
详解机器学习中的7种交叉验证方法

来源:机器学习社区、数据派THU
本文约3400字,建议阅读10分钟
本文与你分享7种最常用的交叉验证技术及其优缺点,提供了每种技术的代码片段。在任何有监督机器学习项目的模型构建阶段,我们训练模型的目的是从标记的示例中学习所有权重和偏差的最佳值。
如果我们使用相同的标记示例来测试我们的模型,那么这将是一个方法论错误,因为一个只会重复刚刚看到的样本标签的模型将获得完美的分数,但无法预测任何有用的东西 - 未来的数据,这种情况称为过拟合。
为了克服过度拟合的问题,我们使用交叉验证。所以你必须知道什么是交叉验证?以及如何解决过拟合的问题?
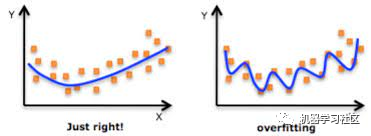
什么是交叉验证?
它是如何解决过拟合问题的?
在本文中,我将分享 7 种最常用的交叉验证技术及其优缺点,我还提供了每种技术的代码片段,欢迎收藏学习,喜欢点赞支持。
下面列出了这些技术方法:
- HoldOut 交叉验证
- K-Fold 交叉验证
- 分层 K-Fold交叉验证
- Leave P Out 交叉验证
- 留一交叉验证
- 蒙特卡洛 (Shuffle-Split)
- 时间序列(滚动交叉验证)
1、HoldOut 交叉验证
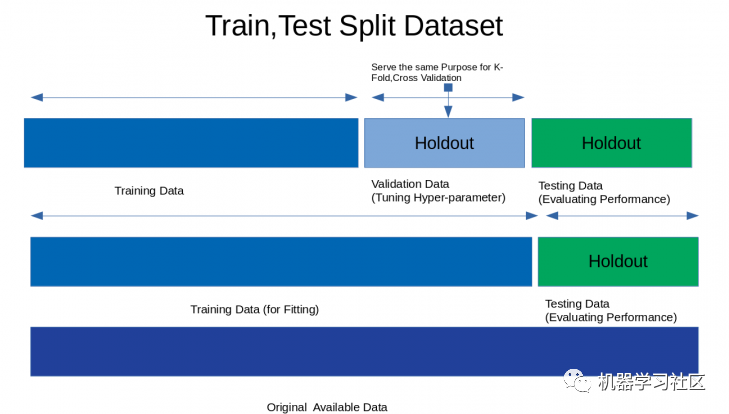
优点:
1.快速执行:因为我们必须将数据集拆分为训练集和验证集一次,并且模型将在训练集上仅构建一次,因此可以快速执行。
缺点:
1. 不适合不平衡数据集:假设我们有一个不平衡数据集,它具有“0”类和“1”类。假设 80% 的数据属于“0”类,其余 20% 的数据属于“1”类。在训练集大小为 80%,测试数据大小为数据集的 20% 的情况下进行训练-测试分割。可能会发生“0”类的所有 80% 数据都在训练集中,而“1”类的所有数据都在测试集中。所以我们的模型不能很好地概括我们的测试数据,因为它之前没有看到过“1”类的数据;
2. 大量数据无法训练模型。
在小数据集的情况下,将保留一部分用于测试模型,其中可能具有我们的模型可能会错过的重要特征,因为它没有对该数据进行训练。
代码片段:
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_scoreiris=load_iris()X=iris.dataY=iris.targetprint("Size of Dataset {}".format(len(X)))logreg=LogisticRegression()x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=42)logreg.fit(x_train,y_train)predict=logreg.predict(x_test)print("Accuracy score on training set is {}".format(accuracy_score(logreg.predict(x_train),y_train)))print("Accuracy score on test set is {}".format(accuracy_score(predict,y_test)))

2、K 折交叉验证
该技术重复 K 次,直到每个折叠用作验证集,其余折叠用作训练集。
模型的最终精度是通过取 k-models 验证数据的平均精度来计算的。
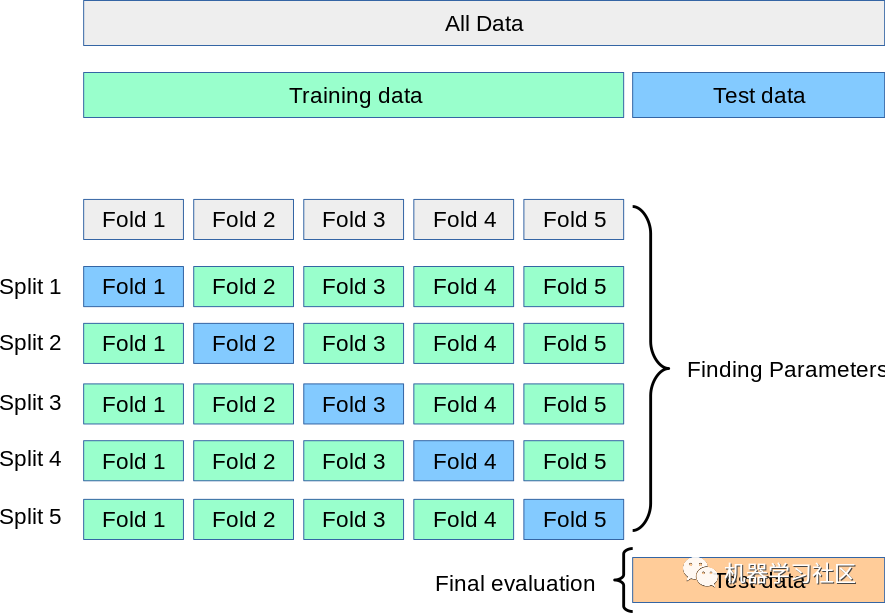
1. 整个数据集既用作训练集又用作验证集。
缺点:
1. 不用于不平衡的数据集:正如在 HoldOut 交叉验证的情况下所讨论的,在 K-Fold 验证的情况下也可能发生训练集的所有样本都没有样本形式类“1”,并且只有 类“0”。验证集将有一个类“1”的样本;2. 不适合时间序列数据:对于时间序列数据,样本的顺序很重要。但是在 K 折交叉验证中,样本是按随机顺序选择的。
代码片段:
from sklearn.datasets import load_irisfrom sklearn.model_selection import cross_val_score,KFoldfrom sklearn.linear_model import LogisticRegressioniris=load_iris()X=iris.dataY=iris.targetlogreg=LogisticRegression()kf=KFold(n_splits=5)score=cross_val_score(logreg,X,Y,cv=kf)print("Cross Validation Scores are {}".format(score))print("Average Cross Validation score :{}".format(score.mean()))

3、分层 K 折交叉验证
但是在这种技术中,每个折叠将具有与整个数据集中相同的目标变量实例比率。
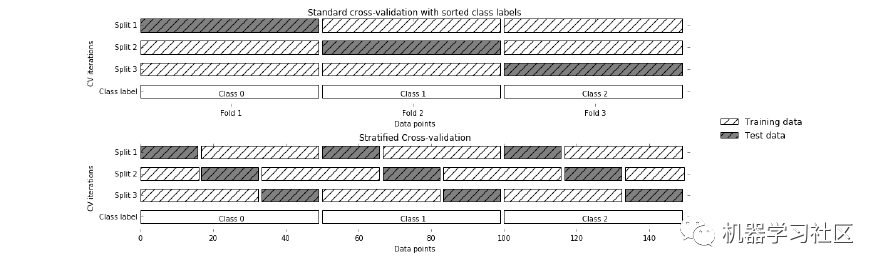
1. 对于不平衡数据非常有效:分层交叉验证中的每个折叠都会以与整个数据集中相同的比率表示所有类别的数据。
缺点:
1. 不适合时间序列数据:对于时间序列数据,样本的顺序很重要。但在分层交叉验证中,样本是按随机顺序选择的。
代码片段:
from sklearn.datasets import load_irisfrom sklearn.model_selection import cross_val_score,StratifiedKFoldfrom sklearn.linear_model import LogisticRegressioniris=load_iris()X=iris.dataY=iris.targetlogreg=LogisticRegression()stratifiedkf=StratifiedKFold(n_splits=5)score=cross_val_score(logreg,X,Y,cv=stratifiedkf)print("Cross Validation Scores are {}".format(score))print("Average Cross Validation score :{}".format(score.mean()))

4、Leave P Out 交叉验证
假设我们在数据集中有 100 个样本。如果我们使用 p=10,那么在每次迭代中,10 个值将用作验证集,其余 90 个样本将用作训练集。
重复这个过程,直到整个数据集在 p 样本和 n-p 训练样本的验证集上被划分。
优点:
1. 所有数据样本都用作训练和验证样本。
缺点:
1. 计算时间长:由于上述技术会不断重复,直到所有样本都用作验证集,因此计算时间会更长;2. 不适合不平衡数据集:与 K 折交叉验证相同,如果在训练集中我们只有 1 个类的样本,那么我们的模型将无法推广到验证集。
代码片段:
from sklearn.model_selection import LeavePOut,cross_val_scorefrom sklearn.datasets import load_irisfrom sklearn.ensemble import RandomForestClassifieriris=load_iris()X=iris.dataY=iris.targetlpo=LeavePOut(p=2)lpo.get_n_splits(X)tree=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)score=cross_val_score(tree,X,Y,cv=lpo)print("Cross Validation Scores are {}".format(score))print("Average Cross Validation score :{}".format(score.mean()))

5、留一交叉验证
假设我们在数据集中有 100 个样本。然后在每次迭代中,1 个值将用作验证集,其余 99 个样本作为训练集。因此,重复该过程,直到数据集的每个样本都用作验证点。
它与使用 p=1 的 LeavePOut 交叉验证相同。
代码片段:
from sklearn.datasets import load_irisfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import LeaveOneOut,cross_val_scoreiris=load_iris()X=iris.dataY=iris.targetloo=LeaveOneOut()tree=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)score=cross_val_score(tree,X,Y,cv=loo)print("Cross Validation Scores are {}".format(score))print("Average Cross Validation score :{}".format(score.mean()))
6、蒙特卡罗交叉验证(Shuffle Split)
我们已经决定了要用作训练集的数据集的百分比和用作验证集的百分比。如果训练集和验证集大小的增加百分比总和不是 100,则剩余的数据集不会用于训练集或验证集。
假设我们有 100 个样本,其中 60% 的样本用作训练集,20% 的样本用作验证集,那么剩下的 20%( 100-(60+20)) 将不被使用。
这种拆分将重复我们必须指定的“n”次。

优点:
1.我们可以自由使用训练和验证集的大小;2.我们可以选择重复的次数,而不依赖于重复的折叠次数。
缺点:
1. 可能不会为训练集或验证集选择很少的样本;2. 不适合不平衡的数据集:在我们定义了训练集和验证集的大小后,所有的样本都是随机选择的,所以训练集可能没有测试中的数据类别 设置,并且该模型将无法概括为看不见的数据。
代码片段:
from sklearn.model_selection import ShuffleSplit,cross_val_scorefrom sklearn.datasets import load_irisfrom sklearn.linear_model import LogisticRegressionlogreg=LogisticRegression()shuffle_split=ShuffleSplit(test_size=0.3,train_size=0.5,n_splits=10)scores=cross_val_score(logreg,iris.data,iris.target,cv=shuffle_split)print("cross Validation scores:n {}".format(scores))print("Average Cross Validation score :{}".format(scores.mean()))

7、时间序列交叉验证
时间序列数据是在不同时间点收集的数据。由于数据点是在相邻时间段收集的,因此观测值之间可能存在相关性。这是区分时间序列数据与横截面数据的特征之一。
在时间序列数据的情况下如何进行交叉验证?
在时间序列数据的情况下,我们不能选择随机样本并将它们分配给训练集或验证集,因为使用未来数据中的值来预测过去数据的值是没有意义的。
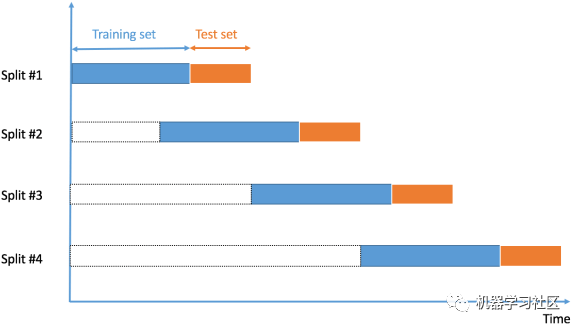
由于数据的顺序对于时间序列相关问题非常重要,所以我们根据时间将数据拆分为训练集和验证集,也称为“前向链”方法或滚动交叉验证。
我们从一小部分数据作为训练集开始。基于该集合,我们预测稍后的数据点,然后检查准确性。
然后将预测样本作为下一个训练数据集的一部分包括在内,并对后续样本进行预测。
优点:
1. 最好的技术之一。
缺点:
1. 不适用于其他数据类型的验证:与其他技术一样,我们选择随机样本作为训练或验证集,但在该技术中数据的顺序非常重要。
代码片段:
import numpy as npfrom sklearn.model_selection import TimeSeriesSplitX = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])y = np.array([1, 2, 3, 4, 5, 6])time_series = TimeSeriesSplit()print(time_series)for train_index, test_index in time_series.split(X):print("TRAIN:", train_index, "TEST:", test_index)X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]
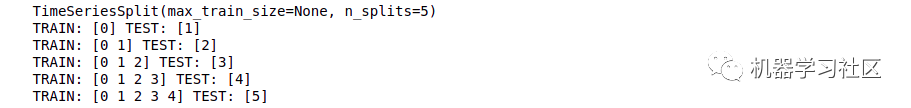
结论
编辑:黄继彦
校对:龚力
评论