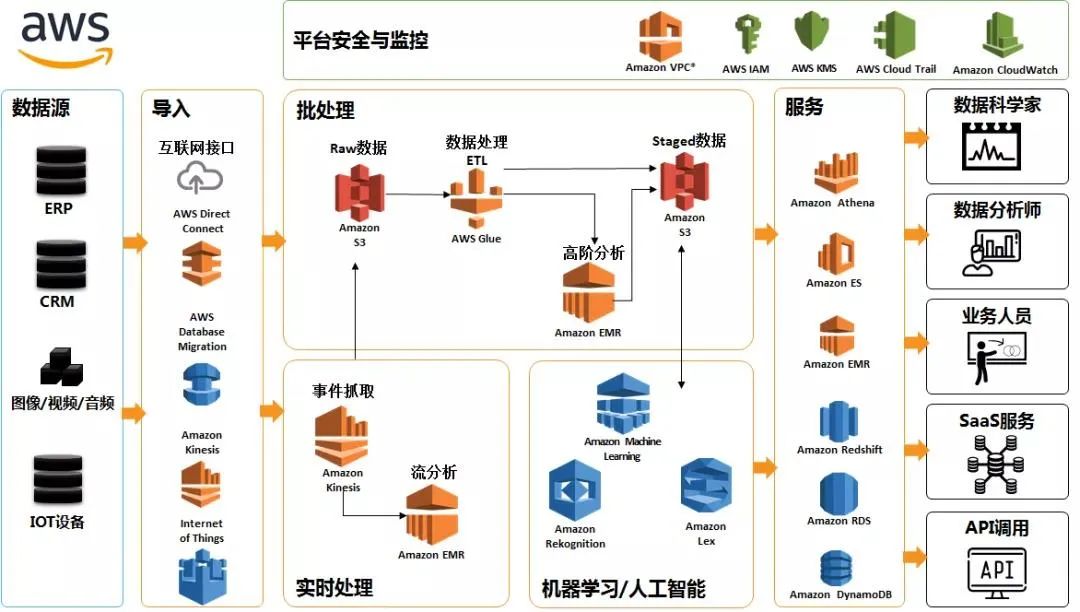
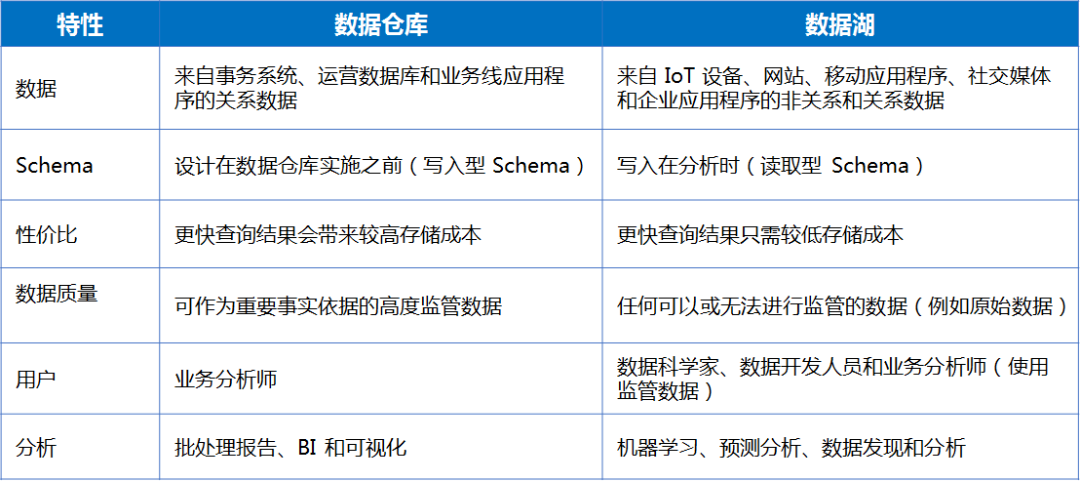
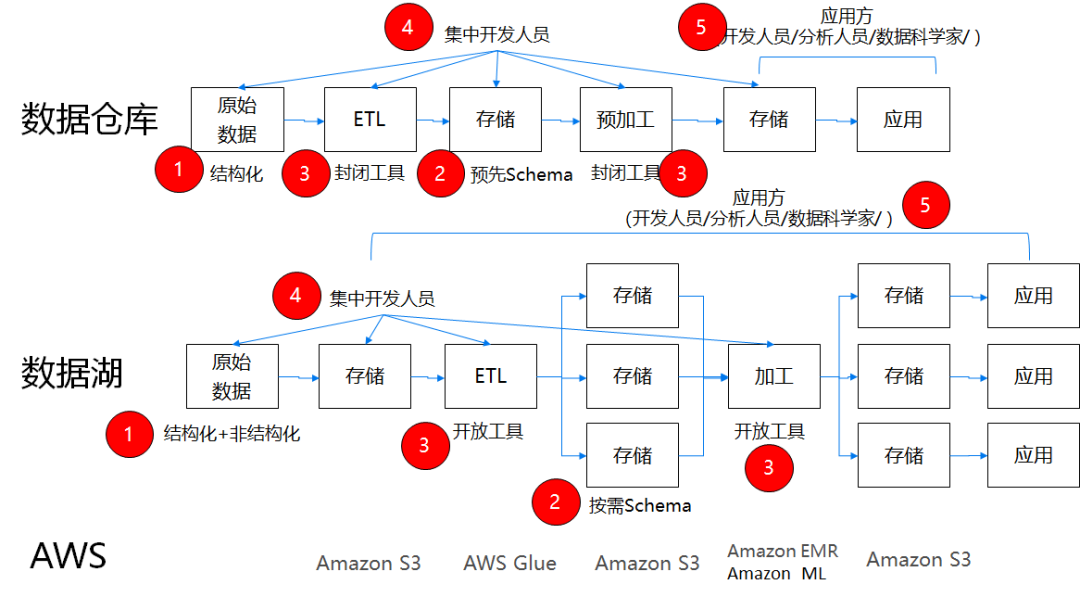
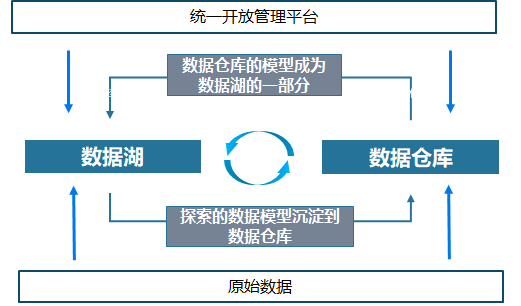
数据湖与数据仓库的根本区别,在于前者是“市场经济”,而后者是“计划经济”有关SQL关注共 3451字,需浏览 7分钟 ·2021-03-26 08:43 这是傅一平的第356篇原创正文开始很多同学跟我一样,对于数据湖充满好奇,也许还读了不少数据湖文章,有不觉明历的,也有认为是概念炒作的,但无论别人怎么说,你还是会觉得难以把握数据湖的本质。有些人会望文生义说,数据湖嘛,就是什么东西都可以往里面扔,特别是对非结构数据的处理比较方便。是这样吗?有案例才有鉴别,有的人找了数据湖的始作俑者AWS来说明数据湖是什么东西,比如下图:但光看产品的介绍,不懂数据的人也许会觉得数据湖很厉害,而懂数据的人也许会觉得仅是一堆数据仓库技术的堆砌包装而已,你看上面那张框架图,哪个专业词汇数据人士会不懂?凭什么数据湖被炒作成了一个新概念?有比较才有鉴别,因此很多文章对数据湖与数据仓库做了比较,下面是网上流传的一些说法:这种比较似乎能找到点区别,又会觉得隔靴搔痒,难道结构化与非结构化就成了数据仓库和数据湖的一个主要区别?BI和机器学习成为了主要区别?事实上,这种比较有较大逻辑漏洞:即是从结果出发来看差异,然后又用这个差异来说明区别,颠倒了因果,因此受到了不少专业人士的鄙视。比如AWS的数据湖能够处理非结构化数据,而数据仓库无法处理非结构化数据,就认为这是数据湖与数据仓库的本质区别之一。笔者这次较了一下真,来跟大家聊聊我所理解的数据湖的本质,对于一种新事物不了解本质,你就很难驾驭它,更别说实践它了,下面这张图道尽了一切。下面我用一篇文章来具体说明数据湖与数据仓库的区别,更多的是给出why,知其所以然是我理解事物的一个原则。数据仓库和数据湖的处理流程可以用下图来示意,其中用红圈标出了5个对标的流程节点。可以看到,数据湖并不比数据仓库在处理流程上多出了什么内容,更多的在于结构性的变化,下面就从数据存储、模型设计、加工工具、开发人员和消费人员五个方面来进行比较。(1)数据存储数据仓库采集、处理过程中存储下来的数据一般是以结构化的形式存在的,即使原始数据是非结构化的,但这些非结构化数据也只是在源头暂存一下,它通过结构化数据的形式进入数据仓库,成了数据仓库的基本存储格式,这个跟数据仓库的模型(维度或关系建模)都是建立在关系型数据基础上的特点有关。事实上,是传统的数据建模负担让数据仓库只处理结构化数据,其实谁都没规定过数据仓库只处理和存储结构化数据。数据湖包罗万象,轻装上阵,结构化与非结构化数据都成为了数据湖本身的一部分,这体现了数据湖中“湖”这个概念。因为没有数据仓库建模的限制,当然什么东西都可以往里面扔,但这为其变成数据沼泽埋下了伏笔。看了这段肯定无法让人信服,不要急,接着往下看。(2)模型设计数据仓库中所有的Schema(比如表结构)都是预先设计并生成好的,数据仓库建设最重要的工作就是建模,其通过封装好的、稳定的模型对外提供有限的、标准化的数据服务,模型能否设计的高内聚、松耦合成了评估数据仓库好坏的一个标准,就好比数据中台非常强调数据服务的复用性一样。你会发现,数据仓库很像数据领域的计划经济,所有的产品(模型)都是预先生成好的,模型可以变更,但相当缓慢。数据湖的模型不是预先生成的,而是随着每个应用的需要即时设计生成的,其更像是市场经济的产物,牺牲了复用性却带来了灵活性,这也是为什么数据湖的应用更多强调探索分析的原因。(3)加工工具数据仓库的采集、处理工具一般是比较封闭的,很多采取硬编码(代码)的方式暴力实现,大多只向集中的专业开发人员开放,主要的目的是实现数据的统一采集和建模,它不为消费者(应用方)服务,也没这个必要。数据湖的采集和处理工具是完全开放的,因为第(2)点提到过:数据湖的模型是由应用即席设计生成的,意味着应用必须具备针对数据湖数据的直接ETL能力和加工能力才能完成定制化模型的建设,否则就没有落地的可能,更无灵活性可言。工具能否开放、体验是否足够好是数据湖能够成功的一个前提,显然传统数据仓库的一些采集和开发工具是不行的,它们往往非常丑陋,不可能向普通大众开放。(4)开发人员数据仓库集中开发人员处理数据涵盖了数据采集、存储、加工等各个阶段,其不仅要管理数据流,也要打造工具流。由于数据流最终要为应用服务,因此其特别关注数据模型的质量,而工具流只要具备基本的功能、满足性能要求就可以了,反正是数据仓库团队人员自己用,导致的后果是害苦了运营人员。数据湖完全不一样,集中开发人员在数据流阶段只负责把原始数据扔到数据湖,更多的精力花在对工具流的改造上,因为这些工具是直接面向最终使用者的,假如不好用,数据湖就死了,据说AWS数据湖的ETL工具GLue很强大。(5)应用人员数据仓库对于应用人员暴露的所有东西就是建好的数据模型,应用方的所有角色只能在数据仓库限定好的数据模型范围内倒腾,这在一定程度上限制了应用方的创新能力。比如原始数据有个字段很有价值,但数据仓库集中开发人员却把它过滤了。这种问题在数据仓库中很常见,很多取数人员只会取宽表,对于源端数据完全不清楚,成了井底之蛙,这是数据仓库集中开发人员造的“孽”,所谓成也数据仓库,败也数据仓库。数据湖的应用方则可以利用数据湖提供的工具流接触到最生鲜的原始数据,涵盖了从数据采集、抽取、存储、加工的各个阶段,其可以基于对业务的理解,压榨出原始数据的最大价值。当然由于缺乏数据标准规范的约束,数据湖的数据管理能力不会高,而由于每个应用方都在建设竖井,因此资源的压力会越来越大。可以看到,数据仓库和数据湖,代表着两种数据处理模式和服务模式,是数据技术领域的一次轮回。早在ORACLE的DBLINK时代,我们就有了第一代的数据湖,因为那个时候ORACLE一统天下,ORALCE的DBLINK让直接探索原始数据有了可能。随着数据量的增长和数据类型的不断丰富,我们不得不搞出一种新的“数据库”来集成各种数据。但那个时候搞出的为什么是数据仓库而不是数据湖呢?主要还是应用驱动力的问题。因为那个时候大家关注的是报表,而报表最核心的要求就是准确性和一致性,标准化、规范化的维度和关系建模正好适应了这一点,集中化的数据仓库支撑模式就是一种变相的计划经济。随着大数据时代到来和数字化的发展,很多企业发现,原始数据的非结构化比例越来越高,前端应用响应的要求越来越高,海量数据挖掘的要求越来越对,报表取数已经满足不了数据驱动业务的要求了.一方面企业需要深挖各种数据,从展示数据为主(报表)逐步向挖掘数据(探索预测)转变,另一方面企业也需要从按部就班的支撑模式向快速灵活的方向转变,要求数据仓库能够开放更多的灵活性给应用方,这个时候数据仓库就有点撑不住了。数据湖就是在这种背景下诞生的。其实早在数据湖出来之前,很多企业就在做类似数据湖的工作了,比如我们5年前重构hadoop大数据平台的时候,就已经要求源端能将各种格式的数据直接扔过来,然后用不同的引擎处理,结构化的就采用商业的ETL产品,非结构化的就自己做一个定制化的ETL工具(比如爬虫),只是没有统一进行整合而已。ETL之所以不开放,主要是驱动力不够,其实我们没有那么多类型的数据要定制化抽取,也许后续会需要吧。而可视化开发平台使用比较广泛,只是因为市场觉得IT做的太慢了,需要一个可视化平台来直接操作。很多企业不搞可视化开发平台也是容易理解的,报表就能活得很好,干嘛业务人员要自己开发和挖掘。现在数据湖叫的欢的,大多是互联网公司,比如亚马逊,这是很正常的。数据湖和数据仓库有点像市场经济和计划经济,不能说谁更好谁更差,大家都有可取之处,阿里最近一篇文章提到的数湖一体是很好的概念,可以实现双方的优势互补,我这里画一张图,方便你的理解:何谓数湖一体?(1)湖和仓的数据/元数据无缝打通,互相补充,数据仓库的模型反哺到数据湖(成为原始数据一部分),湖的结构化应用知识沉淀到数据仓库(2)湖和仓有统一的开发体验,存储在不同系统的数据,可以通过一个统一的开发/管理平台操作(3)数据湖与数据仓库的数据,系统可以根据自动的规则决定哪些数据放在数仓,哪些保留在数据湖,进而形成一体化我们只有看透了数据湖的本质,才能结合企业做出理性的选择,既不跪舔,也没必要不屑,请分享给有需要的人,至于理解的对不对,大家自由评说吧! 浏览 96点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 数据湖是谁?那数据仓库又算什么?数据分析挖掘与算法0关于数据仓库、数据湖、数据平台和数据中台的概念和区别极客挖掘机0什么是集群?什么是分布式?二者的区别王猴卖瓜0你的真相是“你”根本不存在你的真相是“你”根本不存在 事实上,“你”根本不存在,“物”、“我”之分是一种虚幻的感觉。 譬如说,什么是scrm,与crm的区别是什么呢?谢邀,正好最近产品研究聚焦SCRM,应该还有些干货分享的。 从字面看,SCRM相比传统CRM就多了一个S,但这个S(Socail)却很大程度改变了CRM的运营模式,换句话说,将客户管理这个行为更聚焦与社交场景。在国内目前微信一家独大的情况下,更具体的说,SCRM往往就是基于微信生态圈的客户管理系统了。严格讲还有微信公众号,但由于微信公众号对主动的商业行为限制较多,所以公众号目前更多是企业官方信息发布,或者通过小程序实现简化的商品销售等操作,商业场景较为简单,所以SCRM重点还是放在微信生态圈。 目前微信主要有个人微信和企业微信两个产品线,所谓存在及合理,SCRM基于微信生态圈的发展也是依托这两条脉络。 坦率说,腾讯在个人微信上什么是数据仓库的架构?企业数据仓库架构如何建设?全文共4102字,建议阅读11分钟企业数据仓库架构关于数据仓库,有一种简单粗暴的说法,就是“任何数据仓库都是通过数据集成工具连接一端的原始数据和另一端的分析界面的数据库”。数据仓库用来管理企业庞大的数据集,提...复杂是技术系统的根本属性java12340关于数据仓库、数据湖、数据平台和数据中台的概念和区别浪尖聊大数据0什么是数据中台?数据中台和数据仓库的区别是什么?做数据中台需要...数据森麟0什么是scrm,与crm的区别是什么呢?SCRM是CRM的进化版。 消费模式的转变和升级催化了CRM社会化的趋势,市场环境要求营销业务要越来越“以客户为中心”,再加上社交媒体的日益普及,社交软件也渐渐变成获客工具和客服工具,SCRM系统也就应运而生。作为信息时代企业的一种商业策略,让企业客户管理这一行为更加聚焦于社交场景,强调消费者的参与和双边互动。在目前,基于企业微信生态下的SCRM系统是行业内最为常见的一种客户关系管理模式。 近两年,腾讯官方在推出企业微信的同时,也对微信个人号的推广营销、客户运营管理进行了一系列的整顿举措,个人微信封号严重,且微信存在添加好友人数限制、员工离职带走客户资源、工作手机运营管理成本高等劣势,倒逼企业选择更加高效的SCRM系统进行客户流点赞 评论 收藏 分享 手机扫一扫分享分享 举报


 下载APP
下载APP