
数据维度爆炸怎么办?详解5大常用的特征选择方法
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

在许多机器学习相关的书里,很难找到关于特征选择的内容,因为特征选择要解决的问题往往被视为机器学习的一个子模块,一般不会单独拿出来讨论。
减少特征数量、降维,使模型泛化能力更强,减少过拟合
增强对特征和特征值之间的理解

二、单变量特征选择
英文:Univariate feature selection。
单变量特征选择能够对每一个特征进行测试,衡量该特征和响应变量之间的关系,根据得分扔掉不好的特征。对于回归和分类问题可以采用卡方检验等方式对特征进行测试。
2.1 Pearson相关系数
英文:Pearson Correlation
import numpy as npfrom scipy.stats import pearsonrnp.random.seed(0)size = 300x = np.random.normal(0, 1, size)print "Lower noise", pearsonr(x, x + np.random.normal(0, 1, size))print "Higher noise", pearsonr(x, x + np.random.normal(0, 10, size))

x = np.random.uniform(-1, 1, 100000)print pearsonr(x, x**2)[0]
-0.00230804707612
2.2 互信息和最大信息系数
英文:Mutual information and maximal information coefficient (MIC)
以上就是经典的互信息公式了。想把互信息直接用于特征选择其实不是太方便:1、它不属于度量方式,也没有办法归一化,在不同数据及上的结果无法做比较;2、对于连续变量的计算不是很方便(X和Y都是集合,x,y都是离散的取值),通常变量需要先离散化,而互信息的结果对离散化的方式很敏感。
from minepy import MINEm = MINE()x = np.random.uniform(-1, 1, 10000)m.compute_score(x, x**2)print m.mic()
2.3 距离相关系数
英文:Distance correlation
#R-code> x = runif (1000, -1, 1)> dcor(x, x**2)[1] 0.4943864
2.4 基于学习模型的特征排序
英文:Model based ranking
from sklearn.cross_validation import cross_val_score, ShuffleSplitfrom sklearn.datasets import load_bostonfrom sklearn.ensemble import RandomForestRegressor#Load boston housing dataset as an exampleboston = load_boston()X = boston["data"]Y = boston["target"]names = boston["feature_names"]rf = RandomForestRegressor(n_estimators=20, max_depth=4)scores = []for i in range(X.shape[1]):score = cross_val_score(rf, X[:, i:i+1], Y, scoring="r2",cv=ShuffleSplit(len(X), 3, .3))scores.append((round(np.mean(score), 3), names[i]))print sorted(scores, reverse=True)

三、线性模型和正则化
from sklearn.linear_model import LinearRegressionimport numpy as npnp.random.seed(0)size = 5000#A dataset with 3 featuresX = np.random.normal(0, 1, (size, 3))#Y = X0 + 2*X1 + noiseY = X[:,0] + 2*X[:,1] + np.random.normal(0, 2, size)lr = LinearRegression()lr.fit(X, Y)#A helper method for pretty-printing linear modelsdef pretty_print_linear(coefs, names = None, sort = False):if names == None:names = ["X%s" % x for x in range(len(coefs))]lst = zip(coefs, names)if sort:lst = sorted(lst, key = lambda x:-np.abs(x[0]))return " + ".join("%s * %s" % (round(coef, 3), name)for coef, name in lst)print "Linear model:", pretty_print_linear(lr.coef_

from sklearn.linear_model import LinearRegressionsize = 100np.random.seed(seed=5)X_seed = np.random.normal(0, 1, size)X1 = X_seed + np.random.normal(0, .1, size)X2 = X_seed + np.random.normal(0, .1, size)X3 = X_seed + np.random.normal(0, .1, size)Y = X1 + X2 + X3 + np.random.normal(0,1, size)X = np.array([X1, X2, X3]).Tlr = LinearRegression()lr.fit(X,Y)print "Linear model:", pretty_print_linear(lr.coef_)
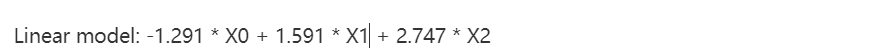
3.1 正则化模型
3.2 L1正则化/Lasso
from sklearn.linear_model import Lassofrom sklearn.preprocessing import StandardScalerfrom sklearn.datasets import load_bostonboston = load_boston()scaler = StandardScaler()X = scaler.fit_transform(boston["data"])Y = boston["target"]names = boston["feature_names"]lasso = Lasso(alpha=.3)lasso.fit(X, Y)print "Lasso model: ", pretty_print_linear(lasso.coef_, names, sort = True)

3.3 L2正则化/Ridge regression
from sklearn.linear_model import Ridgefrom sklearn.metrics import r2_scoresize = 100#We run the method 10 times with different random seedsfor i in range(10):print "Random seed %s" % inp.random.seed(seed=i)X_seed = np.random.normal(0, 1, size)X1 = X_seed + np.random.normal(0, .1, size)X2 = X_seed + np.random.normal(0, .1, size)X3 = X_seed + np.random.normal(0, .1, size)Y = X1 + X2 + X3 + np.random.normal(0, 1, size)X = np.array([X1, X2, X3]).Tlr = LinearRegression()lr.fit(X,Y)print "Linear model:", pretty_print_linear(lr.coef_)ridge = Ridge(alpha=10)ridge.fit(X,Y)print "Ridge model:", pretty_print_linear(ridge.coef_)

4.1 平均不纯度减少
英文:mean decrease impurity
from sklearn.datasets import load_bostonfrom sklearn.ensemble import RandomForestRegressorimport numpy as np#Load boston housing dataset as an exampleboston = load_boston()X = boston["data"]Y = boston["target"]names = boston["feature_names"]rf = RandomForestRegressor()rf.fit(X, Y)print "Features sorted by their score:"print sorted(zip(map(lambda x: round(x, 4), rf.feature_importances_), names),reverse=True)

size = 10000np.random.seed(seed=10)X_seed = np.random.normal(0, 1, size)X0 = X_seed + np.random.normal(0, .1, size)X1 = X_seed + np.random.normal(0, .1, size)X2 = X_seed + np.random.normal(0, .1, size)X = np.array([X0, X1, X2]).TY = X0 + X1 + X2rf = RandomForestRegressor(n_estimators=20, max_features=2)rf.fit(X, Y);print "Scores for X0, X1, X2:", map(lambda x:round (x,3),rf.feature_importances_)

4.2 平均精确率减少
英文:Mean decrease accuracy
from sklearn.cross_validation import ShuffleSplitfrom sklearn.metrics import r2_scorefrom collections import defaultdictX = boston["data"]Y = boston["target"]rf = RandomForestRegressor()scores = defaultdict(list)#crossvalidate the scores on a number of different random splits of the datafor train_idx, test_idx in ShuffleSplit(len(X), 100, .3):X_train, X_test = X[train_idx], X[test_idx]Y_train, Y_test = Y[train_idx], Y[test_idx]r = rf.fit(X_train, Y_train)acc = r2_score(Y_test, rf.predict(X_test))for i in range(X.shape[1]):X_t = X_test.copy()np.random.shuffle(X_t[:, i])shuff_acc = r2_score(Y_test, rf.predict(X_t))scores[names[i]].append((acc-shuff_acc)/acc)print "Features sorted by their score:"print sorted([(round(np.mean(score), 4), feat) forfeat, score in scores.items()], reverse=True)

from sklearn.linear_model import RandomizedLassofrom sklearn.datasets import load_bostonboston = load_boston()#using the Boston housing data.#Data gets scaled automatically by sklearn's implementationX = boston["data"]Y = boston["target"]names = boston["feature_names"]rlasso = RandomizedLasso(alpha=0.025)rlasso.fit(X, Y)print "Features sorted by their score:"print sorted(zip(map(lambda x: round(x, 4), rlasso.scores_),names), reverse=True)

from sklearn.feature_selection import RFEfrom sklearn.linear_model import LinearRegressionboston = load_boston()X = boston["data"]Y = boston["target"]names = boston["feature_names"]#use linear regression as the modellr = LinearRegression()#rank all features, i.e continue the elimination until the last onerfe = RFE(lr, n_features_to_select=1)rfe.fit(X,Y)print "Features sorted by their rank:"print sorted(zip(map(lambda x: round(x, 4), rfe.ranking_), names))

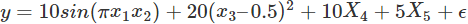
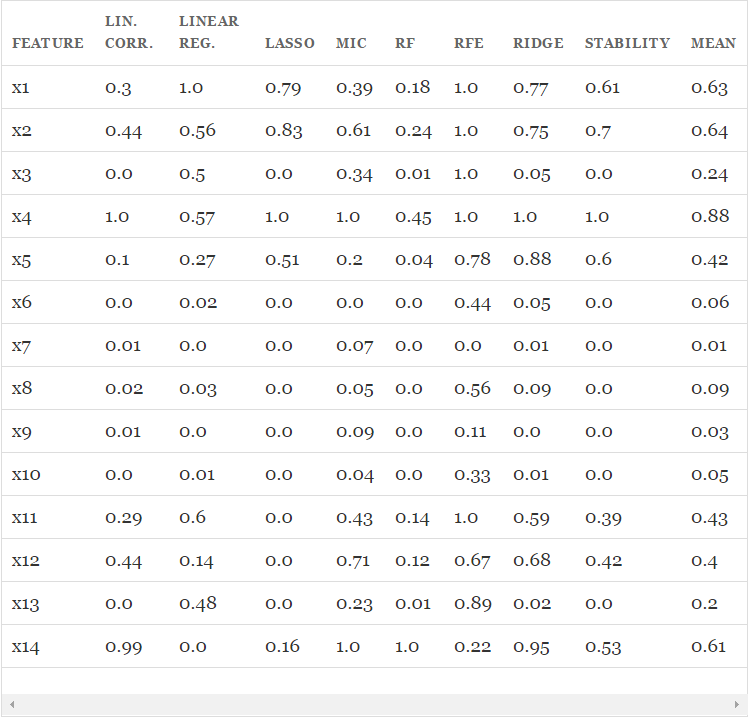
from sklearn.datasets import load_bostonfrom sklearn.linear_model import (LinearRegression, Ridge,Lasso, RandomizedLasso)from sklearn.feature_selection import RFE, f_regressionfrom sklearn.preprocessing import MinMaxScalerfrom sklearn.ensemble import RandomForestRegressorimport numpy as npfrom minepy import MINEnp.random.seed(0)size = 750X = np.random.uniform(0, 1, (size, 14))#"Friedamn #1” regression problemY = (10 * np.sin(np.pi*X[:,0]*X[:,1]) + 20*(X[:,2] - .5)**2 +10*X[:,3] + 5*X[:,4] + np.random.normal(0,1))#Add 3 additional correlated variables (correlated with X1-X3)X[:,10:] = X[:,:4] + np.random.normal(0, .025, (size,4))names = ["x%s" % i for i in range(1,15)]ranks = {}def rank_to_dict(ranks, names, order=1):minmax = MinMaxScaler()ranks = minmax.fit_transform(order*np.array([ranks]).T).T[0]ranks = map(lambda x: round(x, 2), ranks)return dict(zip(names, ranks ))lr = LinearRegression(normalize=True)lr.fit(X, Y)ranks["Linear reg"] = rank_to_dict(np.abs(lr.coef_), names)ridge = Ridge(alpha=7)ridge.fit(X, Y)ranks["Ridge"] = rank_to_dict(np.abs(ridge.coef_), names)lasso = Lasso(alpha=.05)lasso.fit(X, Y)ranks["Lasso"] = rank_to_dict(np.abs(lasso.coef_), names)rlasso = RandomizedLasso(alpha=0.04)rlasso.fit(X, Y)ranks["Stability"] = rank_to_dict(np.abs(rlasso.scores_), names)#stop the search when 5 features are left (they will get equal scores)rfe = RFE(lr, n_features_to_select=5)rfe.fit(X,Y)ranks["RFE"] = rank_to_dict(map(float, rfe.ranking_), names, order=-1)rf = RandomForestRegressor()rf.fit(X,Y)ranks["RF"] = rank_to_dict(rf.feature_importances_, names)f, pval = f_regression(X, Y, center=True)ranks["Corr."] = rank_to_dict(f, names)mine = MINE()mic_scores = []for i in range(X.shape[1]):mine.compute_score(X[:,i], Y)m = mine.mic()mic_scores.append(m)ranks["MIC"] = rank_to_dict(mic_scores, names)r = {}for name in names:r[name] = round(np.mean([ranks[method][name]for method in ranks.keys()]), 2)methods = sorted(ranks.keys())ranks["Mean"] = rmethods.append("Mean")print "\t%s" % "\t".join(methods)for name in names:print "%s\t%s" % (name, "\t".join(map(str,[ranks[method][name] for method in methods])))
评论