
深度盘点:详细介绍机器学习中的7种交叉验证方法!

来源:机器学习社区 本文约3400字,建议阅读10分钟
本文与你分享7种最常用的交叉验证技术及其优缺点,提供了每种技术的代码片段。
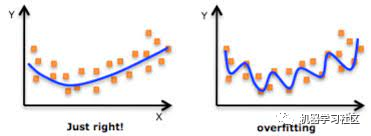
什么是交叉验证?
它是如何解决过拟合问题的?
HoldOut 交叉验证 K-Fold 交叉验证 分层 K-Fold交叉验证 Leave P Out 交叉验证 留一交叉验证 蒙特卡洛 (Shuffle-Split) 时间序列(滚动交叉验证)
1、HoldOut 交叉验证
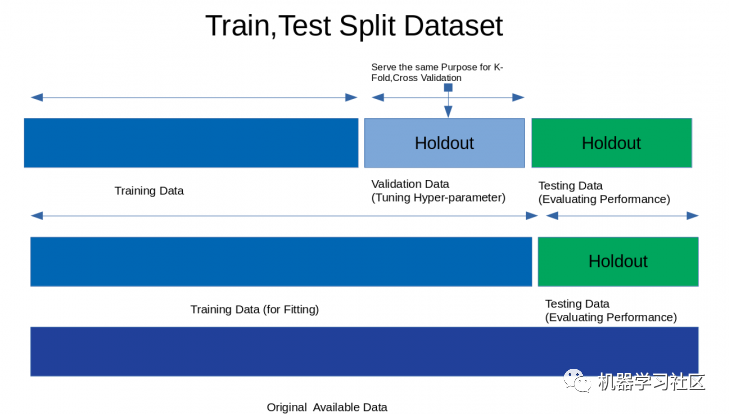
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_scoreiris=load_iris()X=iris.dataY=iris.targetprint("Size of Dataset {}".format(len(X)))logreg=LogisticRegression()x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=42)logreg.fit(x_train,y_train)predict=logreg.predict(x_test)print("Accuracy score on training set is {}".format(accuracy_score(logreg.predict(x_train),y_train)))print("Accuracy score on test set is {}".format(accuracy_score(predict,y_test)))

2、K 折交叉验证
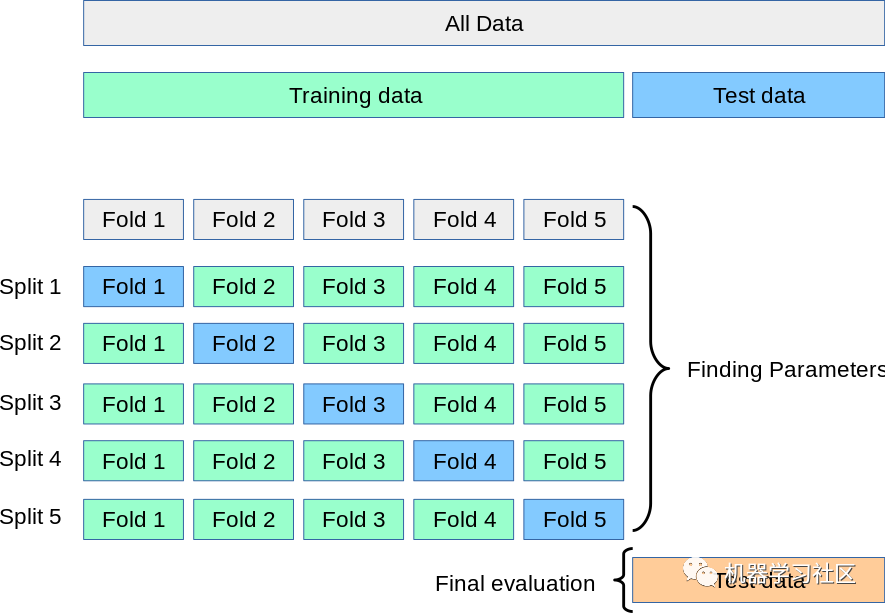
from sklearn.datasets import load_irisfrom sklearn.model_selection import cross_val_score,KFoldfrom sklearn.linear_model import LogisticRegressioniris=load_iris()X=iris.dataY=iris.targetlogreg=LogisticRegression()kf=KFold(n_splits=5)score=cross_val_score(logreg,X,Y,cv=kf)print("Cross Validation Scores are {}".format(score))print("Average Cross Validation score :{}".format(score.mean()))

3、分层 K 折交叉验证
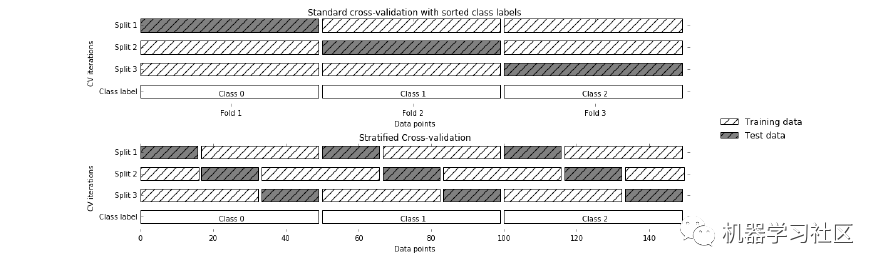
from sklearn.datasets import load_irisfrom sklearn.model_selection import cross_val_score,StratifiedKFoldfrom sklearn.linear_model import LogisticRegressioniris=load_iris()X=iris.dataY=iris.targetlogreg=LogisticRegression()stratifiedkf=StratifiedKFold(n_splits=5)score=cross_val_score(logreg,X,Y,cv=stratifiedkf)print("Cross Validation Scores are {}".format(score))print("Average Cross Validation score :{}".format(score.mean()))

4、Leave P Out 交叉验证
from sklearn.model_selection import LeavePOut,cross_val_scorefrom sklearn.datasets import load_irisfrom sklearn.ensemble import RandomForestClassifieriris=load_iris()X=iris.dataY=iris.targetlpo=LeavePOut(p=2)lpo.get_n_splits(X)tree=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)score=cross_val_score(tree,X,Y,cv=lpo)print("Cross Validation Scores are {}".format(score))print("Average Cross Validation score :{}".format(score.mean()))

5、留一交叉验证
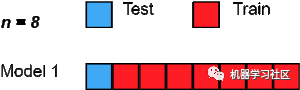
from sklearn.datasets import load_irisfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import LeaveOneOut,cross_val_scoreiris=load_iris()X=iris.dataY=iris.targetloo=LeaveOneOut()tree=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)score=cross_val_score(tree,X,Y,cv=loo)print("Cross Validation Scores are {}".format(score))print("Average Cross Validation score :{}".format(score.mean()))
6、蒙特卡罗交叉验证(Shuffle Split)

from sklearn.model_selection import ShuffleSplit,cross_val_scorefrom sklearn.datasets import load_irisfrom sklearn.linear_model import LogisticRegressionlogreg=LogisticRegression()shuffle_split=ShuffleSplit(test_size=0.3,train_size=0.5,n_splits=10)scores=cross_val_score(logreg,iris.data,iris.target,cv=shuffle_split)print("cross Validation scores:n {}".format(scores))print("Average Cross Validation score :{}".format(scores.mean()))

7、时间序列交叉验证
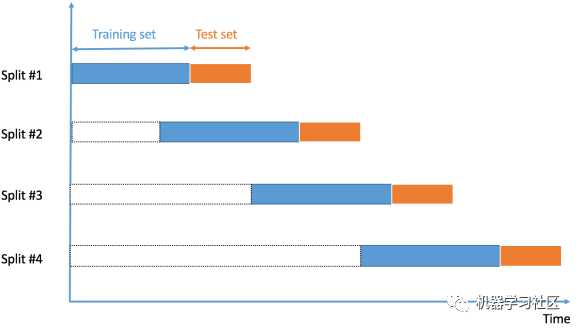
import numpy as npfrom sklearn.model_selection import TimeSeriesSplitX = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])y = np.array([1, 2, 3, 4, 5, 6])time_series = TimeSeriesSplit()print(time_series)for train_index, test_index in time_series.split(X):print("TRAIN:", train_index, "TEST:", test_index)X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]
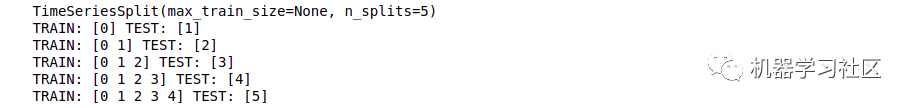
结论
编辑:黄继彦
校对:龚力
评论