卷积核扩大到51x51,新型CNN架构SLaK反击Transformer
作者:刘世伟
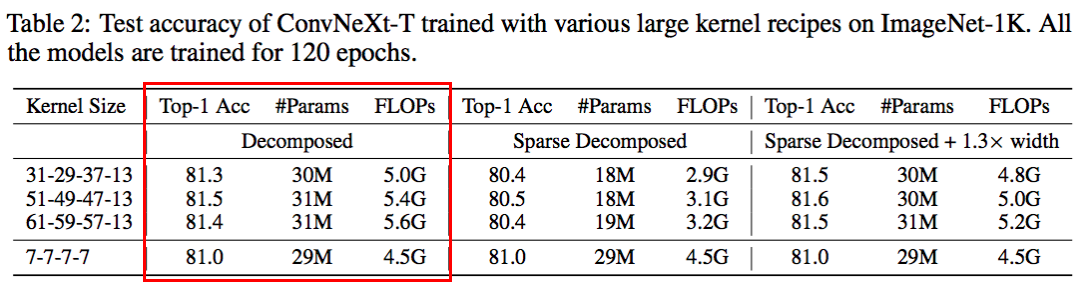
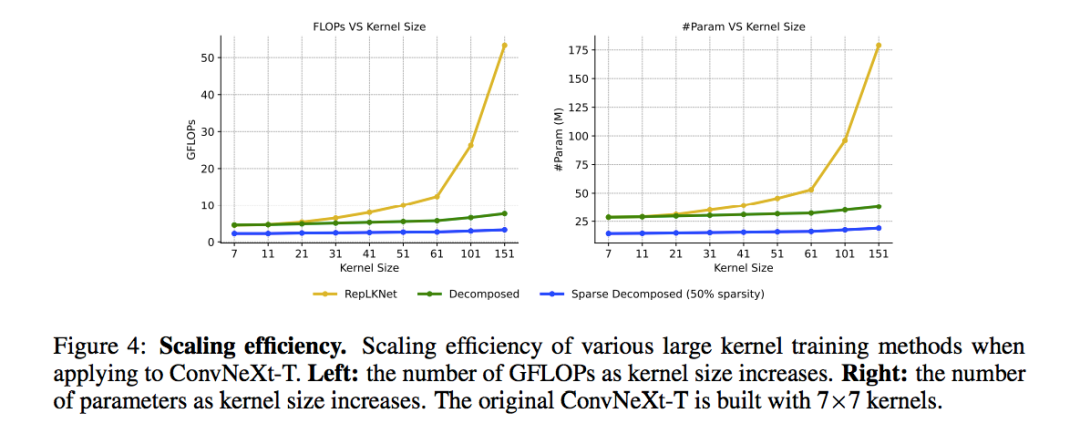
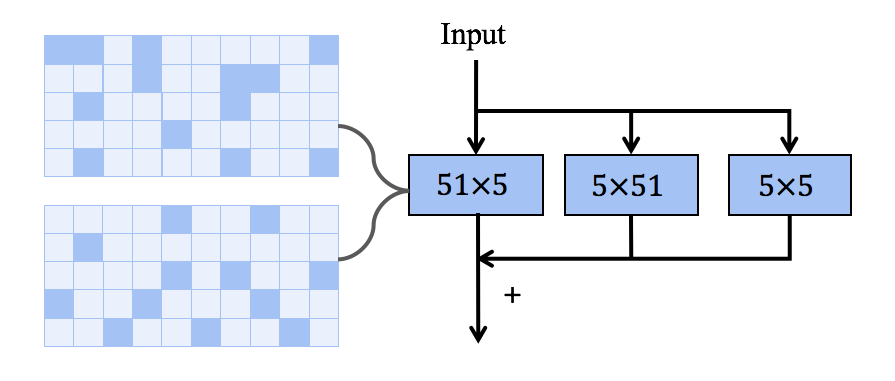
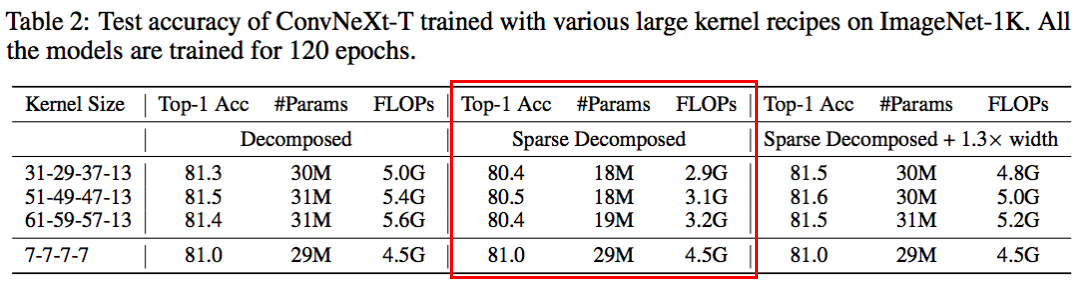
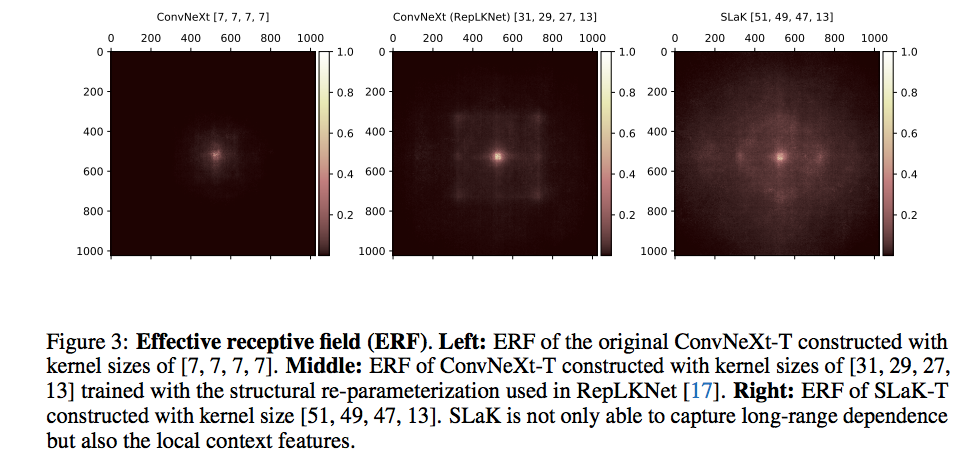
本文分析了是否可以通过策略性地扩大卷积来消除与Transformer的性能差距。

论文:https://arxiv.org/pdf/2207.03620.pdf Pytorch 开源代码:https://github.com/VITA-Group/SLaK

© THE END
转载请联系原公众号获得授权

点个在看 paper不断!
评论
 下载APP
下载APP作者:刘世伟
本文分析了是否可以通过策略性地扩大卷积来消除与Transformer的性能差距。
© THE END
转载请联系原公众号获得授权
点个在看 paper不断!