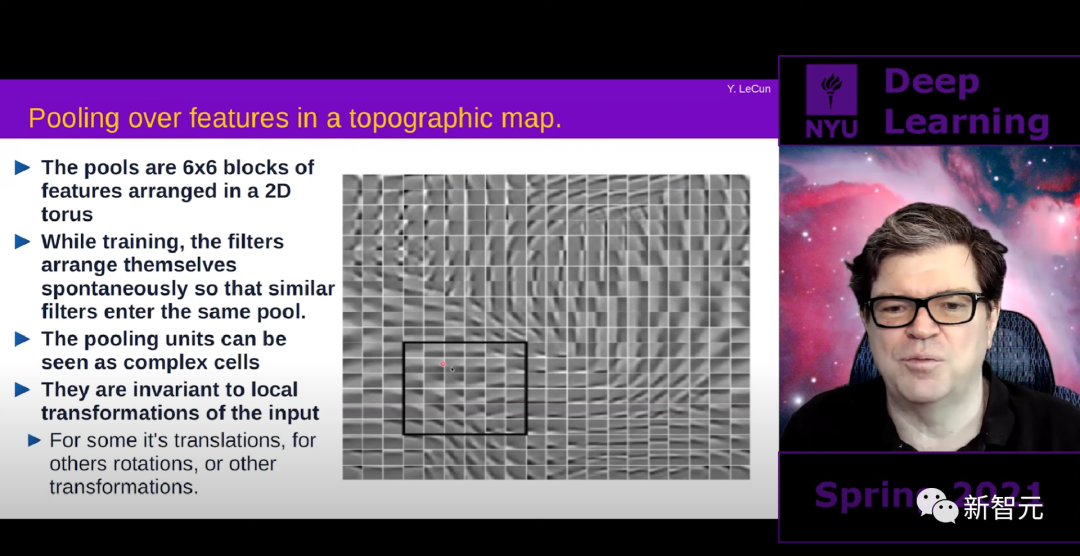
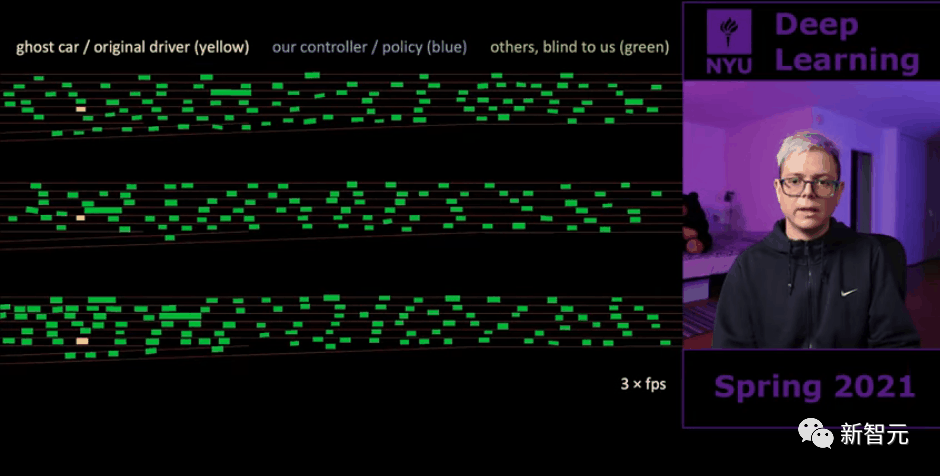
这里推荐图灵奖得主、纽约大学教授Yann LeCun主讲的在线课程。该课程最重要的优点是,它集成了LeCun对深度学习的思考。通过这门课,学习者可以了解深度学习的现状,特别是关于自监督学习、挑战、提议的解决方案和未来计划。课程地址:https://www.youtube.com/playlist?list=PLLHTzKZzVU9e6xUfG10TkTWApKSZCzuBI可能就是LeCun的教学风格不像吴恩达那样对学生友好,但过了一段时间,你就会渐渐习惯,而且回报远远大于成本。前一段时间开始,我一直在寻找一个好的在线深度学习课程,最终选出的三门课包括:纽约大学深度学习课程 SP21(Yann LeCun主讲)斯坦福大学深度学习课程 CS231N(李飞飞主讲)当然,这三门课都是无需多言的DL精品课程,主讲人都是AI业界鼎鼎大名的计算机科学家,如果你有时间可以都学,但如果时间有限,就需要做出选择。一个非常重要的原因就是,NYU的课程讲了自监督学习。上面这三门课,以及你在网上能找到的其他大部分课程,都包含了很多共同的内容,比如反向传播、CNN、RNN、GAN、Transformer、分类实例和一些实用技巧等。无论什么课程,你都会听到这些东西,只是可能教学风格偏好不同。而纽约大学的课程更专注于自监督学习,Yann LeCun认为,自监督学习是AI未来的一个基本支柱。本课程有两位导师,Yann LeCun本人和Alfredo Canziani分别专注于理论和实践。Yann LeCun无需介绍,Alfredo是纽约大学的计算机科学的助理教授。该课程内容非常广泛,涵盖了很多东西,大部分时间的深度也足够。课程时长大约50个小时,信息点密集。Alfredo为这门课开了个Github页面,里面有很多资源,包括一些超级有用的jupyter notebook和可运行的代码,并列出了为期15周的学习计划。他甚至还对youtube视频下的评论做了回应。还有来自FAIR实验室(Facebook人工智能研究实验室)的客座讲师,介绍他们在CV和NLP方面的最新工作。课程的主题之一是处理不确定性的方法。LeCun的观点是,智能体的一个基本组成部分,是其做出良好预测的能力。这需要一个世界模型,一个能够接收世界状态和行动的模块,并能预测世界的一些未来状态。不过,建立这些模型的一个主要挑战是,世界是随机的,包含很多不确定性。一个典型的例子是坠落的铅笔。如果把一支铅笔直立在桌子上,让它掉下来,无法预测它到底会落在哪里。现在我们对世界的状态没有完整的了解,所以无法做一个确定性的决定。在这些情况下,一个输入有许多貌似合理的输出。在世界的某个状态之下,下一步可能跟着几个可信的未来状态之一。那么,我们怎样才能在深度学习中处理这个问题呢?这就是基于能量的模型所要解决的问题。处理不确定性。更确切地说,学习在不确定性下做良好的预测。而同样重要的是,智能体应该能够主要通过观察来学习这个世界模型,就像动物所做的那样,使用无标签的数据。这就是为什么自监督学习如此重要的原因。标签来自于观察。你预测下一个状态,等待,下一个状态出现,你就有了你的标签。或者你隐藏了一个句子的部分内容,然后试图预测作为标签的缺失单词。根据LeCun的说法,要处理不确定性,预测世界模型的最佳途径,是用非反常的正则化方法训练的联合嵌入架构。如果你上了LeCun的这门课,就会理解为什么、怎么训练。这是2018年的一个项目。在这个项目中,智能体在像素空间中进行预测,这要求对世界的学习表征必须包含很多细节,以便能够预测一个完整的视频帧。相反,使用一个在表征空间中预测的世界模型会更好,因为表征空间的维度更低,所以不必学习预测所有不相关的细节。另一个在课程中没有提到的,是分层的JEPA模型(联合嵌入预测架构),这是LeCun提出的用于创建自主智能体的新建议。
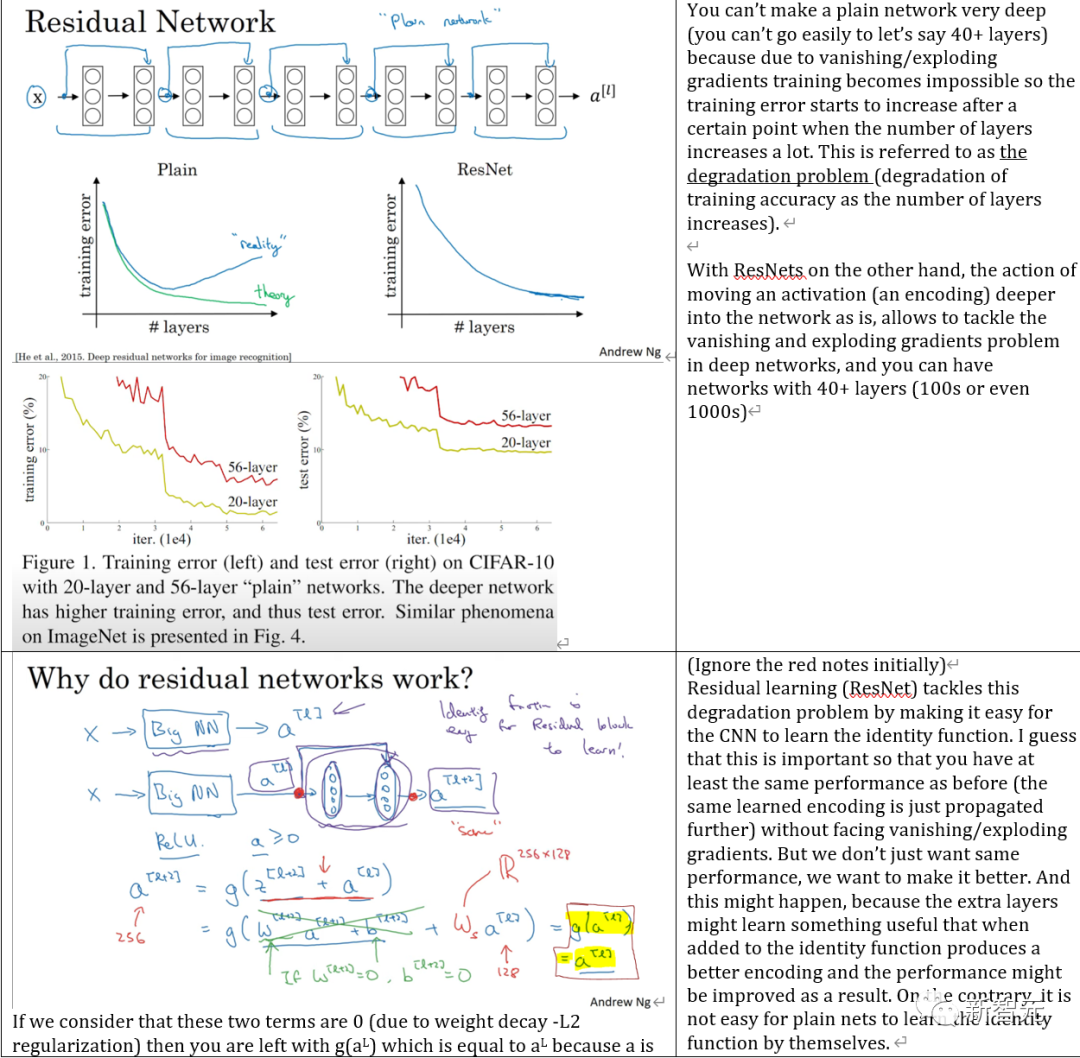
新的智能体在表示空间中进行预测,可以制定分层的行动计划,面向未来有更长的计划。但截至目前,这个方法(截至2022年),有很多挑战。LeCun试图通过他的基于能量的框架来解释事情,这可能有点令人困惑,至少在一开始。也有一些部分,他非常抽象地解释事物,在一个正式的框架内进行定义,你必须耐心地跟上他的思路。在有一些讲里,他为深度学习中的一些基本概念提供了数学证明。你可能喜欢,也可能不喜欢,取决于你对数学的兴趣和能力。50个小时很长,很难一口气看完。有时不得不暂停,思考,做笔记,很多地方需要再重新看,才觉得足够舒服。本课程至少要了解机器学习和线性代数的基础知识。这方面的优秀课程也不少,如吴恩达的机器学习课程和3Blue1Brown的线性代数课程。麻省理工学院的Gilbert Strang的简明课程也是对线性代数的一个很好的高水平概述。另外,如果对反向传播的工作原理有一些基本的了解,对于也是很有帮助的。3Blue1Brown也有一个关于反向传播的简短说明,他以非常直观的方式解释了整个过程。最后放上学习笔记。(包含大量的图片,所以docx文件相当大...),笔记比较长,无法在线查看。笔记里边有听课时对授课内容的一些理解和推导。比如:
https://drive.google.com/file/d/1F2MtqLlLFmxYcpXRRd-kSz8Csi2VSgmZ/view
- 机器学习交流qq群955171419,加入微信群请扫码(读博请说明)