
3个Tricks帮你提升你Debug Pytorch的效率
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者:Adrian Wälchli
编译:ronghuaiyang AI公园
好的工具和工作习惯可以极大的提升工作效率。
每一个深度学习项目都是不同的。不管你有多少经验,你总会遇到新的挑战和意想不到的行为。你在项目中运用的技巧和思维方式将决定你多快发现并解决这些阻碍成功的障碍。
从实践的角度来看,深度学习项目从代码开始。一开始组织它很容易,但是随着项目的复杂性的增加,在调试和完整性检查上花费的时间会越来越多。令人惊讶的是,其中很多都可以自动完成。在这篇文章中,我将告诉你如何去做。
找出为什么你的训练损失没有降低 实现模型自动验证和异常检测 使用PyTorch Lightning节省宝贵的调试时间

为了演示,我们将使用一个简单的MNIST分类器的例子,这里有几个bug:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=0)
return output
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (x, y) in enumerate(train_loader):
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
loss = F.nll_loss(output, y)
loss.backward()
optimizer.step()
if batch_idx % 10 == 0:
print(f'Epoch: {epoch} [{100. * batch_idx / len(train_loader):.0f}%]\tLoss: {loss.item():.6f}')
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for x, y in test_loader:
x, y = x.to(device), y.to(device)
output = model(x)
test_loss += F.nll_loss(x, y, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(y.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print(
f'\nTest set: Average loss: {test_loss:.4f},'
f' Accuracy: {100. * correct / len(test_loader.dataset):.0f}%\n'
)
def main():
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(128., 1.),
])
train_dataset = MNIST('./data', train=True, download=True, transform=transform)
test_dataset = MNIST('./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=1)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=1)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=1.0)
scheduler = StepLR(optimizer, step_size=1, gamma=0.7)
epochs = 14
for epoch in range(1, epochs + 1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
if __name__ == '__main__':
main()
这是最原味的MNIST PyTorch代码,改编自github.com/pytorch/examples,如果你运行这段代码,你会发现损失不降,并且在第一个epoch之后,测试循环会崩溃。怎么回事?
Trick 0: 组织好你的PyTorch代码结构
在调试此代码之前,我们将把它组织成Lightning格式。PyTorch Lightning将所有的boilerplate/engineering代码自动放在一个Trainer对象中,并整齐地将所有的实际的研究代码放到了LightningModule中,这样我们就可以专注于最重要的部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
from torch.optim.lr_scheduler import StepLR
import pytorch_lightning as pl
from pytorch_lightning.metrics.functional.classification import accuracy
class LitClassifier(pl.LightningModule):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
self.example_input_array = torch.rand(5, 1, 28, 28)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=0)
return output
def dataloader(self, train=False):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(128, 1)
])
dataset = datasets.MNIST('data', train=train, download=True, transform=transform)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=64, pin_memory=True, shuffle=True, num_workers=1)
return dataloader
def train_dataloader(self):
return self.dataloader(train=True)
def val_dataloader(self):
return self.dataloader(train=False)
def training_step(self, batch, batch_nb):
x, y = batch
output = self(x)
loss = F.nll_loss(output, y)
acc = accuracy(torch.max(output, dim=1)[1], y)
self.log('train_loss', loss, on_step=True)
self.log('train_acc', acc, on_step=True, prog_bar=True)
return loss
def validation_step(self, batch, batch_nb):
x, y = batch
output = self(x)
loss = F.nll_loss(x, y)
acc = accuracy(torch.max(output, dim=1)[1], y)
self.log('val_loss', loss, on_epoch=True, reduce_fx=torch.mean)
self.log('val_acc', acc, on_epoch=True, reduce_fx=torch.mean)
def configure_optimizers(self):
optimizer = torch.optim.Adadelta(model.parameters(), lr=1.0)
scheduler = StepLR(optimizer, step_size=1, gamma=0.7)
return [optimizer], [scheduler]
if __name__ == "__main__":
model = LitClassifier()
trainer = pl.Trainer(gpus=1)
trainer.fit(model)
你能找出这段代码中的所有bug吗?
Lightning负责处理许多经常导致错误的工程模式:训练、验证和测试循环逻辑、将模型从训练模式切换到eval模式或反之、将数据移动到正确的设备、检查点、日志记录等等。
Trick 1: 检查验证循环的完整性
如果我们运行上面的代码,我们会立即得到一条错误消息,说在验证步骤的第65行中大小不匹配。
...
---> 65 loss = F.nll_loss(x, y)
66 acc = accuracy(torch.max(output, dim=1)[1], y)
67 self.log('val_loss', loss, on_epoch=True,
reduce_fx=torch.mean)
...RuntimeError: 1only batches of spatial targets supported (3D tensors) but got targets of size: : [64]
如果你注意到了,Lightning在训练开始前运行了两个验证步骤。这不是一个bug,而是一个[特性](https://pytoring-lightning.readthedocs.io/en/stable/debugging.html #设置验证健全步骤的数量)!这实际上为我们节省了大量的时间,否则,如果错误发生在长时间的训练之后,我们就会浪费很多时间。Lightning在开始时检查验证循环,这让我们可以快速修复错误,因为很明显,现在应该读取第65行:
loss = F.nll_loss(output, y)
就像在训练步骤中一样。
这是一个很容易解决的问题,因为堆栈跟踪告诉我们哪里出了问题,而且这是一个明显的错误。修正后的代码现在运行没有错误,但如果我们查看进度条中的损失值,我们会发现它停留在2.3。这可能有很多原因:错误的优化器,糟糕的学习率或学习率策略,错误的损失函数,数据的问题等等。
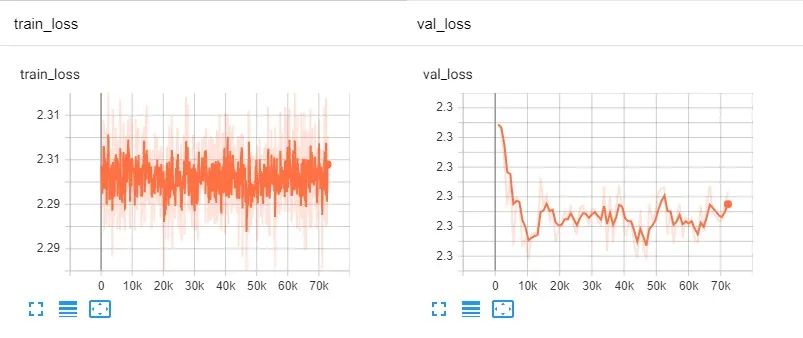
PyTorch Lightning内置了TensorBoard ,在这个例子中,训练损失和验证损失都没有减少。
Trick 2: 记录训练数据的直方图
经常检查输入数据的范围是很重要的。如果模型权重和数据是非常不同的量级,它可能导致没有或非常低的学习进展,并在极端情况下导致数值不稳定。例如,当以错误的顺序应用数据扩充或忘记了归一化时,就会发生这种情况。我们的例子中是这样的吗?我们应该可以通过打印最小值和最大值来找出答案。但是等等!这不是一个好的解决方案,因为它会不必要地污染代码,并且在需要的时候需要花费太多的时间来重复它。更好的方法:写一个回调类来为我们完成它!
class InputMonitor(pl.Callback):
def on_train_batch_start(self, trainer, pl_module, batch, batch_idx, dataloader_idx):
if (batch_idx + 1) % trainer.log_every_n_steps == 0:
x, y = batch
logger = trainer.logger
logger.experiment.add_histogram("input", x, global_step=trainer.global_step)
logger.experiment.add_histogram("target", y, global_step=trainer.global_step)
# use the callback like this:
model = LitClassifier()
trainer = pl.Trainer(gpus=1, callbacks=[InputMonitor()])
trainer.fit(model)
PyTorch Lightning中的回调可以保存可以注入训练器的任意代码。这个在进入训练步骤之前计算输入数据的直方图。将此功能封装到回调类中有以下优点:
它与你的研究代码是分开的,没有必要修改你的LightningModule! 它是可移植的,因此可以在未来的项目中重用,并且只需要更改两行代码:导入回调,然后将其传递给Trainer。 可以通过子类化或与其他回调组合来扩展。
现在有了新的回调功能,我们可以打开TensorBoard并切换到“直方图”选项卡来检查训练数据的分布情况:
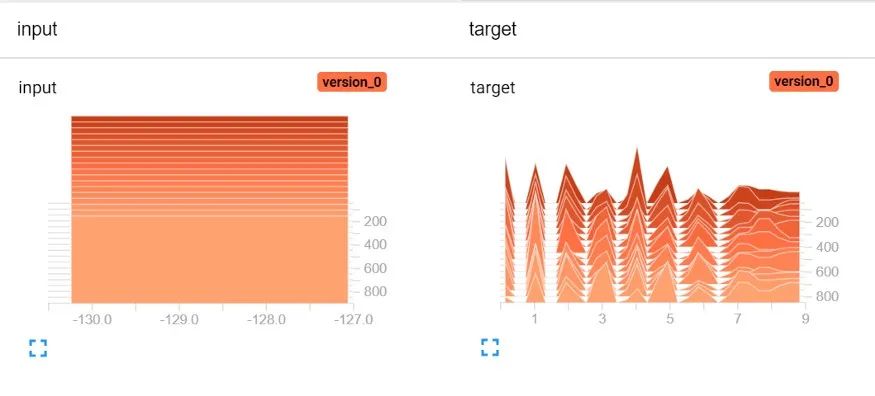
目标在范围[0,9]中,这是正确的,因为MNIST有10位的类,但是图像的值在-130到-127之间,这是错误的!我们很快发现在第41行归一化中有一个问题:
transforms.Normalize(128, 1) # wrong normalization
这两个数字应该是输入数据的平均值和标准差(在我们的例子中,是图像中的像素)。为了解决这个问题,我们添加了真实的平均值和标准差,也命名了参数,以使其更清楚:
transforms.Normalize(mean=0.1307, std=0.3081)
我们可以查一下这些数字,因为它们是已知的。对于你自己的数据集,你必须自己计算。
经过归一化处理后,像素点的均值为0,标准差为1,就像分类器的权重一样。我们可以通过看TensorBoard的直方图来确认这一点。
Trick 3: 在前向传播中检测异常
在修复了归一化问题之后,我们现在也可以在TensorBoard中得到预期的直方图。但不幸的是,损失仍然没有降低。还是有问题。我知道数据是正确的,开始查找错误的一个好地方是网络的前向路径。一个常见的错误来源是操纵张量形状的操作,如permute、reshape、view、flatten等,或应用于一维的操作,如softmax。当这些函数被应用在错误的尺寸或错误的顺序上时,我们通常会得到一个形状不匹配的错误,但情况并不总是如此!这些bug很难追踪。
让我们来看看一种技术,它可以让我们快速地检测出这些错误。

想法很简单:如果我们改变第n个输入样本,它应该只对第n个输出有影响。如果其他输出i≠n也发生变化,则模型会混合数据,这就不好了!一个可靠的方法来实现这个测试是计算关于所有输入的第n个输出的梯度。对于所有i≠n(上面动画中为红色),梯度必须为零,对于i = n(上面动画中为绿色),梯度必须为非零。如果满足这些条件,则模型通过了测试。下面是n = 3时的实现:
# examine the gradient of the n-th minibatch sample w.r.t. all inputs
n = 3
# 1. require gradient on input batch
example_input = torch.rand(5, 1, 28, 28, requires_grad=True)
# 2. run batch through model
output = model(example_input)
# 3. compute a dummy loss on n-th output sample and back-propagate
output[n].abs().sum().backward()
# 4. check that gradient on samples i != n are zero!
# sanity check: if this does not return 0, you have a bug!
i = 0
example_input.grad[i].abs().sum().item()
这里是同样的Lightning Callback:
class CheckBatchGradient(pl.Callback):
def on_train_start(self, trainer, model):
n = 0
example_input = model.example_input_array.to(model.device)
example_input.requires_grad = True
model.zero_grad()
output = model(example_input)
output[n].abs().sum().backward()
zero_grad_inds = list(range(example_input.size(0)))
zero_grad_inds.pop(n)
if example_input.grad[zero_grad_inds].abs().sum().item() > 0
raise RuntimeError("Your model mixes data across the batch dimension!")
# use the callback like this:
model = LitClassifier()
trainer = pl.Trainer(gpus=1, callbacks=[CheckBatchGradient()])
trainer.fit(model)
将这个测试应用到LitClassifer上,可以立即发现它混合了数据。现在知道了我们要找的是什么,我们很快就发现了正向传播中的一个错误。第35行中的softmax被应用到了错误的维度上:
output = F.log_softmax(x, dim=0)
应该是:
output = F.log_softmax(x, dim=1)
好了,分类器开始工作了!训练和验证损失迅速降低。

总结
编写好的代码从组织开始。PyTorch Lightning通过删除围绕训练循环工程、检查点保存、日志记录等的样板代码来处理这一部分。剩下的是实际的研究代码:模型、优化和数据加载。如果某些东西没有按照我们期望的方式工作,很可能是代码的这三部分中的某一部分有错误。在这篇博文中,我们实现了两个回调,帮助我们1)监控进入模型的数据,2)验证我们网络中的各层不会在批处理维度上混合数据。回调的概念是向现有算法添加任意逻辑的一种非常优雅的方式。一旦实现,就可以通过更改两行代码轻松地将其集成到新项目中。

英文原文:https://medium.com/@adrian.waelchli/3-simple-tricks-that-will-change-the-way-you-debug-pytorch-5c940aa68b03
下载1:速查表
在「AI算法与图像处理」公众号后台回复:速查表,即可下载21张 AI相关的查找表,包括 python基础,线性代数,scipy科学计算,numpy,kears,tensorflow等等
下载2 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
觉得有趣就点亮在看吧
