
盘点一个Python自动化办公之Excel表格合并需求
回复“ 书籍 ”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
一番桃李花开尽,惟有青青草色齐。大家好,我是皮皮。
一、前言
前几天在Python最强王者交流群【FiNε_】问了一个Python自动化办公的问题。问题如下:你是一名资深的Python自动化办公工程师,你的电脑桌面上的【数据】文件夹内有若干个.xlsx文件,每一个表格格式一样,但是数据不一样,每个表格里面有6个sheet子表,sheet子表名分别为:短期、超短期、可用功、上报日结果、日结果、死区。现在需要你读取所有表格,并将所有的sheet子表进行合并。比方说:所有的【短期】数据汇总在总表的【短期】子sheet,所有的【超短期】数据汇总在总表的【超短期】子sheet,所有的【可用功】数据汇总在总表的【可用功】子sheet,以此类推。最后,将所有表格的数据存放在一个整体的csv文件中,该csv文件的子表名也分别为:短期、超短期、可用功、上报日结果、日结果、死区。请你写一份Python自动化办公代码,帮助解决这个问题。
二、实现过程
这里【莫生气】给了一个指导,得到的结果如下:
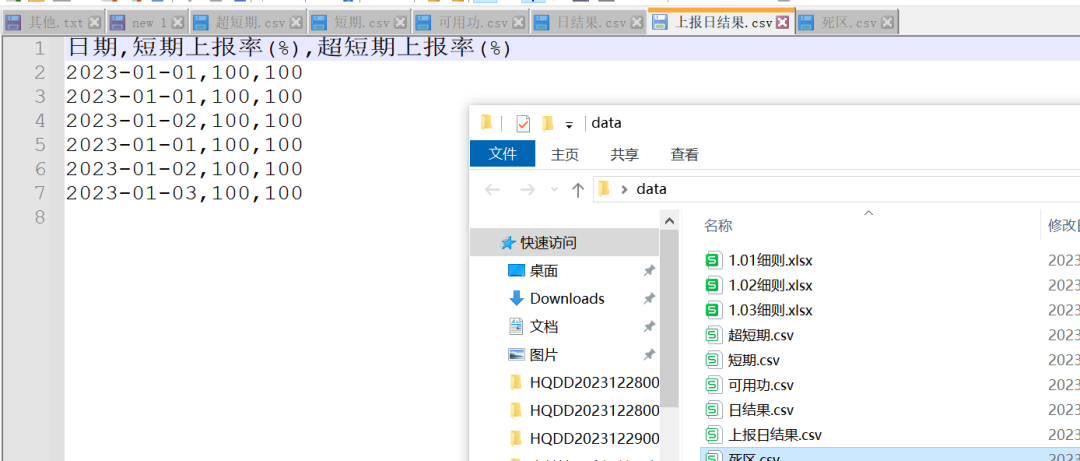
子表下面的各个表格全部是分开的,给它单独做出来了,还得手动处理下,才能合并。当然了,这里只是用了其中3个测试文件,实际上是有365个文件的。这里的代码如下所示:
# 短期、超短期、可用功、上报日结果、日结果、死区,6个子表单独分开存储
import os
import pandas as pd
# 设置工作目录为包含Excel文件的文件夹路径
folder_path = r'C:\Users\pdcfi\Desktop\data'
os.chdir(folder_path)
# 子表名数组
sheet_names = ['短期', '超短期', '可用功', '上报日结果', '日结果', '死区']
# 初始化字典来存放每个子表数据
all_sheets_data = {name: [] for name in sheet_names}
# 遍历文件夹内所有xlsx文件
for file in os.listdir(folder_path):
if file.endswith('.xlsx'):
file_path = os.path.join(folder_path, file)
# 读取每个子表并添加到对应的数组中
for sheet_name in sheet_names:
# 跳过无法找到子表的情况
try:
sheet_data = pd.read_excel(file_path, sheet_name=sheet_name)
all_sheets_data[sheet_name].append(sheet_data)
except Exception as e:
print(e)
print(f"Skipping sheet {sheet_name} in {file}")
# 合并每个子表数据并保存为CSV文件
for sheet_name, data in all_sheets_data.items():
combined_data = pd.concat(data, ignore_index=True)
csv_file_path = os.path.join(folder_path, f"{sheet_name}.csv")
combined_data.to_csv(csv_file_path, index=False, encoding='utf_8_sig')
print('合并工作完成!')
顺利地解决了粉丝的问题。不过接下来【东哥】给了一份代码优化后,如下所示,就可以自动将合并后的表格数据保存到一个整体的数据表文件中了。
import pandas as pd
import os
# 读取所有xlsx文件并逐个合并子表
folder_path = r'C:\Users\Desktop\data' # 替换成实际的文件夹路径
all_data = {}
for file_name in os.listdir(folder_path):
if file_name.endswith(".xlsx"):
file_path = os.path.join(folder_path, file_name)
xls = pd.ExcelFile(file_path)
for sheet_name in xls.sheet_names:
if sheet_name not in all_data:
all_data[sheet_name] = pd.DataFrame()
sheet_data = pd.read_excel(file_path, sheet_name=sheet_name)
all_data[sheet_name] = pd.concat([all_data[sheet_name], sheet_data], ignore_index=True)
# 将所有合并后的数据保存到一个整体的CSV文件中
output_csv = r"C:\Users\Desktop\总表.xlsx" # 替换成实际的输出文件路径
with pd.ExcelWriter(output_csv, engine='openpyxl') as writer:
for sheet_name, df in all_data.items():
df.to_excel(writer, sheet_name=sheet_name, index=False)
print("数据已成功合并并保存到总表.xlsx。")
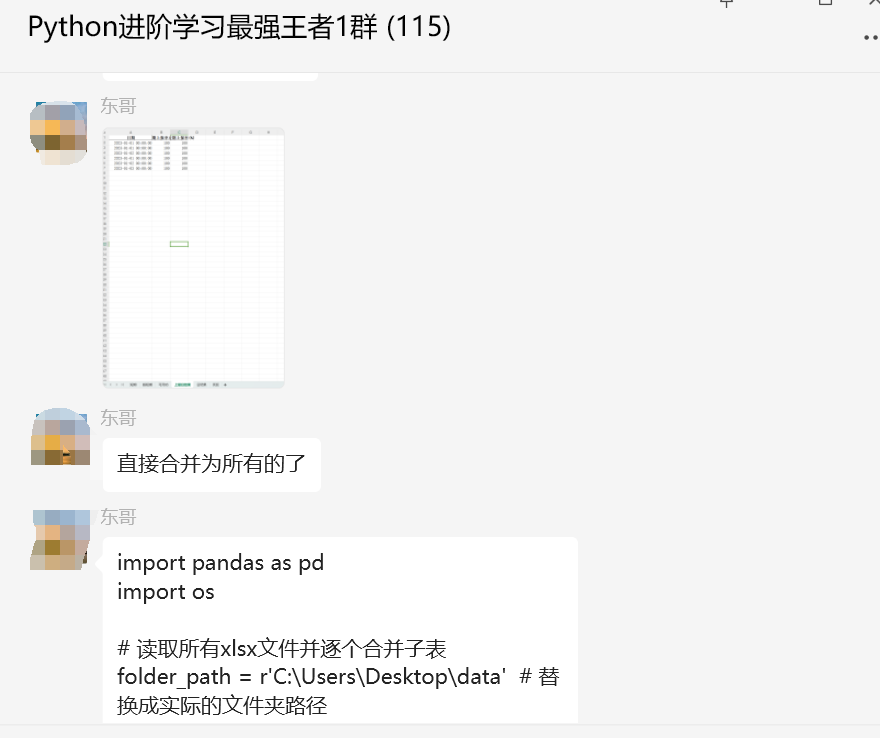
顺利地解决了粉丝的问题。
后来粉丝还遇到了一个小问题,也顺便一起解决了。
如果你也有类似这种数据分析的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Pandas自动化办公的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【FiNε_】提出的问题,感谢【莫生气】、【东哥】给出的思路,感谢【冯诚】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting1),应粉丝要求,我创建了一些ChatGPT机器人交流群和高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:
欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【 入群 】
万水千山总是情,点个【 在看 】行不行
/今日留言主题/
随便说一两句吧~~