
CVPR2022 | RepLKNet: 大核卷积+结构重参数让CNN再次崛起

卷积网络的 kernel size 可以多大?答案是:25x25 就很好,31x31 甚至更好。旷视科技的研究员发现卷积网络的基础设计维度——kernel size——对模型的性能特别是分割和检测等下游任务至关重要。作者提出一种大量采用超大卷积核的模型——RepLKNet,在结构重参数化、depthwise 卷积等设计要素的加持下,超大卷积既强又快,在目标检测和语义分割等任务上超过 Swin Transformer 而且远超传统小卷积模型。比如,在ImageNet数据集上RepLKNet取得了87.8%的top1精度;在ADE20K数据集上,RepLKNet取得了56.0%mIoU指标。在部署落地方面,旷视科技提出一种专门为超大核卷积优化的卷积算法以实现大幅加速,所以 RepLKNet 不但 FLOPs 低,实际运行也快,对工业应用非常友好。
1大核卷积指导方针
大核卷积的实用往往伴随着性能与速度的下降,为此,我们总结了5条大核卷积高效使用的指标方针。
大核深度卷积可以更高效
一般来讲,大核卷积计算量非常大。这是因为核尺寸会导致参数量与FLOPs的二次提升,而这个弊端可以通过Depth-wise卷积解决。比如,RepLKNet的的卷积核从提升到了,但FLOPs与参数量仅增加18.6%与10.4%。实际上,计算复杂度主要由卷积主导。
也许有人会说:深度卷积计算效率低。对于常规深度卷积确实如此,这是因为其存算比(每次只有9个乘法)过低导致;而大核深度卷积的存算比更高(深度卷积,每次有121个乘法),其实际推理延迟并未大幅提升。
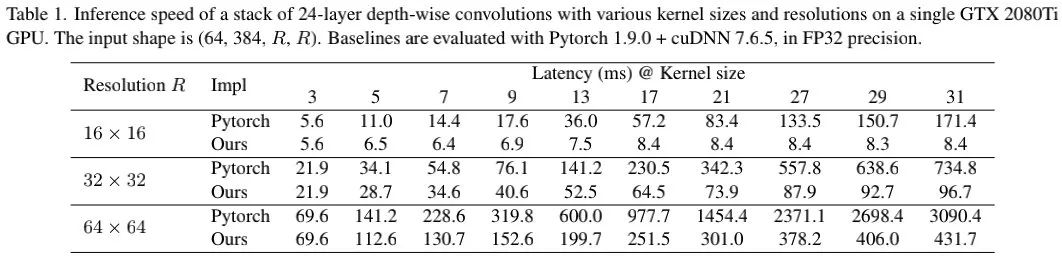
不幸的是,现有深度学习框架对大核卷积的支持很差,见上表。我们尝试了几种方法进行优化加速,最终选择了block-wise(inverse) implicit gemm方案,该方案已集成到MegEngine。从上表可以看到:相比pytorch的实现,MegEngine优化的方案速度更快,推理延迟从49.5%下降到了12.3%,近似正比于FLOPs。
关于大核卷积的实现优化背后原理可以参考如下链接:凭什么 31x31 大小卷积核的耗时可以和 9x9 卷积差不多(https://zhuanlan.zhihu.com/p/479182218)。
恒等跳过连接对于大核卷积非常重要
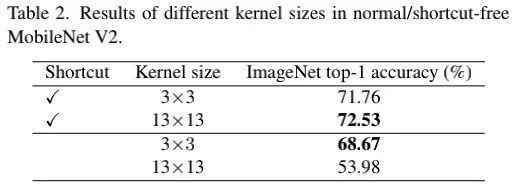
为验证此,我们采用MobileNetV2作为基线(它同时具有深度卷积与跳过连接)。对于大核版本,我们采用深度卷积替换原始的深度卷积。上表给出了性能对比,从中可以看到:(1) 大核卷积+短连接可以提升其性能达0.77%;(2)移除短连接后,大核卷积的性能仅为53.98%。
小核重参数有助于弥补优化问题
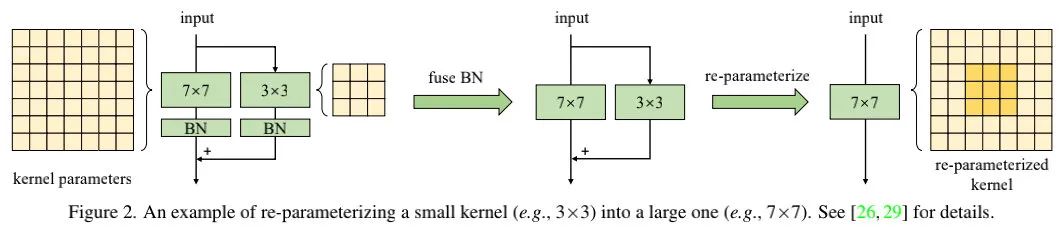
我们将MobileNetV2中的卷积替换为并采用结构重参数技术,可参考上图。完成训练后,我们再参考结构重参数进行模块折叠,即转换后的模型将不再包含小核等两者等价。关于结构重参数化相关的知识可以参考作者的RepVGG与DBB,这两篇paper的解读可参考:
RepVGG|让你的ConVNet一卷到底,plain网络首次超过80%top1精度
CVPR2021|“无痛涨点”的ACNet再进化,清华大学&旷视科技提出Inception类型的DBB
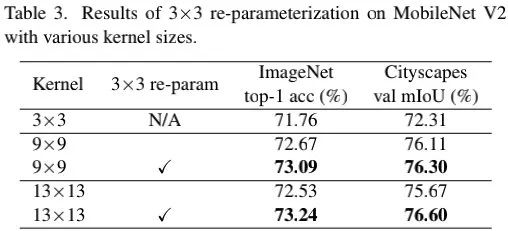
从上表结果可以看到:将卷积核尺寸从9提升到13反而会带来性能下降;而引入结构重参数化后则可以解决该问题。类似的现象在语义分割任务也再次发生。也就是说,通过结构重参数技术,提升卷积核尺寸将不再导致性能下降。
大核卷积对下游任务的提升更明显
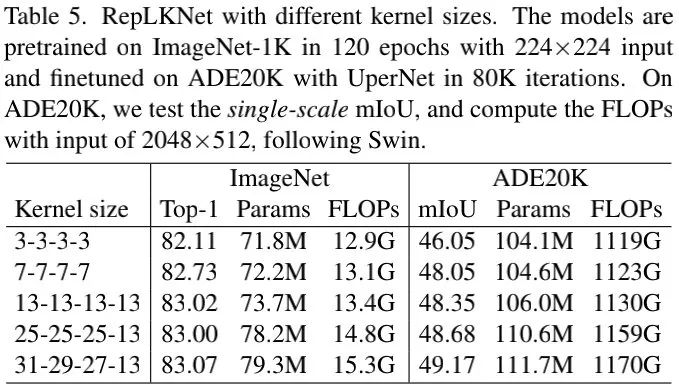
前面Table3的结果表明:对于ImageNet分类卷积核从3提升到9带来的性能提升为1.33%,而Cityscapes的性能提升则达到了3.99%。上表Table5也带来类似的趋势,这意味着:具有相似ImageNet分类性能的模型可能具有完全不同的下游任务迁移能力。
那么,其背后的根因是什么呢?首先,大核设计可以大幅提升感受野(Effective Receptive Fields, ERFs),而感受野对于下游任务非常重要;其次,我们认为大核设计可以为网络带来更多的形状偏置。
大核卷积对于小图仍然有效
为验证此,我们将MobieNetV2最后一阶段的深度卷积尺寸提升到7和13,因此卷积核尺寸比特征尺寸相当、甚至更大。
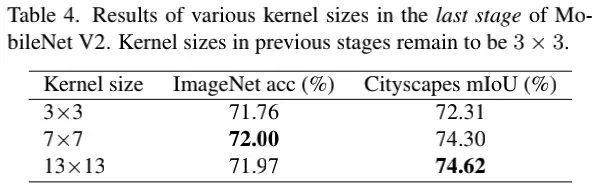
从上表可以看到:尽管最后阶段的卷积已有包含非常大的感受野,进一步提升感受野还可以进一步提升下游任务的性能。
2RepLKNet: A Large Kernel Architecture
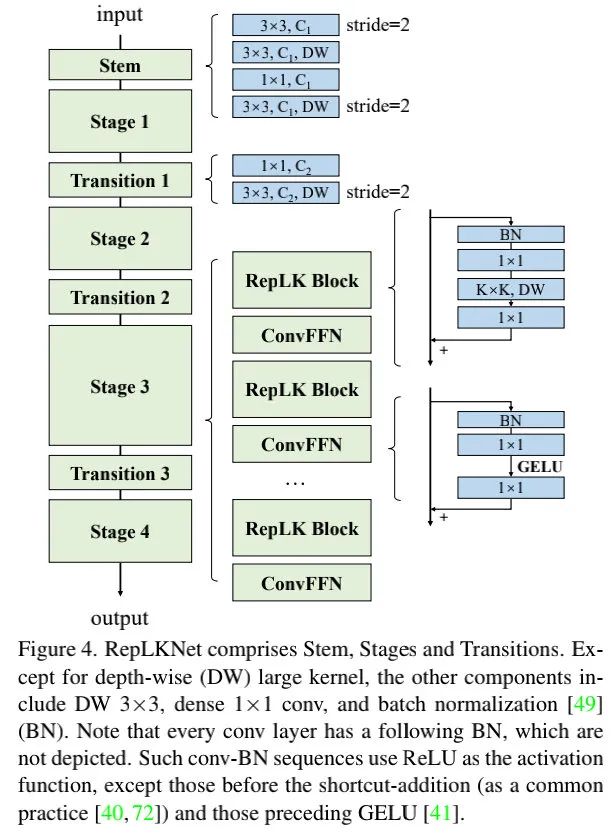
上图给出了RepLKNet的架构示意图,我们对不同模块进行简单介绍:
Stem:它由常规卷积+深度卷积以及卷积构成; Stage:每个阶段均包含多个RepLK模块,每个RepLK由跳过连接与大核卷积构成,ConvFFN部分则是卷积+GELU+BN构成,即采用BN替换了LN; Transition Block:该模块置于不同阶段之间,用于调整特征分辨率和通道数。它由卷积和深度卷积构成。 总而言之,RepLKNet的超参包含每个阶段的RepLK模块数B与每个阶段的通道维度C以及核尺寸K。
在网络结构配置方面,我们固定,调整不同阶段的卷积核尺寸以观测其性能。在核尺寸方面,我们并未精心调整,只是随意设置为并分别对应RepLKNet-13/25/31。与此同时,我们还设计了两个小核模型RepLKNet-3/7。
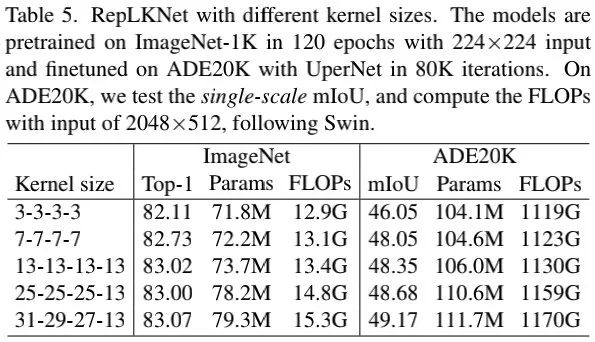
上表给出了所提方案不同配置的性能、参数量以及FLOPs,可以看到:
在ImageNet任务上,尽管核尺寸从3提升到了13改善了性能,但并未进一步提升; 在ADE20K任务上,核尺寸从地阿莱了0.82mIoU指标提升,参数量与FLOPs仅增加5.3%与3.5%。这进一步说了大核对于下游任务的重要性。
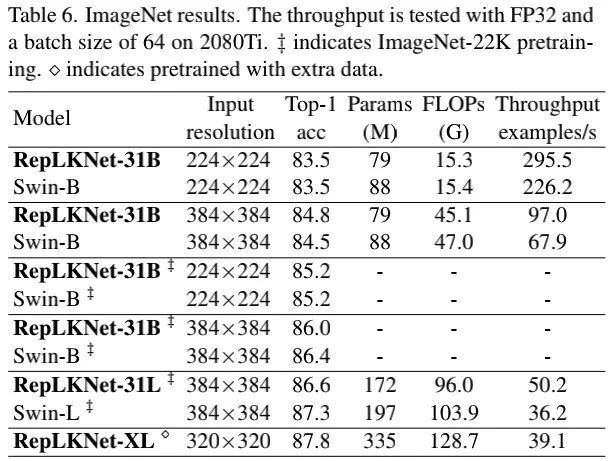
上表给出了所提方案与Swin的性能对比,从中可以看到:
RepLKNet表现出了非常优异的精度与效率均衡; 当仅使用ImageNet-1K训练时,RepLKNet-31B取得了84.8%,以0.3%高于SwinB,同时推理速度快43%; 当采用额外数据预训练后,RepLKNet-XL取得了87.8%的性能,尽管FLOPs高于SwinL,但推理速度更快。
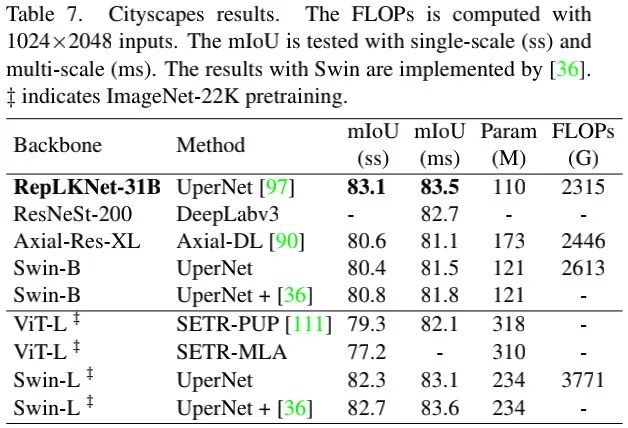
上表给出了Cityscapes任务上的性能对比,从中与看到:ImageNet预训练的RepLKNet-31B比SwinB指标高2.7mIoU,同时比ImageNet-22K预训练的SwinL高0.4mIoU。

上表给出了ADE20K任务上的性能对比,从中可以看到:
无论是相比1K还是22K预训练的SwinB,RepLKNet-31B均具有更优的性能; 当采用MegData73M数据预训练后,RepLKNet-XL取得了56.0mIoU指标。
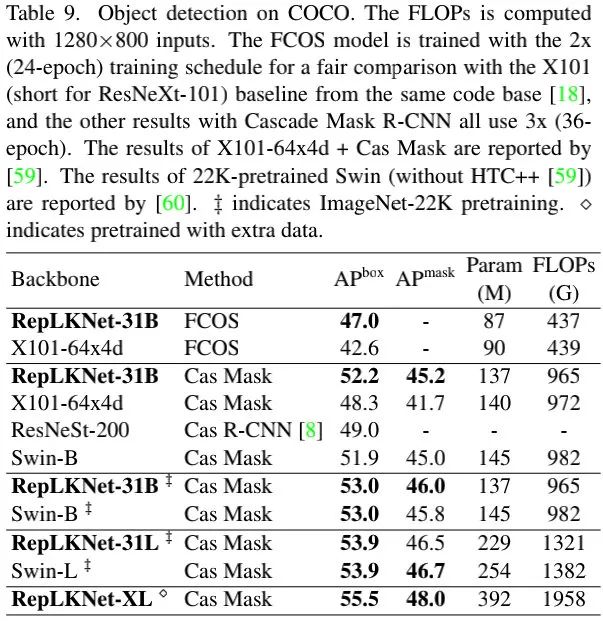
上表给出了COCO检测任务上的性能对比,从中可以看到:
相比ResNeXt-101-64x4d,RepLKNet的指标提升达4.4mAP,同时参数量更少; 相比Swin,RepLKNet取得了更高的mAP指标,同时参数量与FLOPs更低; 值得一提的是,RepLKNet-XL取得了55.5mAP指标。
3相关阅读
优于ConvNeXt,南开&清华开源基于大核注意力的VAN架构 “文艺复兴” ConvNet卷土重来,压过Transformer!FAIR重新设计纯卷积新架构 RepVGG|让你的ConVNet一卷到底,plain网络首次超过80%top1精度 CVPR2021|“无痛涨点”的ACNet再进化,清华大学&旷视科技提出Inception类型的DBB “重参数宇宙”再添新成员:RepMLP,清华大学&旷视科技提出将重参数卷积嵌入到全连接层 凭什么 31x31 大小卷积核的耗时可以和 9x9 卷积差不多?(https://zhuanlan.zhihu.com/p/479182218)
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
