
谁说有序链表不能进行二分查找?!
关注公众号“彤哥读源码”,解锁更多源码、基础、架构知识!

前言
本文收录于专辑:http://dwz.win/HjK,点击解锁更多数据结构与算法的知识。
你好,我是彤哥。
上一节,我们一起学习了关于哈希的一切,特别是哈希表的进化过程,相信通过上一节的学习,你一定可以从头到尾完整地给面试官讲讲哈希表是如何发展到如今这一步的。
但是,难道HashMap的终极形态只能通过“数组+链表+红黑树”的形式实现吗?有没有可替代方案?为什么Java没有使用你说的这种替代方案呢?
本节,我们就来学习另外一种数据结构——跳表,关于跳表的内容,我将分成两节完成,第一节介绍跳表的演进过程,第二节代码实现跳表,并改写HashMap。
好了,让我们先进入跳表第一小节的学习。
有序数组
大家都知道数组是可以支持随机访问的,也就是通过下标可以快速地定位到元素,时间复杂度是O(1)。
那么,这个随机访问的特性除了根据下标查找元素,还具有哪些用处呢?
试想,如果一个数组是有序的,我要查找某个指定的元素,如何才能做到最快速地查找出来呢?

简单的方法,从头开始遍历整个数组,遇到了要查找的元素就返回,比如,查找8这个元素,要走6次才能查找到,要查找10这个元素更夸张,需要8次。
所以,这种方式的查找元素的时间复杂度为O(n)。

快速的方法,因为数组本身是有序的,所以,我们可以使用二分查找,先从中间开始查找,如果指定元素比中间的元素小,再在左半边查找,如果指定元素比中间元素大,则在右半边查找,依次进行,直到找到指定元素。比如,查找8这个元素,先定位到中间(7/2=3)的位置,下一次查找让左指针加1,把4号位置作为左指针,中间的位置变为(4+(7-4)/2=5)的位置,查找到8这个元素,一共只需要2次。
使用二分查找,效率提升了不止一星半点,即使最坏的情况也只需要log(n)的时间复杂度。

有序链表
上面我们介绍了有序数组的快速查找,下面我们再来看看有序链表的情况。

上面是一个有序链表,此时,我要查找8这个元素,只能从链表头开始查找,直到遇到8为止,时间复杂为O(n),似乎没有什么更好的办法了。

让我们考虑有序数组和有序链表的不同之处,有序数组之所以能够实现可以直接定位到中间元素,得意于其可以通过索引(下标)快速访问的特性,那么,我们给有序链表加上索引是不是就可以实现类似的功能了呢?
答案是肯定的,这种具有索引的有序链表就是跳表,下面有请跳表登场。
跳表
第一个问题:怎么给有序链表加索引呢?
这里,需要增加一个“层”的概念,假设原始链表的层级为0,那么,在其中选择一些元素向上延伸,形成第1层索引,同样地,在第1层索引的基础上,再选择一些元素向上延伸,形成第2层索引,直到你觉得索引的层数差不多了为止,没错,跳表就是这么随意,你满意就好^^
假设,针对上面的有序链表,我加了这么一些索引:

第二个问题:从哪开始访问这个跳表呢?6?3?1?9?
好像都不行,所以,还要增加一个特殊的节点——头节点,放在0号元素的前面,比如,上面的跳表增加头节点之后的样子如下:
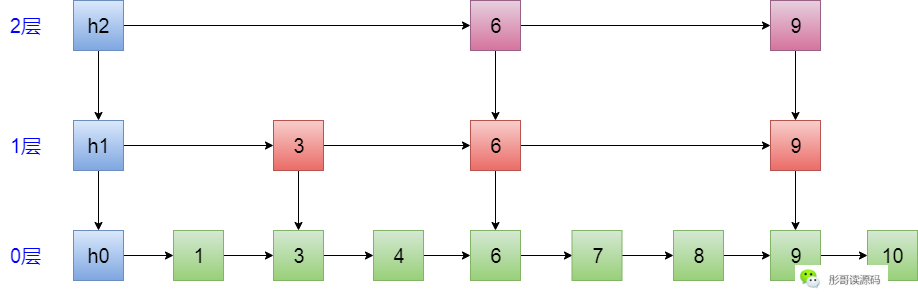
此时,只要从h2这个节点开始,就能很快速地查找到跳表中的任意一个元素。
比如,要查找8这个元素,h2先向右看一下,咦,是6,比8小,跳到6这个位置,再向右看一下,啊,是9了,比8大了,所以,不能跳过去,向下跳一步,跳到第1层6的位置,向右看一下,又是9,不能跳过去,再向下跳一步,到第0层的6,既然,到第0层,那只能按照链表依次往后遍历了,直到遇到8为止,整个过程如下:
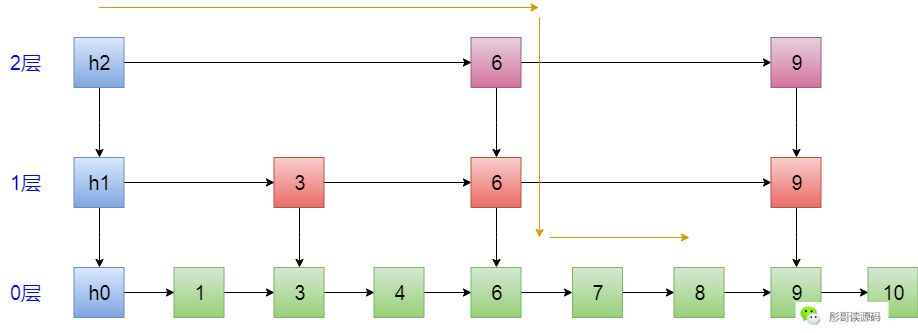
可以看到,整个过程就是跳呀跳呀跳,所以得名——跳表。
这里的元素个数比较少,可能还看不出太大的优势,试想,如果元素非常多,每两个元素向上形成一个索引,每两个索引再向上形成一个索引,最后,就类似于一颗平衡二叉树了:
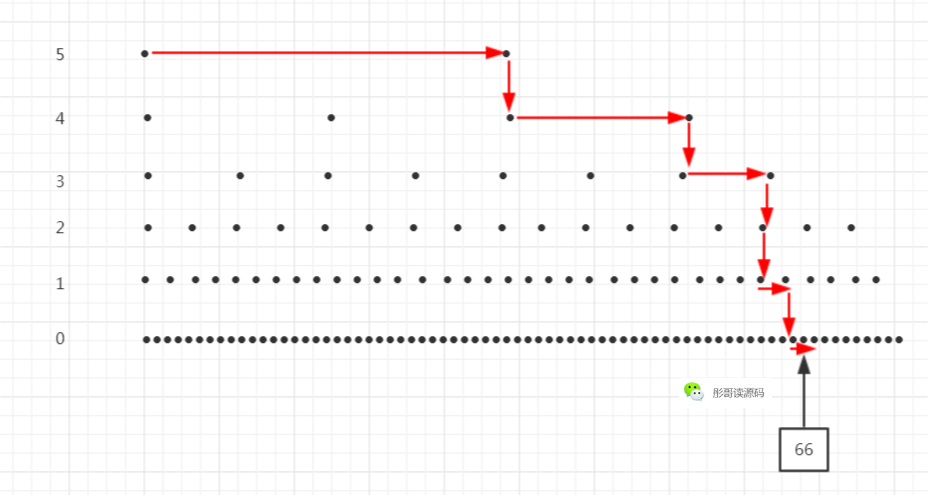
可以看到,每次查找可以减少一半的搜索范围,所以,跳表的查询时间复杂度为O(log n)。
但是,实际情况是不可能使用这种完全平衡的跳表的,因为,如果要保持平衡的特性,在插入元素或删除元素的时候势必需要做再平衡的操作,这样就大大地降低了效率,所以,一般地,我们使用随机来决定一个元素或者索引要不要产生索引。
第三个问题:索引何时产生呢?
最好的时机莫过于插入元素的时候,因为在插入元素之后的下一步就要立马使用索引了,为什么这样说呢?因为不管是插入、删除还是查询,其实,都要先走查询找到那个元素才能进行下一步操作。说白了,就是不管什么操作,都要查询,是查询就要走索引,要走索引就要先建索引,要建索引那就在插入元素的时候。
OK,下面我将使用一步一图的方式,带你领略跳表创建的完整过程:
初始状态,只有一个头节点h0(不,还有一个彤哥读源码的水印,调皮^^)。

插入一个元素4,放在h0后面,并随机决定要不要向上形成索引,结果是不形成索引。

插入一个元素3,从h0开始查找,h0的下一个元素是4,比3大,所以,3放在h0和4之间,然后询问要不要形成索引,随机决定说要形成索引,此时,3向上形成索引,同时,h0也要向上形成索引h1,结果如下:

插入一个元素9,从h1开始查找,依次经过h1->3->3->4,都没有找到位置,最后插入到4后面,并询问要不要形成索引,随机决定说我要形成索引,而且我要形成2层索引(最多比当前层数多1),然后就变成了这个样子:

接着,插入了元素1和7,它们都无惊无喜,没有形成索引:
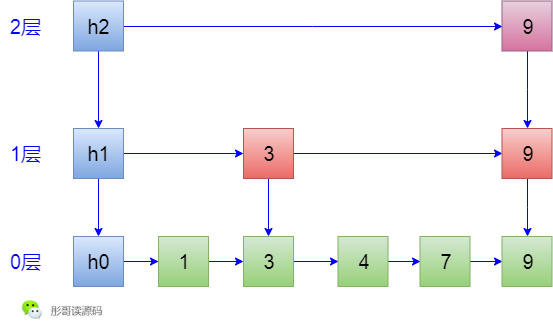
插入元素6,根据索引,查找路线为,h2->h1->3->3->4,咦,发现4下一个是7了,所以,6放在4和7之间,然后,决定要不要形成索引,随机决定说我要形成索引,而且我也要形成2层索引,这时候就很麻烦了,在形成6这个元素索引的时候,需要修改3->9这条线,还要修改h2->9这条线,生成的结果如下:
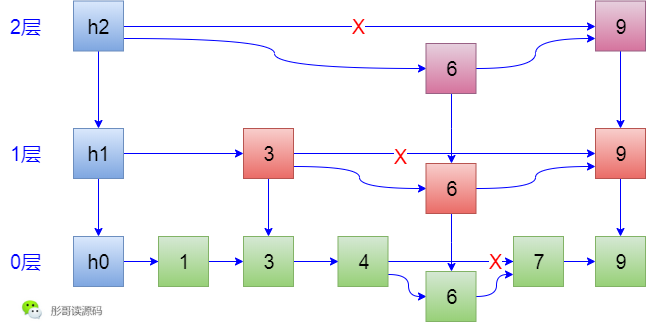
后面,插入了元素8和10,都是无惊无险,没有产生任何索引,所以,最后的结果如下:
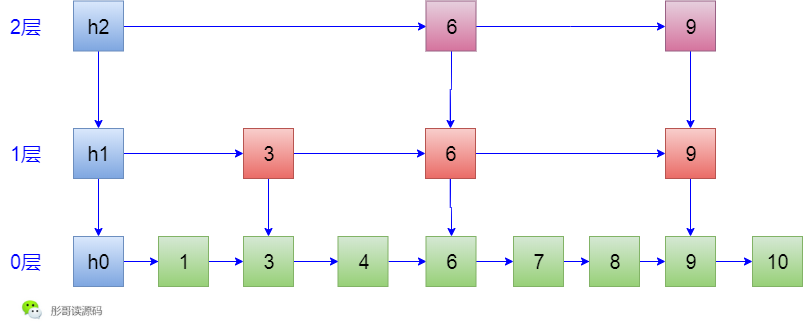
可以看到,跳表是一个非常随意的数据结构,即使按照同样的顺序重新插入一遍元素,生成的跳表也可能完全不一样,任性,所以,我很喜欢跳表这种数据结构。
第四个问题:上面描述了插入元素的过程,删除过程是怎么样的呢?
删除过程,首先也要查找到元素,但是,有一点点小区别,非常小的区别,很难描述,比如,要删除6这个元素,我能不能从h2->6->6->6这个路径过来呢?
不能,因为从这条路径过来,删除第1层的索引6后,无法修复3->9这条线,所以,删除元素的时候只能走h2->h1->3->3->4->6这条路径,且把途中每一层最后经过的索引记住,才能在删除了6这个元素之后正确地修复各层的索引。
删除6之后的样子如下:
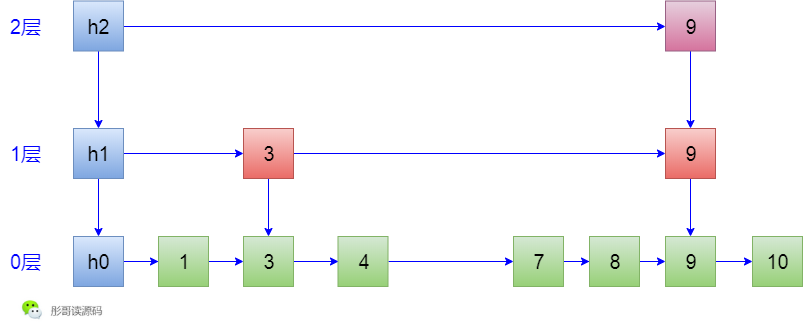
咦,讲到这里,我不经想起了Java跳表ConcurrentSkipListMap中的一个小优化项,在ConcurrentSkipListMap中,不管是查找、插入,还是删除,都是走的跟删除相同的查找路径,其实,可以简单地优化一下,插入和查找的时候完全可以走另一条路径。
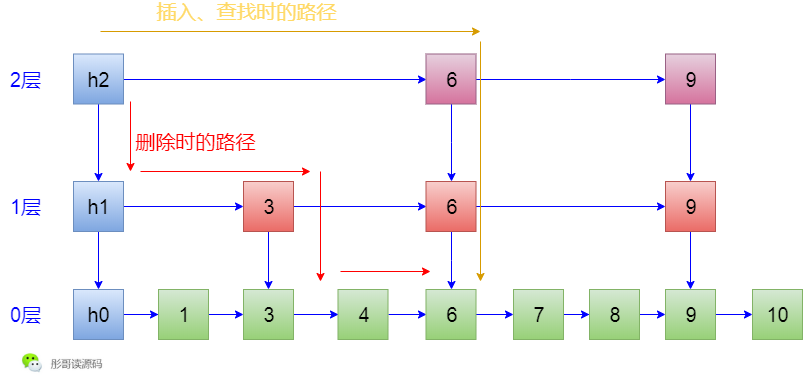
有兴趣的同学可以扒一下我的源码分析:死磕 java集合之ConcurrentSkipListMap源码分析
好了,关于跳表的理论知识我们就讲解到这里。
后记
本节,我们通过一步一图的方式完整清晰地展示了跳表查找、插入、删除元素的全过程,你有没有Get到呢?能吊打面试官了么?
然而,很多同学可能会说“Talk is cheap, Show me the code”,OK,下一节,我就将用代码的方式给你展现跳表实现的细节,并使用跳表改写HashMap,Next Part 见。
关注公众号“彤哥读源码”,解锁更多源码、基础、架构知识。