
数据维度爆炸?5大常用的特征选择方法详解(下)
Edwin Jarvis | 作者
cnblog博客 | 来源
5
两种顶层特征选择算法
之所以叫做顶层,是因为他们都是建立在基于模型的特征选择方法基础之上的,例如回归和SVM,在不同的子集上建立模型,然后汇总最终确定特征得分。
稳定性选择
稳定性选择是一种基于二次抽样和选择算法相结合较新的方法,选择算法可以是回归、SVM或其他类似的方法。它的主要思想是在不同的数据子集和特征子集上运行特征选择算法,不断的重复,最终汇总特征选择结果,比如可以统计某个特征被认为是重要特征的频率(被选为重要特征的次数除以它所在的子集被测试的次数)。理想情况下,重要特征的得分会接近100%。稍微弱一点的特征得分会是非0的数,而最无用的特征得分将会接近于0。
sklearn在随机lasso和随机逻辑回归中有对稳定性选择的实现。
from sklearn.linear_model import RandomizedLasso
from sklearn.datasets import load_boston
boston = load_boston()
#using the Boston housing data.
#Data gets scaled automatically by sklearn's implementation
X = boston["data"]
Y = boston["target"]
names = boston["feature_names"]
rlasso = RandomizedLasso(alpha=0.025)
rlasso.fit(X, Y)
print "Features sorted by their score:"
print sorted(zip(map(lambda x: round(x, 4), rlasso.scores_),
names), reverse=True)
在上边这个例子当中,最高的3个特征得分是1.0,这表示他们总会被选作有用的特征(当然,得分会收到正则化参数alpha的影响,但是sklearn的随机lasso能够自动选择最优的alpha)。接下来的几个特征得分就开始下降,但是下降的不是特别急剧,这跟纯lasso的方法和随机森林的结果不一样。
能够看出稳定性选择对于克服过拟合和对数据理解来说都是有帮助的:总的来说,好的特征不会因为有相似的特征、关联特征而得分为0,这跟Lasso是不同的。对于特征选择任务,在许多数据集和环境下,稳定性选择往往是性能最好的方法之一。
递归特征消除
递归特征消除的主要思想是反复的构建模型(如SVM或者回归模型)然后选出最好的(或者最差的)的特征(可以根据系数来选),把选出来的特征放到一遍,然后在剩余的特征上重复这个过程,直到所有特征都遍历了。这个过程中特征被消除的次序就是特征的排序。因此,这是一种寻找最优特征子集的贪心算法。
RFE的稳定性很大程度上取决于在迭代的时候底层用哪种模型。例如,假如RFE采用的普通的回归,没有经过正则化的回归是不稳定的,那么RFE就是不稳定的;假如采用的是Ridge,而用Ridge正则化的回归是稳定的,那么RFE就是稳定的。
Sklearn提供了RFE包,可以用于特征消除,还提供了RFECV,可以通过交叉验证来对的特征进行排序。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
boston = load_boston()
X = boston["data"]
Y = boston["target"]
names = boston["feature_names"]
#use linear regression as the model
lr = LinearRegression()
#rank all features, i.e continue the elimination until the last one
rfe = RFE(lr, n_features_to_select=1)
rfe.fit(X,Y)
print "Features sorted by their rank:"
print sorted(zip(map(lambda x: round(x, 4), rfe.ranking_), names))6
一个完整的例子
下面将本文所有提到的方法进行实验对比,数据集采用Friedman #1 回归数据(这篇论文中的数据)。数据是用这个公式产生的:
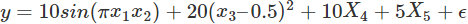
X1到X5是由单变量分布生成的,e是标准正态变量N(0,1)。另外,原始的数据集中含有5个噪音变量 X5,…,X10,跟响应变量是独立的。我们增加了4个额外的变量X11,…X14,分别是X1,…,X4的关联变量,通过f(x)=x+N(0,0.01)生成,这将产生大于0.999的关联系数。这样生成的数据能够体现出不同的特征排序方法应对关联特征时的表现。
接下来将会在上述数据上运行所有的特征选择方法,并且将每种方法给出的得分进行归一化,让取值都落在0-1之间。对于RFE来说,由于它给出的是顺序而不是得分,我们将最好的5个的得分定为1,其他的特征的得分均匀的分布在0-1之间。
from sklearn.datasets import load_boston
from sklearn.linear_model import (LinearRegression, Ridge,
Lasso, RandomizedLasso)
from sklearn.feature_selection import RFE, f_regression
from sklearn.preprocessing import MinMaxScaler
from sklearn.ensemble import RandomForestRegressor
import numpy as np
from minepy import MINE
np.random.seed(0)
size = 750
X = np.random.uniform(0, 1, (size, 14))
#"Friedamn #1” regression problem
Y = (10 * np.sin(np.pi*X[:,0]*X[:,1]) + 20*(X[:,2] - .5)**2 +
10*X[:,3] + 5*X[:,4] + np.random.normal(0,1))
#Add 3 additional correlated variables (correlated with X1-X3)
X[:,10:] = X[:,:4] + np.random.normal(0, .025, (size,4))
names = ["x%s" % i for i in range(1,15)]
ranks = {}
def rank_to_dict(ranks, names, order=1):
minmax = MinMaxScaler()
ranks = minmax.fit_transform(order*np.array([ranks]).T).T[0]
ranks = map(lambda x: round(x, 2), ranks)
return dict(zip(names, ranks ))
lr = LinearRegression(normalize=True)
lr.fit(X, Y)
ranks["Linear reg"] = rank_to_dict(np.abs(lr.coef_), names)
ridge = Ridge(alpha=7)
ridge.fit(X, Y)
ranks["Ridge"] = rank_to_dict(np.abs(ridge.coef_), names)
lasso = Lasso(alpha=.05)
lasso.fit(X, Y)
ranks["Lasso"] = rank_to_dict(np.abs(lasso.coef_), names)
rlasso = RandomizedLasso(alpha=0.04)
rlasso.fit(X, Y)
ranks["Stability"] = rank_to_dict(np.abs(rlasso.scores_), names)
#stop the search when 5 features are left (they will get equal scores)
rfe = RFE(lr, n_features_to_select=5)
rfe.fit(X,Y)
ranks["RFE"] = rank_to_dict(map(float, rfe.ranking_), names, order=-1)
rf = RandomForestRegressor()
rf.fit(X,Y)
ranks["RF"] = rank_to_dict(rf.feature_importances_, names)
f, pval = f_regression(X, Y, center=True)
ranks["Corr."] = rank_to_dict(f, names)
mine = MINE()
mic_scores = []
for i in range(X.shape[1]):
mine.compute_score(X[:,i], Y)
m = mine.mic()
mic_scores.append(m)
ranks["MIC"] = rank_to_dict(mic_scores, names)
r = {}
for name in names:
r[name] = round(np.mean([ranks[method][name]
for method in ranks.keys()]), 2)
methods = sorted(ranks.keys())
ranks["Mean"] = r
methods.append("Mean")
print "\t%s" % "\t".join(methods)
for name in names:
print "%s\t%s" % (name, "\t".join(map(str,
[ranks[method][name] for method in methods])))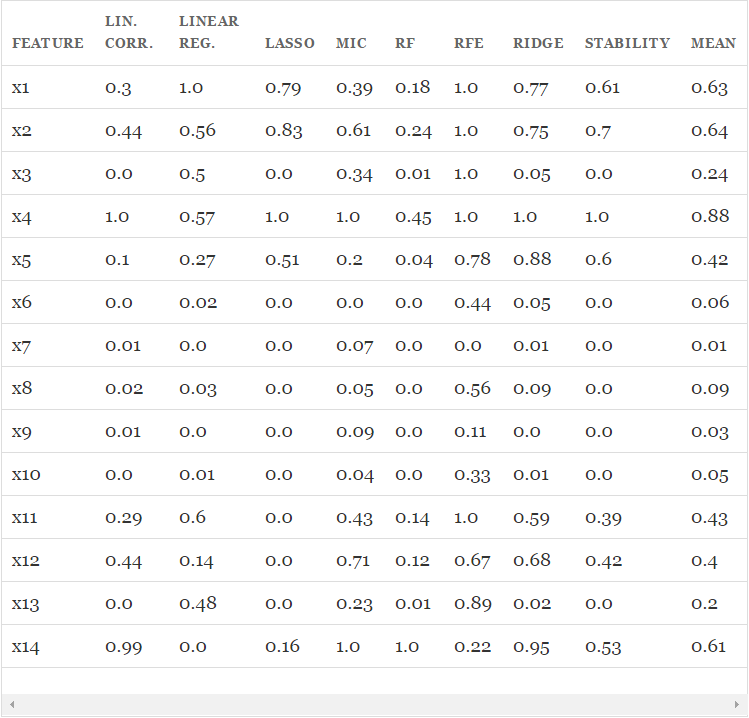
从以上结果中可以找到一些有趣的发现:
特征之间存在线性关联关系,每个特征都是独立评价的,因此X1,…X4的得分和X11,…X14的得分非常接近,而噪音特征X5,…,X10正如预期的那样和响应变量之间几乎没有关系。由于变量X3是二次的,因此X3和响应变量之间看不出有关系(除了MIC之外,其他方法都找不到关系)。
这种方法能够衡量出特征和响应变量之间的线性关系,但若想选出优质特征来提升模型的泛化能力,这种方法就不是特别给力了,因为所有的优质特征都不可避免的会被挑出来两次。
Lasso能够挑出一些优质特征,同时让其他特征的系数趋于0。当如需要减少特征数的时候它很有用,但是对于数据理解来说不是很好用。(例如在结果表中,X11,X12,X13的得分都是0,好像他们跟输出变量之间没有很强的联系,但实际上不是这样的)
MIC对特征一视同仁,这一点上和关联系数有点像,另外,它能够找出X3和响应变量之间的非线性关系。
随机森林基于不纯度的排序结果非常鲜明,在得分最高的几个特征之后的特征,得分急剧的下降。从表中可以看到,得分第三的特征比第一的小4倍。而其他的特征选择算法就没有下降的这么剧烈。
Ridge将回归系数均匀的分摊到各个关联变量上,从表中可以看出,X11,…,X14和X1,…,X4的得分非常接近。
稳定性选择常常是一种既能够有助于理解数据又能够挑出优质特征的这种选择,在结果表中就能很好的看出。像Lasso一样,它能找到那些性能比较好的特征(X1,X2,X4,X5),同时,与这些特征关联度很强的变量也得到了较高的得分。
7
总 结
对于理解数据、数据的结构、特点来说,单变量特征选择是个非常好的选择。尽管可以用它对特征进行排序来优化模型,但由于它不能发现冗余(例如假如一个特征子集,其中的特征之间具有很强的关联,那么从中选择最优的特征时就很难考虑到冗余的问题)。
正则化的线性模型对于特征理解和特征选择来说是非常强大的工具。L1正则化能够生成稀疏的模型,对于选择特征子集来说非常有用;相比起L1正则化,L2正则化的表现更加稳定,由于有用的特征往往对应系数非零,因此L2正则化对于数据的理解来说很合适。
由于响应变量和特征之间往往是非线性关系,可以采用basis expansion的方式将特征转换到一个更加合适的空间当中,在此基础上再考虑运用简单的线性模型。
随机森林是一种非常流行的特征选择方法,它易于使用,一般不需要feature engineering、调参等繁琐的步骤,并且很多工具包都提供了平均不纯度下降方法。它的两个主要问题:
重要的特征有可能得分很低(关联特征问题)
这种方法对特征变量类别多的特征越有利(偏向问题)。尽管如此,这种方法仍然非常值得在你的应用中试一试。
特征选择在很多机器学习和数据挖掘场景中都是非常有用的。在使用的时候要弄清楚自己的目标是什么,然后找到哪种方法适用于自己的任务。当选择最优特征以提升模型性能的时候,可以采用交叉验证的方法来验证某种方法是否比其他方法要好。
当用特征选择的方法来理解数据的时候要留心,特征选择模型的稳定性非常重要,稳定性差的模型很容易就会导致错误的结论。对数据进行二次采样然后在子集上运行特征选择算法能够有所帮助,如果在各个子集上的结果是一致的,那就可以说在这个数据集上得出来的结论是可信的,可以用这种特征选择模型的结果来理解数据。
- END -
本文为转载分享&推荐阅读,若侵权请联系后台删除