
如何理解数据质量?
数据质量该如何理解
|0x00 题外话:架构推导思路
说起数据质量,其实是一个很宽泛的问题,类似于写数据建模一样,是一个抽象概念为主的事情,对于程序员群体来说,总是难以解答和回答的。这里针对数据质量等类似的、在数据仓库平台中必须提及的概念,提供一种解答的思路,就是架构推导理论。
先说一下基本的架构推导理论。根据ISO/IEC 42010:20072中的定义,架构 = 组件模块+关联关系+约束&指导原则。我们用一张图来解释架构在系统中的作用:
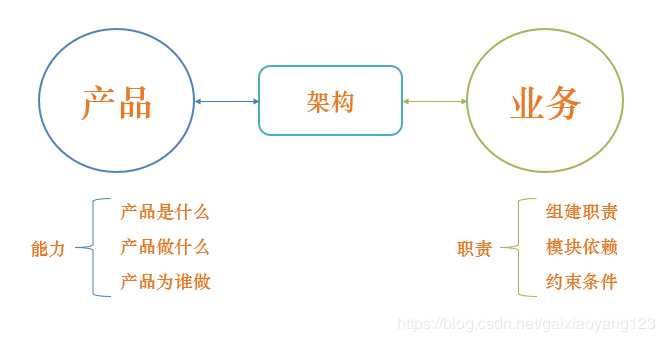
从上图可以看出,架构是介于产品和业务之间的桥梁,从任意维度出发,通过架构,能够推导出另一维度的相关信息。因而,架构的推导也有两种思路:自顶向下和自底向上。
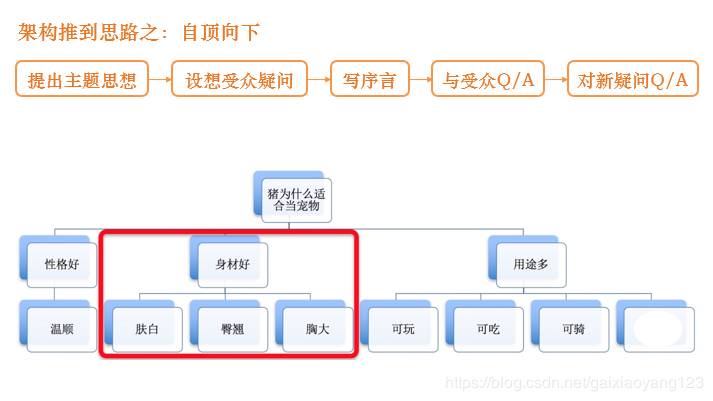
先说一下自顶向下的思路:假设我们目前有一个问题“猪为什么适合当宠物”,我们可以设想一下受众的疑问,从观察者的角度出发总结出几条经验,例如性格好、身材好和用途多。在总结出基本结论的基础上,我们再进行深一步的挖掘,例如“为什么猪的性格好”,我们可能得出“因为猪的性格很温顺”,再例如“为什么猪的身材好”,我们可能得出“因为猪的皮肤白、屁股翘”。由此我们再针对每一个细节深挖,就得到了我们要的系统架构细节。用一张图描述这个问题,如下:
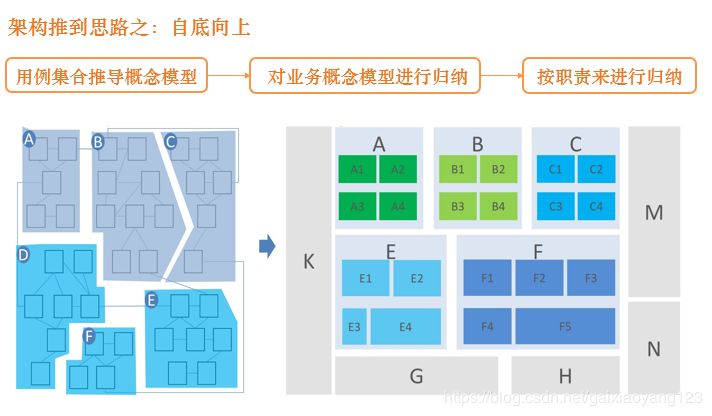
再说一下自底向上的思路:假设我们目前有很多的用例集合,例如“我们需要监控用户浏览页面的行为”、“用户在页面中的某种点击行为需要记录”、“点击行为需要与展现行为进行关联”,等等。在此基础上,我们将大段的产品文档进行梳理,抽象出几个关键的概念模型,例如“产品需要分别统计点击和展现日志”、“点击和展现日志需要通过某种ID进行关联”这样的架构概念,最后按照系统的职责,设定好一个具体的思路,并分别实现。用一张图描述这个问题,如下:
通过这两种方式,我们可以先采用自底向上的方式,来分拆产品描述的细节,总结出初步的观点,再按照程序员的思路进行自顶向下的拆分,最后再进行一轮自底向上的总结,基本上就可以确定一套系统应该有的架构和细节。
说了这么多,其实核心思想很简单,针对任何一类问题,都有两种思考它的方法:自顶向下和自底向上。在此基础上,可以多次组合这两种方法,来得到一个问题完整的多方面回答。
|0x01 从程序员视角看数据质量
那么数据质量应该怎么思考,首先从程序员的角度出发,进行自底向上总结。
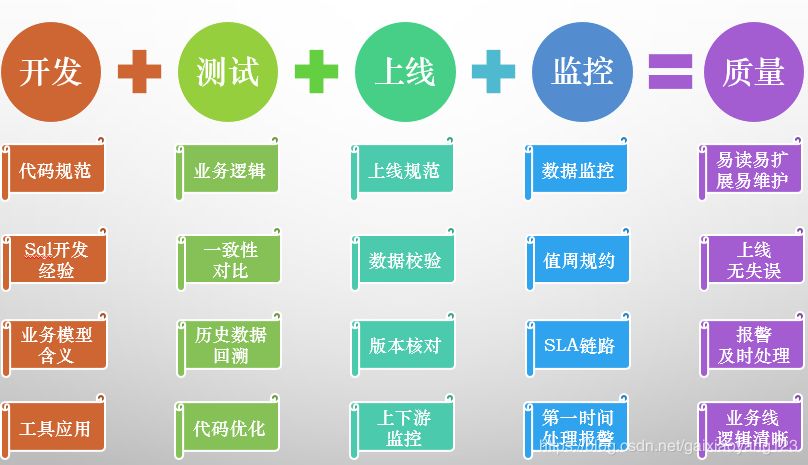
第一步,从程序员的日常工作出发。数据仓库工作中,开发占了绝大部分的比重,因此代码规范肯定是非常有必要的,其次应该是具体技术的应用细节,例如注意数据倾斜等问题,再次要对业务的概念非常熟悉,避免与产品思路上的差异,最后就是要熟练应用各种开发工具。把这些事情的各种细节做总结,升华一下概念,就是开发质量。
第二步,从配合人员的工作出发。如果团队稍微大一些的话,肯定有相应的测试或者运维人员,对于我们开发的代码和运行进行配合。例如业务逻辑的二次check、数据的运行结果之间一致性是否有保障,同时如果已开发的过程存在了问题,如何回溯历史数据、优化老代码也属于这个范畴。总结一下,就是需要测试的配合。
第三步,从流程角度出发避免人为失误。基本上正规一些的公司都会强调上线规范,做好数据校验、回滚方案、上下游监控等工作。
第四步,从维护角度出发及时发现问题。数据仓库其实最主要的一个问题,就是针对每一个问题,都要有相应的开发人员来检查问题,因此要有详细的值周规约,能够在第一时间出问题时有人介入。此外还需要配合各种完善的报警与监控平台,针对数据仓库日常的整体状况进行一个全面的监控。
总结这四个细节问题的汇总,可以得到四个角度的回答:易读易扩展易维护;上线无失误;报警及时处理;业务逻辑清晰。这四条其实就可以看作是数据质量的一个大的概念,用一张图来总结更为清晰一些:
|0x02 从理论层面看数据质量
虽然说从程序员的角度出发,数据质量的问题描述的已经比较清晰了,但是对于非数据开发的程序员,以及产品和运营人员来说,这些还是有些难以读懂。因此很多时候要求我们用更抽象的角度出发,来进行问题的拆解。这里常见的描述问题方式,参照CAP与BASE原则,我们可以仿照别人的概念,来组织和细化一个属于我们自己的概念,这里也算是自顶向下思路的一种实现。
从笔者自身的角度出发,我总结了大概八条原则,详情如下:
数据的完整性:数据的完整性比较易于理解,主要作用在数据仓库架构中的数据采集环节中,对应到数据分层理论是DWD层,例如要剔除掉数据的缺失信息,注意采集过程中的数据偏移现象并纠正,等等;
数据的准确性:数据的准确性不太常见,但比较关键,例如记录消费金额的信息不能为负值,要加入校验逻辑以防止业务部门的数据修正操作,对应到数据分层理论是DWD层,另外需要引入反作弊系统的支持,过滤掉那些无效的作弊数据,防止统计结果出现偏差,对应到数据分层理论是ODS层,;
数据的一致性:数据的一致性主要作用在离线开发环节中,对应的数据分层理论是DWS层,针对同一主题下的数据统计,确保统计的数据源是一致的,例如在搜索引擎系统中,由于搜索日志、广告展现日志是分开记录的,那么统计广告的展现量应该以广告展现日志为基准进行统计,尽管搜索日志带有广告展示的信息,但它的统计结果会因为各种问题与广告展现日志的结果对不上,这里不可以采信;
数据的及时性:比较完整一些的数据平台都包括了实时数据统计、小时级数据统计及天级数据统计,其实数据准时产出也算是数据质量原则的一部分,应该每天早上8点统计好前一天的数据,如果你延迟到了10点,肯定会有很多客户投诉你,尽管数据是准确的,但这种引起客户投诉的情况,也需要归到数据质量原则中来;
数据的安全性:假设团队规模较大,涉及了多个业务线的数据,那么权限与安全问题也需要值得注意,因为消费金额这一类的数据,在任何一家公司都属于敏感信息,在对外暴露时需要做脱敏的处理,提供点击展现等信息也应该有权限申请的步骤,这个环节既可以作用在数据分层理论的ADS层,也可以作用在DWS层;
数据的自查性:数据仓库并不是说我开发好了,就放在那里不管了,也不能说我需要指定一个人,天天去盯着有没有问题,数据仓库的架构中应该有对自身运行情况自动检查的特性,作用在数据分层理论的ADS层,例如在重点步骤之后添加校验环节,统计同比/环比信息,波动过大时主动报警等;
数据的周期性:数据质量不仅与开发过程密切相关,也与存储数据的硬件息息相关,在很多场景下,由于服务器资源的有限增长与数据资产的无限增加,必然到了一定的时间就会产生成本压力,因此定期删除无用数据,针对一些冷门数据做极限压缩,都是有效保障数据长期稳定运行的基石;
数据的可追踪性:数据的可追踪性,与元数据平台的搭建息息相关,可以说因为有了元数据平台,能够看到每一个过程的上下游血缘信息,因此在排查问题时,能够快速及时定位出问题的步骤,这非常关键。
|0x03 从架构的环节看数据质量
但其实总结出理论还是很抽象,一些Boss或者Leader会要求你结合具体的场景来解释这些概念,这个时候从一次普通的业务开发出发,完整的阐述从数据采集、同步、开发,到最后的数据展现,我们都做了哪些事情,就十分有必要了,这也是从架构角度看数据质量如何保障的具体实现。
首当其冲的是业务信息的变更,例如增加某种统计字段,或者是重新改变某种指标的计算方式。业务信息的变化不仅是需要开发人员的主动介入,也需要平台工具的相关支持。例如Mysql数据库表发生信息变更时,通过Canal等组件可以感知数据表的DDL变化情况,离线根据DDL信息变更对应Hive表的信息。
其次是代码提交的校验环节,因为数据质量是一个很冰冷的词汇,代码出了问题就是质量不好,因此如何最大程度上避免人为错误,就成了数据质量保障的重要工作。还是两个方面的思路,一个是交叉检验,既然一个人容易出问题,那么两人及以上来校验,出错的概率就会大幅降低,因此需要搭建一个可行的测试环境,如果没有,可以在线上平台搭建一个相同的测试表,导入少量的数据,这时安排测试人员介入逻辑的检查,并且做相应的回归测试。另一个是进行静态的SQL代码检查,针对大表扫描、空值校验等检查,提示开发人员对应的错误风险。在数据采集环节,还可以加入一些与具体业务紧密相连的监控规则,例如订单拍下时间不大于当天时间,等等。
再次是搭建一些机制完善的辅助平台,例如可以调整任务优先级的调度平台,例如可以准时发现问题并提醒的报警平台,例如可以检测任务依赖死锁的开发平台,等等,针对数据的延迟监控、作业调度的合理性等情况做辅助的技术保障。
最后是要有完善的开发组织工作,针对每一次出现的数据故障,都得安排对应的事件回顾,每周安排例行会议进行典型开发代码的Code Review,有详细的数据问题应对手册以供新入职的开发人员熟悉,等等。
|0x04 数据资产评估
既然提到了数据质量,那么质量便有好坏的区分,像数据平台百万级的数据表,总有高质量与低质量的区分,这时候需要进行相应的数据资产评估,高质量的表需要更高的优先级来进行处理。
这里提供几个参考的制定标准:
数据更新频率,定时更新的肯定好过偶尔更新的;
数据丢失后果,假设某张表数据丢失,会引起重大资产损失,它肯定是好数据;
数据依赖程度,被跨部门依赖、被重要数据依赖,优先级肯定很高;
数据业务属性,带“金额”这种字段的数据,相应的重要性要高;
数据使用频率,有些表被调用次数很多,说明它很有存在的必要性;
数据故障次数,当一张表出过问题时,要及时标注,便于依赖它的任务知道可不可靠。
|0xFF 如何评估数据质量
这里提供一些常见场景:
通过数据资产评估体系,制定高、中、低三种数据标准,以季度为周期,统计三种标准问题次数;
规定详细的数据产出时间,假设数据产出延时,计算延迟时间及问题,并进行记录;
通过产品、客户、数据使用人员及配合部门反馈意见,发现数据不一致等问题,及时反馈,确认后计入问题清单;
通过监控及报警平台,统计每日异常信息,分类产出报告;
针对每位开发人员,测试人员检查发现问题后,如果确认问题存在,计入开发问题,最后汇总常见问题场景;
定期扫描开发代码,发现问题及时发出报警。
--end--