参考】控制单表字段个数不要超过50个。
【强制】存储TEXT类型的字段时,独立出来一张表,用主键来对应,避免影响其它字段索引效率。
【推荐】建表必备三个字段:id, create_time, update_time.
【推荐】如果可能,字段尽量使用NOT NULL属性,并且设置默认值。
【推荐】如果变长字符型长度超过2000,采用TEXT类型。
【强制】InnoDB引擎表必须设置主键。
【强制】禁止使用外键。
【强制】在varchar字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度。
【推荐】采用自增整型字段作为InnoDB引擎表的主键。
【推荐】避免冗余索引:避免在主键列上重复建立索引;根据最左前缀原则避免重复索引。
【强制】对表的多次ALTER操作合并为一次操作
3. 检查规范落地
3.1 落地方式
在设计过程中,考虑到以工具来实现,既能让开发环境本地自测,也可以通过DevOps平台自动回归检查,并且尽量对工程减少入侵。故采用Maven插件的形式来提供支持,对原工程业务代码无任何入侵,且插件只在编译构建阶段生效,不会对服务的执行产生任何影响。该方式无论在本地配置还是在DevOps平台配置均可方便使用,避免对开发人员造成额外的工作负担。该工具的核心思想与编码设计上次已经分享过,详见文章动手撸一个SQL规范检查工具。
3.2 架构设计
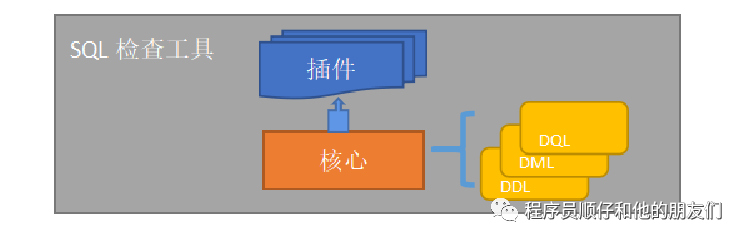
本SQL检查工具针对使用Mybatis框架的工程,架构由两部分组成,分别是核心模块和插件模块,将上层插件与核心拆分开,而非形成单体结构,可最大化增加可扩展性。
核心部分负责SQL的解析,最重要的是DDL、DML和DQL三种类型SQL规则,根据前文中的规范编写落地为对应的语法规则,一条规则对应一个类文件,若规则有扩充可便捷地向核心模块追加。
插件部分目前为Maven形式,以核心作为支撑,插件在编译阶段运行时会调起核心模块,依次检查所有的规则,未来可根据需求扩展为其他形式的插件。
3.3 执行逻辑
收集SQL语句:扫描代码中Mybatis相关的mapper配置文件,比如位于资源文件夹中的配置文件resources/mapper/*.xml,识别出所有SQL语句,供后续进行分析。
语法分析:根据SQL语法规则,对SQL语句进行语法分析,提取出SQL语句各关键字元素,并进行中间结果分类保存,再做进一步分析。
规范检查:
1)静态检查
根据预先设计好的语法检查规则,对SQL语句进行静态代码检查,逐条进行分析扫描,得到每条规则的评判结果,进行记录。
2)动态检查
有一些规则依赖于真实的数据库,仅凭SQL静态检查无法完全覆盖,故在仿真生产环境的镜像库,对SQL语句进行重放,识别对数据库表记录增删改查操作耗时时长,识别慢SQL。收集SQL执行计划,分析是否为最优执行计划。
3.4 报告展示
规范检测很重要,但是结果的展示也同样重要,具有一种设计优良的可视化展示形式是非常重要的。本工具提供了多种展示形式,包括终端展示、Json报文结构展示、Html页面展示三种,并且提供了方便的可扩展点,通过开发新的Appender即可添加新的展示形式。报告结果中会有所有检测出的规范问题,以及解决方案,用户可以根据提示对SQL进行整改。
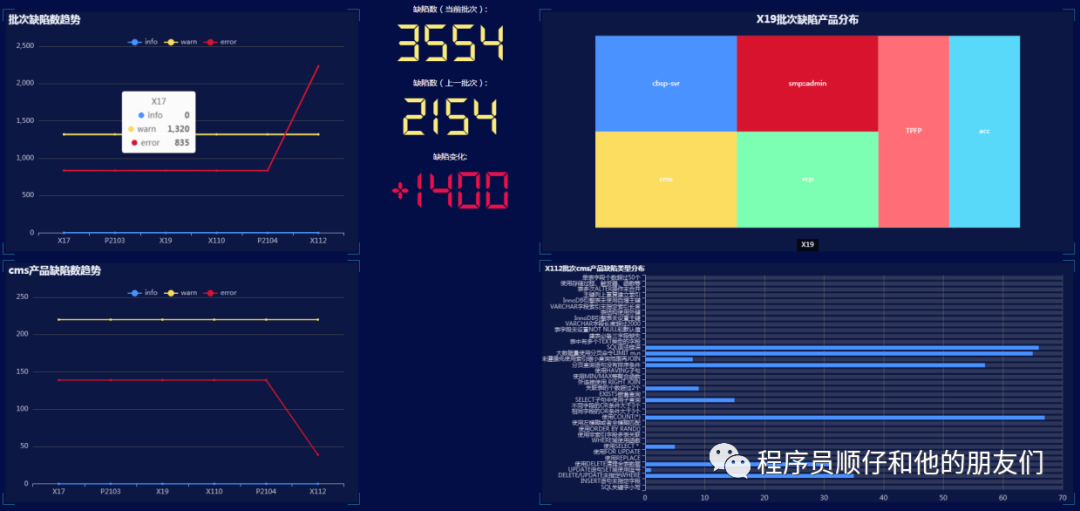
此外,还提供了相应的仪表盘网站,页面中可展示所有产品的检测结果汇总和详情。可通过该站查看所有批次缺陷趋势,某个批次各产品的缺陷分布,某个产品的各批次缺陷数量趋势,以及某批次某产品各种缺陷类型的分布情况。用户通过该网站可查看各产品缺陷增长和缺陷修复情况,并可以按照各批次和各产品筛选缺陷情况,从多个维度监测各产品SQL规范情况。从各产品的排名可以起到正向的督促监督作用,有对比竞争能够极大激发大家修改不规范项的欲望,促进SQL质量的稳步提升。
3.5 DevOps自动化
SQL检查是一个持续的过程,需要在开发过程中不断地进行,我们可以通过CI流水线进行集成,在执行Maven构建的命令中添加SQL检查插件的执行命令,按照一定的构建规则,可以持续向仪表盘上推送数据。这样就形成一个持续不断的流式SQL检查结果,可实时统计出缺陷情况。
4. 总结
通过规范的制定、规范的开发、规范的结果展示和规范的自动化检查,一系列的实践成功将SQL规范落地,本规范的落地标志着这种方式的探索初见成效,是一种可行的方案。SQL规范仅仅是一个开始,未来更多的规范同样可以以这种方式落地,并最终开花结果。