
Python自动化,自动下载数据+处理Excel表格+信息报送
前言
今年以来国内疫情呈现反复性多点散发,公司每天有大量的人员来访,也有相当一部分的职工因私或因公外出,怎么一对多和多对一的及时沟通反馈信息成了落实疫情防控部署的关键点,作为公司疫情防控的主管单位,这一点我们责无旁贷,最终选择了某星的问卷调查模式,实时、简单、方便快捷。但随之而来的就是我每天要去后台下载统计数据,然后对着表格一通操作,把信息报出去。一次两次还可以,但咱“能坐着不站着,能躺着不坐着”的优秀发展理念不能丢,急需研究下怎么才能更好提升工作效率。
需求分析
针对存在的问题,先分析下目前的工作流程:下载数据-处理表格-信息报送,共三大步。第一步受限于公司网络物理隔离,暂无法实施;第三步微信发送,与第一步同样的原因,只能放弃;总的来看,其中工作最重的第二步就成了本次实施的最终目标。
先分析一下,目前第二步都要处理哪些事情:
查找前一日最后一个行号; 根据行号删除不必要的行; 因为问卷已经发布,且用的人比较多,同时又有历史数据在里面,不方便重新发问卷,所以要删除不必要的列; 生成处理后的新的Excel 对Excel表格的格式进行处理
代码实现
既然相关的需要实施的步骤都应经分析好了,话不多说,上代码:
1.找出需要进行操作的文件
def get_fname(self):
'''
获取目录下所有文件
:return: 文件名列表的切片,最后两个文件
'''
fnames = os.listdir(self.path)
return fnames[-2:]
2.查找前一日最后一行的index
def get_last_index(self):
'''
获取上一日汇总表总后一个index
:return: 返回上一日最后一个index
'''
fpath = self.path + "/" + self.get_fname()[0]
df = pd.read_excel(fpath, index_col="序号")
last_num = [i for i in df.index][-1:] #最后一个index,这里是列表
for i in last_num: #列表转字符串
# print(i)
return i
3.清洗数据并返回新的Excel
未处理前的数据汇总,这里截取了部分。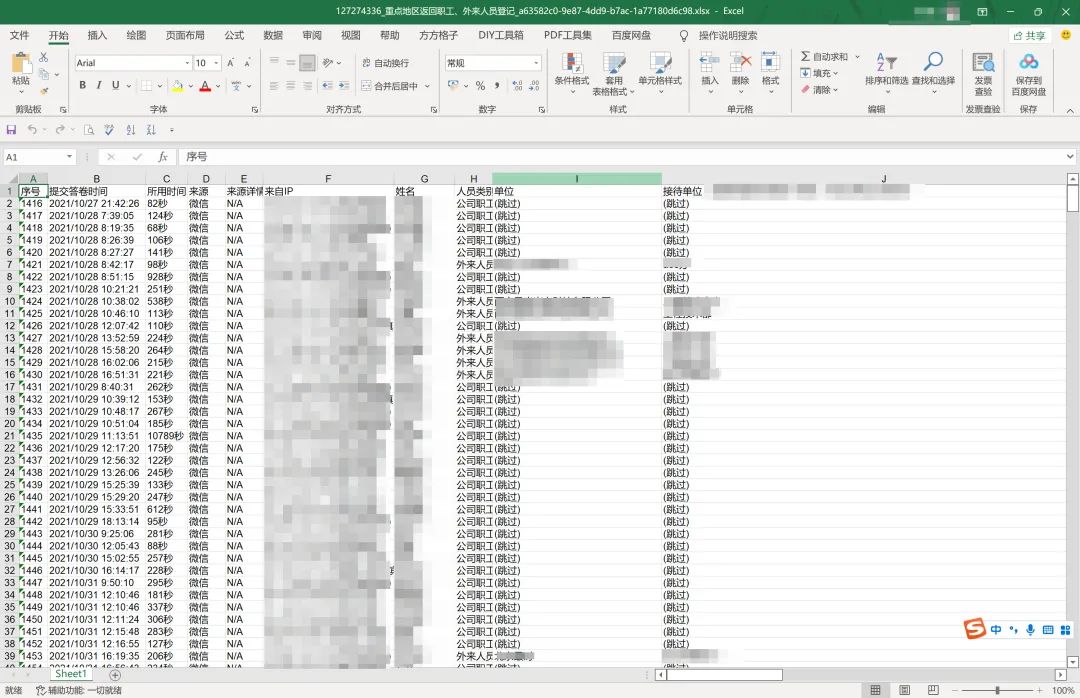 pd打开文件,得到一个Dataframe,对df进行删除行、删除列、调整列、返回新的Excel。
pd打开文件,得到一个Dataframe,对df进行删除行、删除列、调整列、返回新的Excel。
def get_excel(self):
'''
使用pandas对数据进行清洗
'''
fpath = self.path + "/" + self.get_fname()[1]
df = pd.read_excel(fpath)
df.index =df.index+1416 #赋值新的索引
data_list = [i for i in df.index] #将索引读取为列表
del_index_num = self.get_last_index()
def_index_target = data_list.index(del_index_num) #获取前一日结束索引的下标
del_index_list = data_list[:def_index_target+1] #根据下标切片
df.drop([i for i in del_index_list], inplace=True) #删除指定的行,drop只支持列表,不支持嵌套
df_cols = df.columns.values #获取所有列名
col_list = [df_col for df_col in df_cols] #将所有列名存入列表
col_list[9] = col_list[9][:4] #修改对应的列名(字符串切片语法)
col_list[14] = col_list[14][:16] #修改对应的列名(字符串切片语法)
col_list[19] = col_list[19][:5] #修改对应的列名(字符串切片语法)
df.columns = col_list #datafram的新列名是列表值
df.drop(labels=["提交答卷时间","所用时间","来源","来源详情","来自IP","是否核酸检测","核酸检测日期","核酸检测结果","是否接种疫苗","未接种原因"],axis=1, inplace=True) #删除不需要的列,因为是固定的直接写列名
# print(df)
new_excel_name = "(整理后)" + self.get_fname()[1]
df.to_excel(self.path+"/"+new_excel_name, index=False)
return new_excel_name
处理后的数据,这里截取了部分。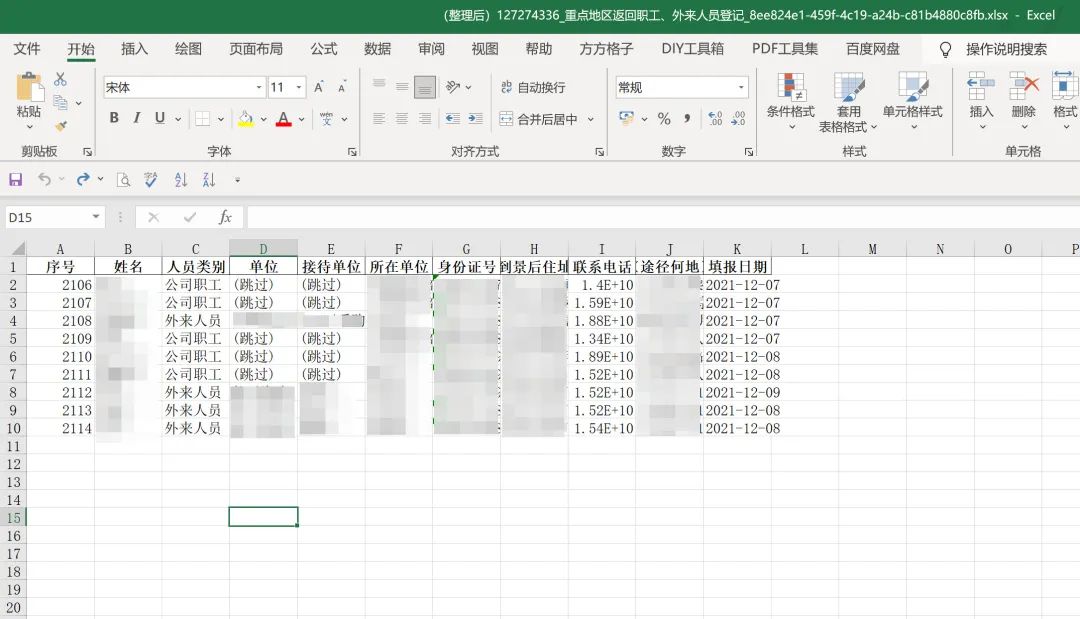
4.处理Excel
上一步处理完后,存在不美观不方便阅读的情况,这一步继续对Excel的格式进行操作,比如添加边框,调整列宽等,使其更方便发送。
def read_excel(self):
'''对Excel进行操作'''
app = xw.App(visible=False, add_book=False)
app.display_alerts = False
app.screen_updating = False
fpath = self.path+"/"+self.get_excel()
wb = app.books.open(fpath)
sht = wb.sheets[0]
sht.range(1,10).column_width = 45 #设置第1行第10列列宽
sht.range(1,8).column_width = 21 #设置第1行第8列列宽
sht.range(1,4).column_width = 16
sht.range(1,5).column_width = 14
sht.range(1,7).column_width = 21
sht.range(1,9).column_width = 12
sht.range(1,11).column_width =10
sht.range(1,6).column_width = 13
last_column = sht.range(1,1).end("right").get_address(0,0)[0] #获取最后一列
last_row = sht.range(1,1).end("down").row #获取最后一行
a_range = f"A1:{last_column}{last_row}" #生成表格的数据范围
sht.range(a_range).api.HorizontalAlignment = -4131
sht.range(a_range).api.VerticalAlignment = -4130
sht.range(a_range).api.Borders(8).LineStyle = 1 #上边框
sht.range(a_range).api.Borders(9).LineStyle = 1 #下边框
sht.range(a_range).api.Borders(7).LineStyle = 1 #左边框
sht.range(a_range).api.Borders(10).LineStyle = 1 #右边框
sht.range(a_range).api.Borders(11).LineStyle = 1 #内纵边框
sht.range(a_range).api.Borders(12).LineStyle = 1 #内横边框
data_name = datetime.datetime.today()
excel_name = str(data_name)[5:10] + " 重点地区返回职工、外来人员登记" # 获取文件名
wb.save(self.path+"/"+excel_name+".xlsx") #保存文件
wb.close() #关闭
app.quit() #退出
print("Success")
最终结果,如愿以偿,再也不用每天打开表格一通操作,也不用回想昨天是怎么写的名称,调的多大的间距,昨天的最后一行序号是多少,所有一切尽在弹指一挥间。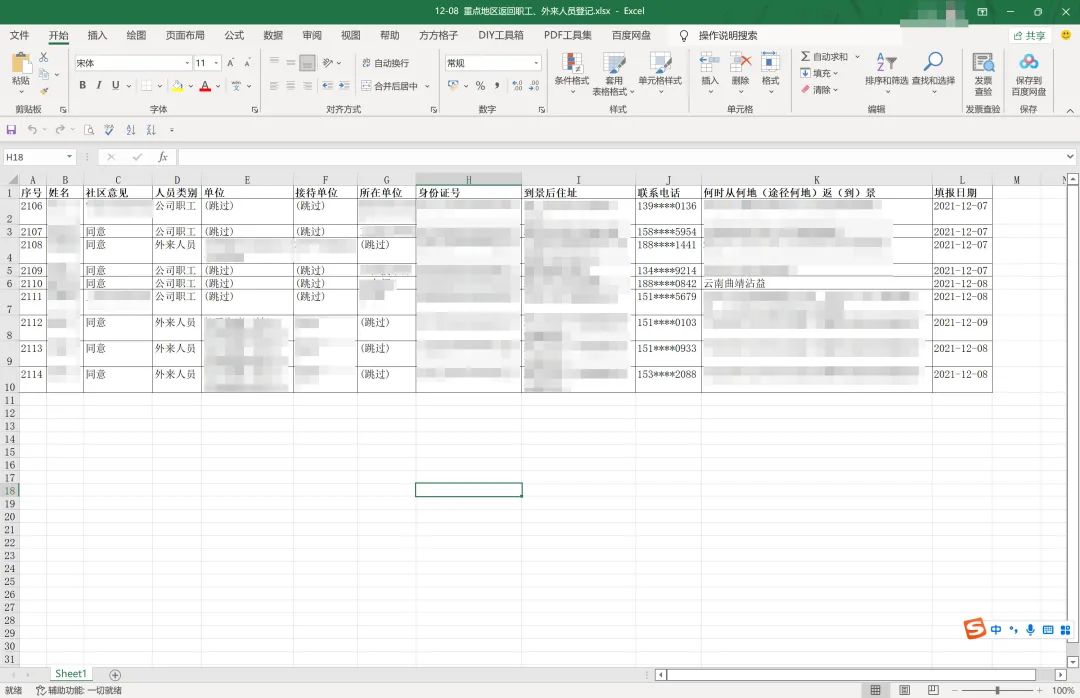
全部代码
最后,奉上全部代码
import pandas as pd
import xlwings as xw
import os
import datetime
class Core_excel():
def __init__(self,path):
self.path = path
def get_fname(self):
'''
获取目录下所有文件
:return: 文件名列表的切片,最后两个文件
'''
fnames = os.listdir(self.path)
return fnames[-2:]
def get_last_index(self):
'''
获取上一日汇总表总后一个index
:return: 返回上一日最后一个index
'''
fpath = self.path + "/" + self.get_fname()[0]
df = pd.read_excel(fpath, index_col="序号")
last_num = [i for i in df.index][-1:] #最后一个index,这里是列表
for i in last_num: #列表转字符串
# print(i)
return i
def get_excel(self):
'''
使用pandas对数据进行清洗
'''
fpath = self.path + "/" + self.get_fname()[1]
df = pd.read_excel(fpath)
df.index =df.index+1416 #赋值新的索引
data_list = [i for i in df.index] #将索引读取为列表
del_index_num = self.get_last_index()
def_index_target = data_list.index(del_index_num) #获取前一日结束索引的下标
del_index_list = data_list[:def_index_target+1] #根据下标切片
df.drop([i for i in del_index_list], inplace=True) #删除指定的行,drop只支持列表,不支持嵌套
df_cols = df.columns.values #获取所有列名
col_list = [df_col for df_col in df_cols] #将所有列名存入列表
col_list[9] = col_list[9][:4] #修改对应的列名(字符串切片语法)
col_list[14] = col_list[14][:16] #修改对应的列名(字符串切片语法)
col_list[19] = col_list[19][:5] #修改对应的列名(字符串切片语法)
df.columns = col_list #datafram的新列名是列表值
df.drop(labels=["提交答卷时间","所用时间","来源","来源详情","来自IP","是否核酸检测","核酸检测日期","核酸检测结果","是否接种疫苗","未接种原因"],axis=1, inplace=True) #删除不需要的列,因为是固定的直接写列名
# print(df)
new_excel_name = "(整理后)" + self.get_fname()[1]
df.to_excel(self.path+"/"+new_excel_name, index=False)
return new_excel_name
def read_excel(self):
'''对Excel进行操作'''
app = xw.App(visible=False, add_book=False)
app.display_alerts = False
app.screen_updating = False
fpath = self.path+"/"+self.get_excel()
wb = app.books.open(fpath)
sht = wb.sheets[0]
sht.range(1,10).column_width = 45 #设置第1行第10列列宽
sht.range(1,8).column_width = 21 #设置第1行第8列列宽
sht.range(1,4).column_width = 16
sht.range(1,5).column_width = 14
sht.range(1,7).column_width = 21
sht.range(1,9).column_width = 12
sht.range(1,11).column_width =10
sht.range(1,6).column_width = 13
last_column = sht.range(1,1).end("right").get_address(0,0)[0] #获取最后一列
last_row = sht.range(1,1).end("down").row #获取最后一行
a_range = f"A1:{last_column}{last_row}" #生成表格的数据范围
sht.range(a_range).api.HorizontalAlignment = -4131
sht.range(a_range).api.VerticalAlignment = -4130
sht.range(a_range).api.Borders(8).LineStyle = 1 #上边框
sht.range(a_range).api.Borders(9).LineStyle = 1 #下边框
sht.range(a_range).api.Borders(7).LineStyle = 1 #左边框
sht.range(a_range).api.Borders(10).LineStyle = 1 #右边框
sht.range(a_range).api.Borders(11).LineStyle = 1 #内纵边框
sht.range(a_range).api.Borders(12).LineStyle = 1 #内横边框
data_name = datetime.datetime.today()
excel_name = str(data_name)[5:10] + " 重点地区返回职工、外来人员登记" # 获取文件名
wb.save(self.path+"/"+excel_name+".xlsx") #保存文件
wb.close() #关闭
app.quit() #退出
print("Success")
if __name__ == '__main__':
path = "./2021年10月22日起重点地区来人登记"
core_excel = Core_excel(path)
core_excel.read_excel()
最后,推荐蚂蚁老师的《零基础入门到Python数据分析办公自动化课程》,小白从入门到实战,到副业接单,学起来。
评论