
用OpenCV搭建活体检测器
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

照片、视频中的人脸有时也能骗过一些不成熟的人脸识别系统,让人们对人脸解锁的安全性产生很大怀疑。在这篇 4 千多字的教程中,作者介绍了如何用 OpenCV 进行活体检测(liveness detection)。跟随作者给出的代码和讲解,你可以在人脸识别系统中创建一个活体检测器,用于检测伪造人脸并执行反人脸欺骗。
我在过去的一年里写了不少人脸识别的教程,包括:
penCV 人脸识别
用 dlib、Python 和深度学习进行人脸识别
用树莓派实现人脸识别
https://www.pyimagesearch.com/2018/09/24/opencv-face-recognition/
https://www.pyimagesearch.com/2018/06/18/face-recognition-with-opencv-python-and-deep-learning/
https://www.pyimagesearch.com/2018/06/25/raspberry-pi-face-recognition/
但在我的邮件和人脸识别相关帖子下面的评论中经常会出现以下问题:
我该如何识别真假人脸呢?
想想如果有坏人试图攻破你的人脸识别系统会发生什么?
这样的用户可能会拿到另一个人的照片。甚至可能他们的手机上就有其他人的照片或视频,他们可以用这样的照片或视频来欺骗识别人脸的相机(就像本文开头的图片那样)。
在这种情况下,照相机完全有可能将其识别为正确的人脸,从而让未经授权的用户骗过人脸识别系统!
如何识别这些真假人脸呢?如何在人脸识别应用中使用反人脸欺骗算法?
答案是用 OpenCV 实现活体检测——这也是我今天要介绍的内容。
要了解如何用 OpenCV 将活体检测结合到你自己的人脸识别系统中,请继续往下读。
你可以在文末的下载部分下载源代码:
https://www.pyimagesearch.com/2019/03/11/liveness-detection-with-opencv/#
本教程第一部分将讨论什么是活体检测以及为什么要借助活体检测提升我们的人脸识别系统。
从这里开始要先研究一下用于活体检测的数据集,包括:
如何构建活体检测的数据集?
真假面部图像的样例。
我们还将回顾用于活体检测器项目的项目结构。
为了创建活体检测器,我们要训练一个能分辨真假人脸的深度神经网络。
因此,我们还需要:
构建图像数据集;
实现可以执行活体检测的 CNN(我们将这个网络称为「LivenessNet」);
训练活体检测器网络;
创建一个 Python+OpenCV 的脚本,可以通过该脚本使用我们训练好的活体检测器模型,并将其应用于实时视频。
那我们就开始吧!
什么是活体检测?我们为什么需要活体检测?
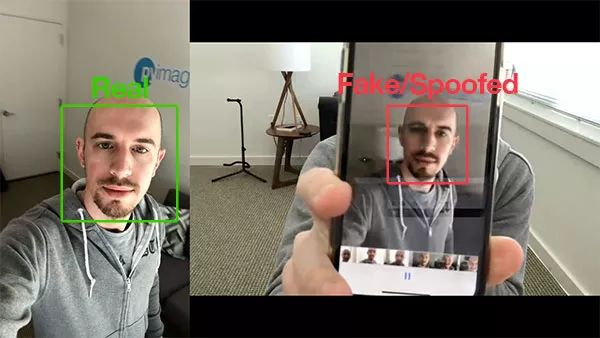
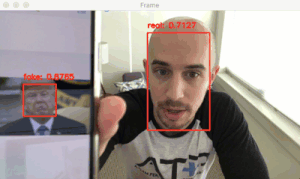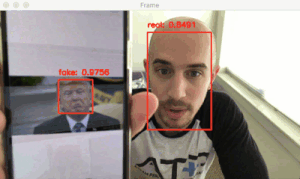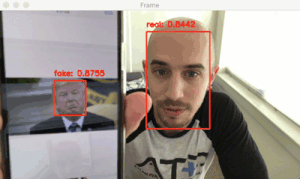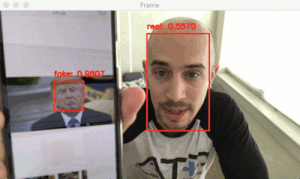
图 1:用 OpenCV 进行活体检测。左图是我的实时(真实)视频,而右图中我拿着自己的 iPhone(欺骗)。
人脸识别系统与以往任何时候相比都更加普遍。从 iPhone(智能手机)中的人脸识别,到中国大规模监控中的人脸识别,人脸识别系统的应用无处不在。
但人脸识别系统也很容易被「伪造」和「不真实」的面部所欺骗。
在面部识别相机前拿着一个人的照片(无论是印出来的还是手机上的)可以轻而易举地骗过人脸识别系统。
为了让人脸识别系统更加安全,我们需要检测出这样伪造的面部——活体检测(术语)指的就是这样的算法。
活体检测的方法有很多,包括:
纹理分析(Texture analysis),该方法计算了面部区域的局部二值模式(Local Binary Patterns,LBP),用 SVM 将面部分为真实面部和伪造面部;
频率分析(Frequency analysis),比如检查面部的傅立叶域;
可变聚焦分析(Variable focusing analysis),例如检查连续两帧间像素值的变化;
启发式算法(Heuristic-Based algorithms),包括眼球运动、嘴唇运动和眨眼检测。这些算法试图追踪眼球运动和眨眼行为,来确保用户不是拿着谁的照片(因为照片不会眨眼也不会动嘴唇);
光流算法(Optical Flow algorithm),即检测 3D 对象和 2D 平面产生的光流的属性和差异;
3D 面部形状(3D face shape),类似于 iPhone 上的面部识别系统,这种算法可以让面部识别系统区分真实面部和其他人的照片或打印出来的图像;
结合以上算法,这种方法可以让面部识别系统工程师挑选适用于自己应用的活体检测模型。
Chakraborty 和 Das 2014 年的论文(《An Overview of Face liveness Detection》)对活体检测算法做了全面的综述。
我们在本教程中将活体检测视为一个二分类问题。
给定输入图像,我们要训练一个能区分真实面部和伪造面部的卷积神经网络(Convolutional Neural Network)。
但在训练活体检测模型之前,我们要先检查一下数据集。
我们的活体检测视频
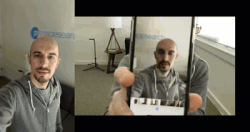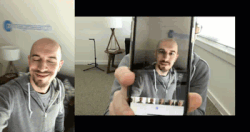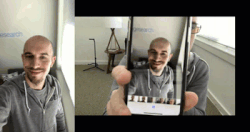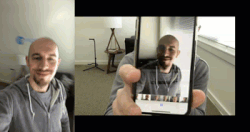
图 2:真实面部和伪造面部的样例。左边的视频是我的面部的真实视频,右边是在播放同样的视频时笔记本录制的视频。
为了让例子更直观,本文建立的活体检测器侧重于区分真实面部和屏幕上的伪造面部。
这一算法可以轻易扩展到其他类型的伪造面部上,比如打印输出的伪造面部和高分辨率输出的伪造面部等。
为了建立活体检测数据集,我做了下列工作:
拿着我的 iPhone,将它设置为人像或自拍模式;
录制约 25 秒我在办公室里来回走的视频;
重播这段 25 秒的视频,这次用我的 iPhone 对着录制了重播视频的电脑;
这样就产生了两段样例视频,一段用于「真实」面部,一段用于「伪造」面部;
最后,我在这两段视频上都用了人脸检测,为这两类提取出单独的面部 ROI(Reign of Interest)。
我在本文的「下载」部分提供了真实面部和伪造面部的视频文件。
你可以将这些视频作为数据集的起点,但我建议你多收集一些数据,这可以让你的活体检测器更鲁棒也更安全。
通过测试,我确定模型有些偏向我的脸,这是意料之中的结果,因为所有的模型都是基于我的面部训练出来的。此外,由于我是白人(高加索人),所以如果数据集中有其他肤色或其他人种的面部时,这个模型效果会没有那么好。
在理想情况下,你应该用不同肤色和不同人种的面部来训练模型。请参考本文的「限制和后续工作」部分,来了解其他改善活体检测模型的建议。
你将在本教程剩下的部分学习如何获取我录制的数据集以及如何将它实际应用于通过 OpenCV 和深度学习建立的活体检测器。
项目结构
你可以通过本教程的「Downloads」部分下载代码、数据和活体模型,然后解压缩存档。
进入项目目录后,你能看到这样的结构:
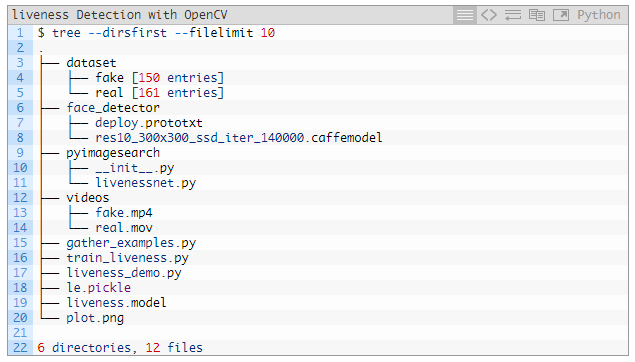
目录中有四个主目录:
dataset/:我们的数据集目录中包含两类图像:
1. 在播放我的面部视频时通过录制屏幕得到的伪造图像;
2. 手机直接拍摄我的面部视频得到的真实图像。
face_detector/:由预训练的 Caffe 面部检测器组成,用来定位面部 ROI;
Pyimagesearch/:该模块包含了 LivenessNet 类;
videos/:这里提供了两段用于训练 LivenessNet 分类器的输入视频。
今天我们会详细地学习三个 Python 脚本。在文章结束后,你可以在自己的数据和输入视频上运行这三个脚本。按在教程中出现的顺序,这三个脚本分别是:
1. gather_examples.py:这个脚本从输入的视频文件中提取了面部 ROI,帮助我们创建了深度学习面部活体数据集;
2. train_liveness.py:如文件名所示,这个脚本用来训练 LivenessNet 分类器。我们将用 Keras 和 TensorFlow 训练模型。在训练过程中会产生一些文件:
le.pickle:分类标签编码器。
liveness.model: 可以检测面部活性的序列化 Keras 模型。
plot.png:训练历史图呈现了准确率和损失曲线,我们可以根据它来评估模型(是否过拟合或欠拟合。)
3. liveness_demo.py:演示脚本,它会启动你的网络摄像头抓取帧,可以进行实时的面部活体检测。
从训练(视频)数据集中检测并提取面部 ROI
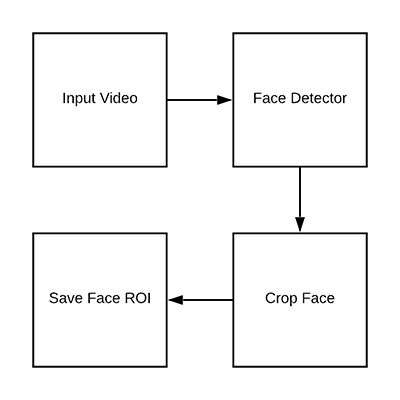
图 3:为了构建活体检测数据集,在视频中检测面部 ROI。
现在有机会看到初始数据集和项目结构了,让我们看看该如何从输入视频中提取出真实面部图像和伪造面部图像吧。
最终目标是用这个脚本填充两个目录:
dataset/fake/:fake.mp4 中的面部 ROI;
dataset/real/:real.mov 中的面部 ROI。
根据这些帧,我们后续将在这些图像上训练基于深度学习的活体检测器。
打开 gataer_examples.py,插入下面的代码:
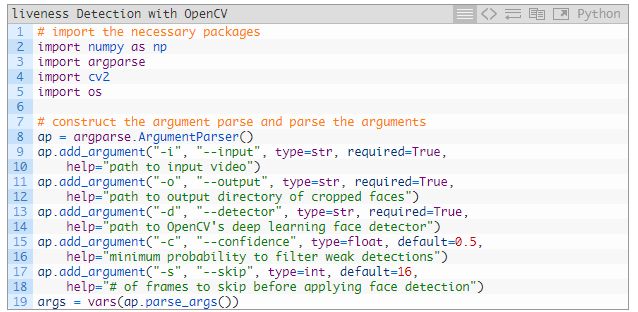
2~5 行导入了我们需要的包。除了内置的 Python 模块外,该脚本只需要 OpenCV 和 NumPy。
8~19 行解析了命令行参数:
--input:输入视频文件的路径
--output:输出目录的路径,截取的每一张面部图像都存储在这个目录中。
--detector:面部检测器的路径。我们将使用 OpenCV 的深度学习面部检测器。方便起见,本文的「Downloads」部分也有这个 Caffe 模型。
--confidence:过滤弱面部检测的最小概率,默认值为 50%。
--skip:我们不需要检测和存储每一张图像,因为相邻的帧是相似的。因此我们在检测时会跳过 N 个帧。你可以使用这个参数并更改默认值(16)。
继续加载面部检测器并初始化视频流:
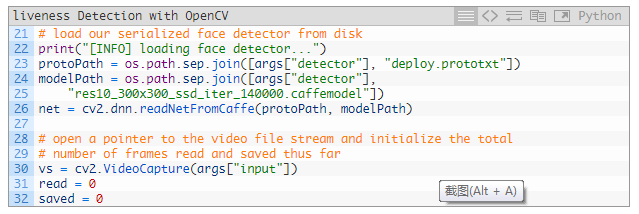
23~26 行加载了 OpenCV 的深度学习面部检测器:
https://www.pyimagesearch.com/2018/02/26/face-detection-with-opencv-and-deep-learning/
从 30 行开始打开视频流。
我们还初始化了两个参数——读取的帧的数量和执行循环时保存的帧的数量(31 和 32 行)。
接着要创建处理帧的循环:
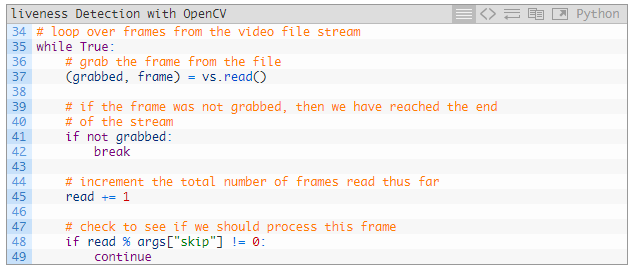
while 循环是从 35 行开始的。
从这里开始我们抓取一帧并进行验证(37~42 行)。
此时,因为已经读取了一个帧,我们将增加读取计数器(48 行)。如果我们跳过特定的帧,也会跳过后面的处理,再继续下一个循环(48 和 49 行)。
接着检测面部:
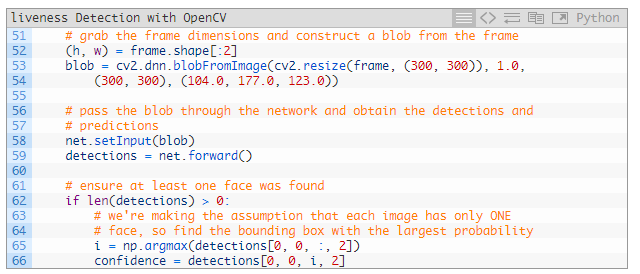
为了进行面部检测,我们要在 53 和 54 行根据图像创建一个 blob。为了适应 Caffe 面部识别器,这个 blob 是 300*300 的。之后还要缩放边界框,因此 52 行抓取了帧的维度。
58 和 59 行通过深度学习面部识别器执行了 blob 的前向传输。
我们的脚本假设视频的每一帧中只有一张面部(62~65 行)。这有助于减少假阳性。如果你要处理的视频中不止有一张面部,我建议你根据需要调整逻辑。
因此,第 65 行抓取了概率最高的面部检测索引。66 行用这个索引计算了检测的置信度。
接下来要过滤弱检测并将面部 ROI 写进磁盘:
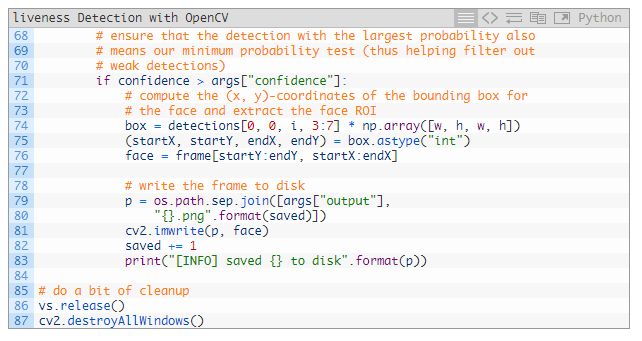
71 行确保我们的面部检测 ROI 满足最小阈值,从而减少假阳性。
在 74~76 行提取了面部 ROI 和相应的边界框。
在 79~81 行为面部 ROI 生成了路径和文件名,并将它写在磁盘上。此时,我们就可以增加保存的面部图像数量了。
处理完成后,我们将在 86 和 87 行执行清理工作。
建立活体检测图像数据集

图 4:OpenCV 面部活体检测数据集。我们要用 Keras 和 OpenCV 来训练并演示活体模型。
现在我们已经实现了 gather_example.py 脚本,接下来要让它开始工作。
确保你已经用这篇教程的「Downloads」部分获取了源代码和输入视频样例。
打开终端并执行下面的命令来提取「伪造」类的面部:
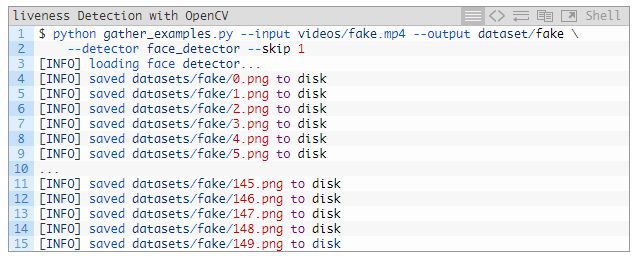
也可以对「真实」类别的面部执行同样的操作:
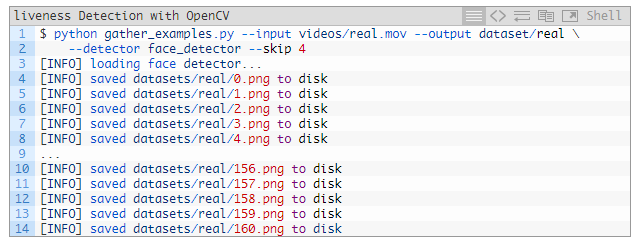
因为「真」视频比「假」视频长,因此我们得把跳过帧的值设置得更长,来平衡每一类输出的面部 ROI 数量。
在执行这个脚本之后,你的图像数量应该如下:
伪造面部:150 张图片;
真实面部:161 张图片;
总数:311 张图片。
实现「LivenessNet」——我们的深度学习活体检测器
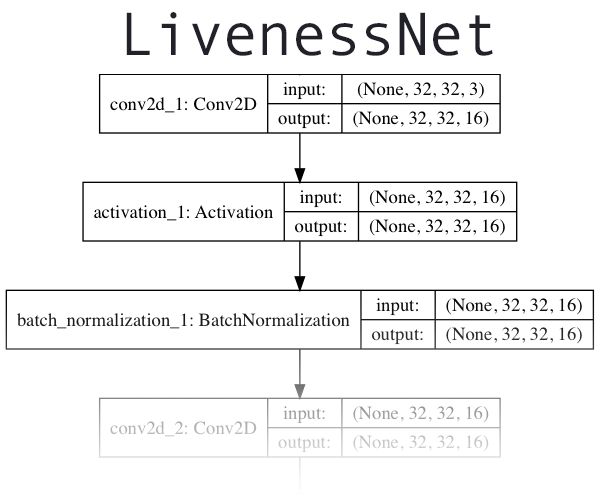
图 5:LivenessNet(一个用来检测图片和视频中面部活性的 CNN)的深度学习架构。
下一步就要实现基于深度学习的活体检测器「LivenessNet」了。
从核心上讲,LivenessNet 实际上就是一个简单的卷积神经网络。
我们要让这个网络尽可能浅,并用尽可能少的参数,原因如下:
避免因数据集小而导致的过拟合;
确保活性检测器足够快,能够实时运行(即便是在像树莓派这样资源受限的设备上)。
现在来实现 LivenessNet 吧。打开 livenessnet.py 并插入下面的代码:
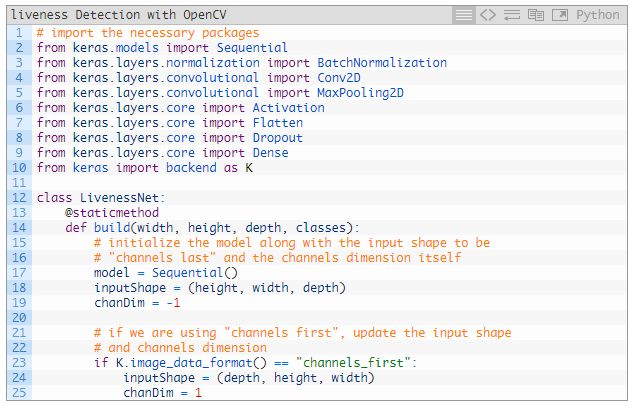
所有导入(import)的包都来自 Keras(2~10 行)。要深入了解这些层和函数,请参考《Deep Learning for Computer Vision with Python》。
第 12 行定义了 LivenessNet 的类。这里用了一种静态方法——build(14 行)。build 方法接受 4 个参数:
width:图片/体积的宽度;
height:图片的高度;
depth:图像的通道数量(本例中是 3,因为我们处理的是 RGB 图像);
classes:类的数量。我们总共有两类:「真」和「假」。
在 17 行初始化模型。
在 18 行定义了 inputShape,在 23~25 行确定了通道顺序。
接着给 CNN 添加层:
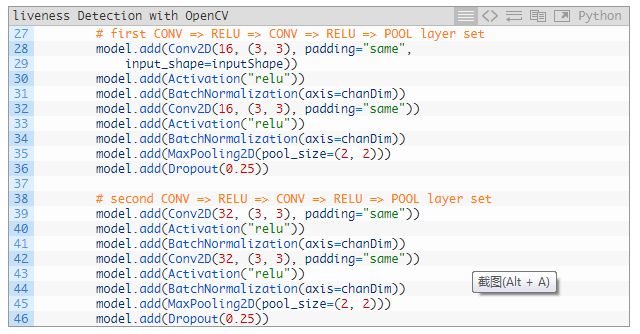
我们的 CNN 展现了 VGGNet 特有的品质——只学习了少量的过滤器。在理想情况下,我们不需要能区分真实面部和伪造面部的深度网络。
28~36 行是第一个层的集合——CONV => RELU => CONV => RELU => POOL,这里还添加了批归一化和 dropout。
39~46 行添加了另一个层集合——CONV => RELU => CONV => RELU => POOL。
最后,我们还要添加 FC => RELU 层:
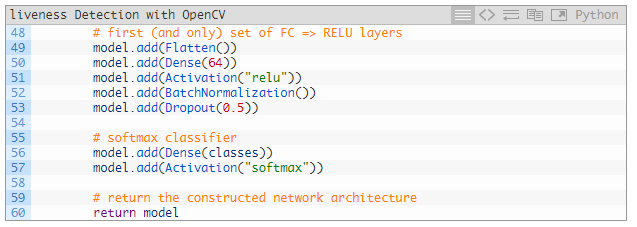
49~57 行添加了全连接层和带有 softmax 分类器 head 的 ReLU 激活层。
模型在 60 行返回到训练脚本。
创建训练活体检测器的脚本
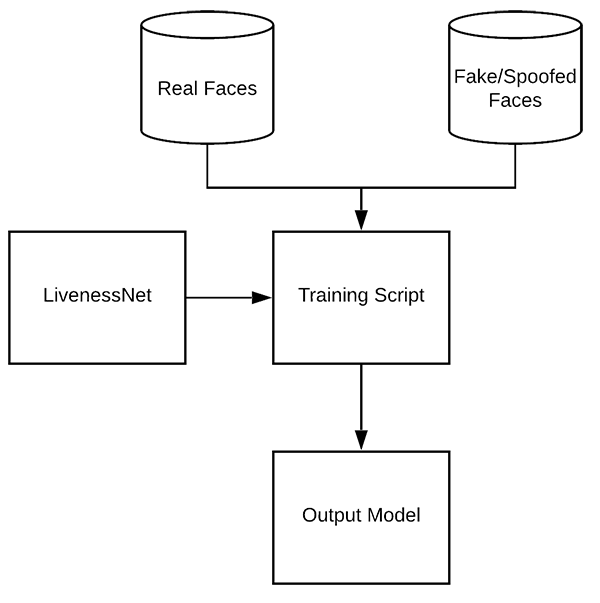
图 6:LivenessNet 的训练过程。同时用「真实」图像和「伪造」图像作为数据集,可以用 OpenCV、Keras 和深度学习训练活体检测模型。
鉴于我们已经有了真实/伪造图像,且已经实现了 LivenessNet,我们现在准备训练网络了。
打开 train_liveness.py 文件,插入下列代码:
训练面部活体检测器的脚本要导入大量的包(2~19 行)。大概了解一下:
matplotlib:用于生成训练图。在第 3 行将后端参数设为「Agg」,这样就可以将生成的图保存在磁盘上了。
LivenessNet:我们之前定义好的用于活体检测的 CNN;
train_test_split:scikit-learn 中的函数,用于将数据分割成训练数据和测试数据;
classification_report:scikit-learn 中的函数,这个工具可以根据模型性能生成简要的统计报告;
ImageDataGenerator:用于数据增强,它生成了一批随机变换后的图像;
Adam:适用于该模型的优化器(也可以用 SGD、RMSprop 等替换);
paths:来自 imutils 包,这个模块可以帮助我们收集磁盘上所有图像文件的路径;
pyplot:用来生成漂亮的训练图;
numpy:Python 的数字处理库。对 OpenCV 来说这个库也是必需的;
argparse:用来处理命令行参数;
pickle:将标签编码器序列化到磁盘;
cv2:绑定了 OpenCV;
os:这个模块可以做很多事,但我们只用它来作操作系统路径分隔符。
现在你知道导入的都是些什么了,可以更直接地查看脚本剩余的部分。
这个脚本接受四个命令行参数:
--dataset:输入数据集的路径。我们在本教程前面的部分用 gather_examples.py 脚本创建了数据集。
--model:我们的脚本会生成一个输出模型文件,在这个参数中提供路径。
--le:这里要提供输出序列化标签编码器文件的路径。
--plot:训练脚本会生成一张图。如果要覆盖默认值「plog.png」,那你就要在命令行中指定值。
下面的代码块要进行大量的初始化工作,还要构建数据:
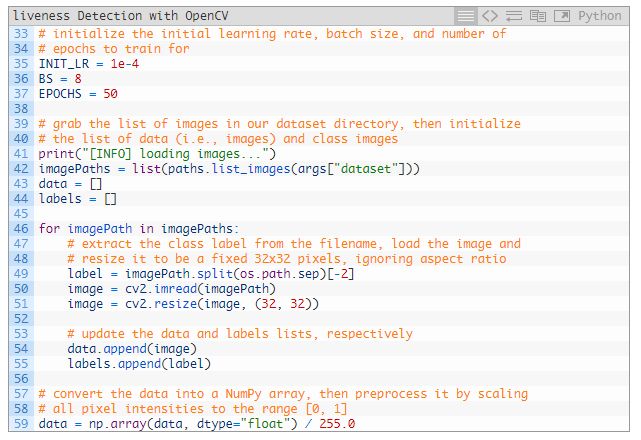
在 35~37 行要设置训练参数,包含初始化学习率、批大小和 epoch 的数量。
在 42~44 行要抓取 imagePaths。我们还要初始化两个列表来存放数据和类别标签。
46~55 行的循环用于建立数据和标签列表。数据是由加载并将尺寸调整为 32*32 像素的图像组成的,标签列表中存储了每张图相对应的标签。
在 59 行将所有像素缩放到 [0,1] 之间,并将列表转换为 NumPy 数组。
现在来编码标签并划分数据:
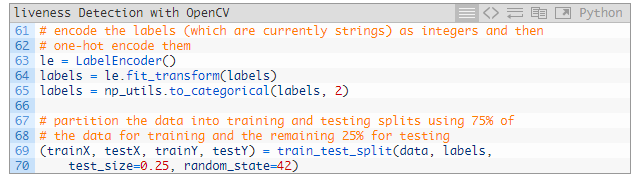
63~65 行对标签进行 one-hot 编码处理。
在 69 和 70 行用 scikit-learn 划分数据————将数据的 75% 用来训练,剩下的 25% 用来测试。
接下来要初始化数据增强对象、编译和训练面部活性模型:
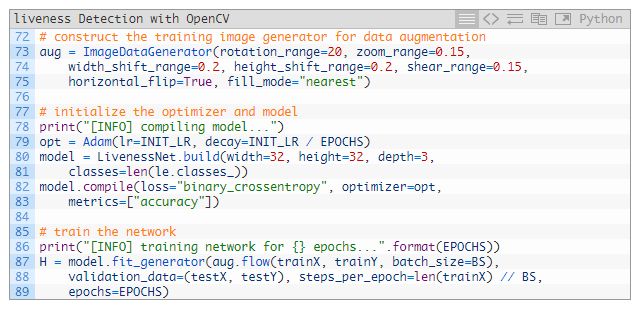
73~75 行构造了数据增强对象,这个过程通过随机的旋转变换、缩放变换、平移变换、投影变换以及翻转变换来生成图像。
在 79~83 行中建立并编译了我们的 LivenessNet 模型。
在 87~89 行着手训练。考虑到模型较浅且数据集较小,因此这个过程相对而言会快一些。
模型训练好后,就可以评估结果并生成训练图了:
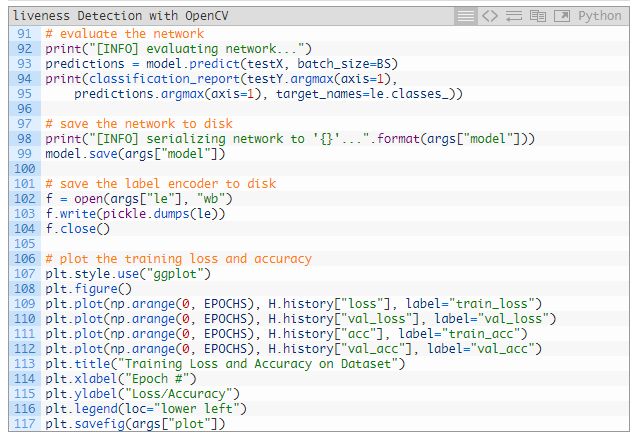
在测试集上作出预测(93 行)。94 和 95 行生成了 classification_report,并将结果输出在终端上。
99~104 行将 LivenessNet 模型和标签编码器一起序列化到磁盘上。
剩下的 107~117 行则为后续的检查生成了训练历史图。
训练活体检测器
我们现在准备训练活体检测器了。
确保你已经通过本教程的「Downloads」部分下载了源代码和数据集,执行以下命令:
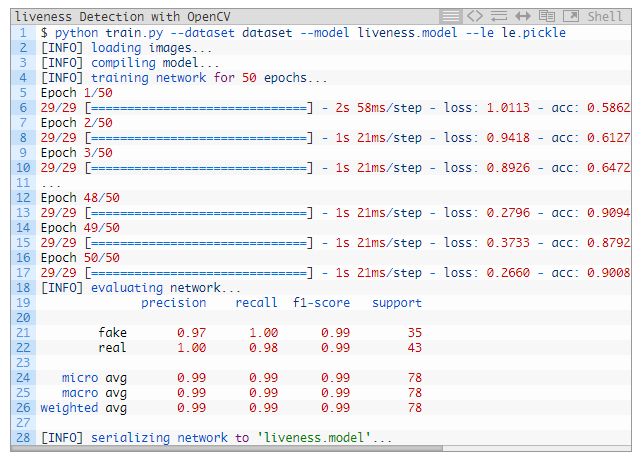
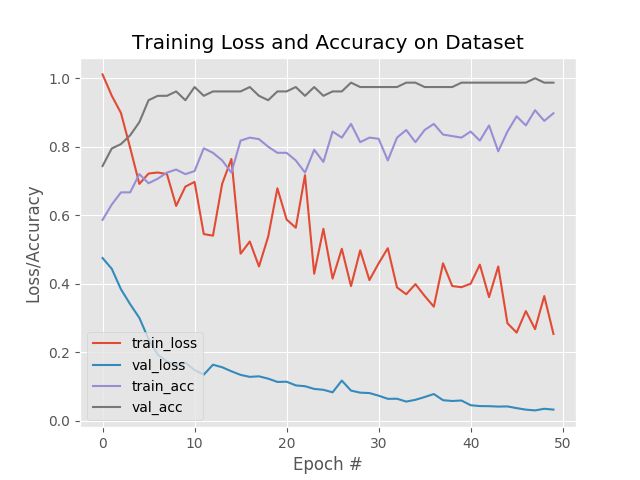
图 6:用 OpenCV、Keras 和深度学习训练面部活体模型的图。
结果表明,我们的活体检测器在验证集上的准确率高达 99%!
将各个部分组合在一起:用 OpenCV 做活体检测
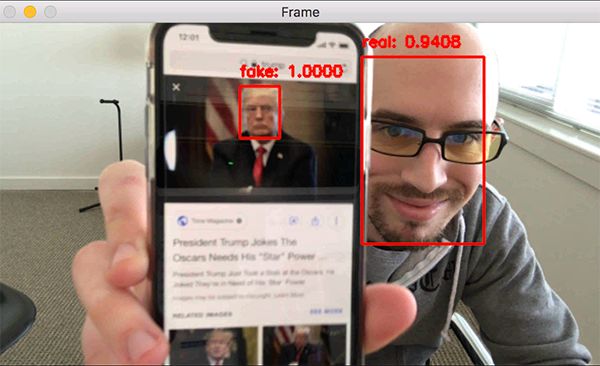
图 7:用 OpenCV 和深度学习做面部活性检测。
最后一步是将各个部分组合在一起:
访问网络摄像头/视频流
将面部检测应用到每一帧
对面部检测的结果应用活体检测器模型
打开 liveness_demo.py 并插入以下代码:
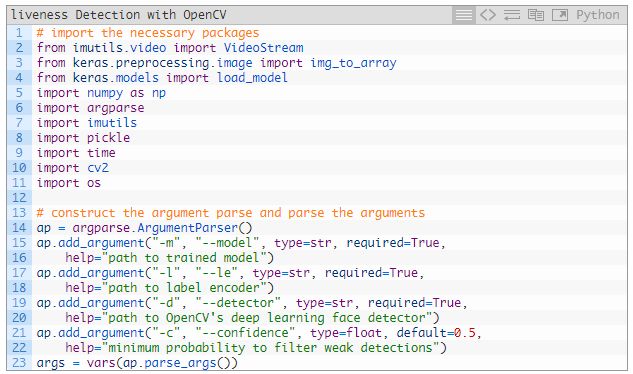
2~11 行导入了需要的包。值得注意的是:
会使用 VideoStream 来访问相机馈送
使用 img_to_array 来使帧采用兼容的数组形式
用 load_model 来加载序列化的 Keras 模型
为了方便起见还要使用 imutils
用 cv2 绑定 OpenCV
解析 14~23 行命令行的参数:
--model:用于活性检测的预训练 Keras 模型的路径;
--le:标签编码器的路径;
--detector:用来寻找面部 ROI 的 OpenCV 的深度学习面部检测器路径;
--confidence:滤出弱检测的最小概率阈值。
现在要继续初始化面部检测器、LivenessNet 模型和标签编码器,以及视频流:
27~30 行加载 OpenCV 人脸检测器。
34 和 35 行加载序列化的预训练模型(LivenessNet)和标签编码器。
39 和 40 行实例化 VideoStream 对象,允许相机预热两秒。
此时开始遍历帧来检测真实和虚假人脸:
43 行开启了无限的 while 循环块,从这里开始捕获并调整各个帧的大小(46 和 47 行)。
调整帧的大小后,抓取帧的维度,以便稍后进行缩放(50 行)。
用 OpenCV 的 blobFromImage 函数可以生成 blob(51 和 52 行),然后将其传到面部检测器网络,再继续推理(56 和 57 行)。
现在可以进行有意思的部分了——用 OpenCV 和深度学习做活性检测:

在 60 行开始循环遍历面部检测。在这个过程中,我们:
滤出弱检测(63~66 行);
提取对应的面部边界框,确保它们没有超出帧(69~77 行);
提取面部 ROI,用处理训练数据的方式对面部 ROI 进行预处理(81~85 行);
部署活性检测器模型,确定面部图片是「真实的」还是「伪造的」(89~91 行);
当检测出是真实面部时,直接在 91 行后面插入面部识别的代码。伪代码类似于:if label == "real": run_face_reconition();
最后(在本例中)绘制出标签文本并框出面部(94~98 行)。
展示结果并清理:
当捕获按键时,在循环的每一次迭代中显示输出帧。无论用户在什么时候按下「q」(「退出」),都会跳出循环、释放指针并关闭窗口(105~110 行)。
在实时视频中部署活体检测器
要继续本教程,请确保你已经通过本教程的「Downloads」部分下载了源代码和预训练的活体检测模型。
打开终端并执行下列命令:

在这里可以看到我们的活性检测器成功地分辨出真实面部和伪造面部。
下面的视频中有更长的演示:
限制、改进和进一步工作
本教程中的活体检测器的主要限制在于数据集的限制——数据集中只有 311 张图片(161 个「真实」类和 150 个「伪造」类)。
这项工作第一个要扩展的地方就是要收集更多的训练数据,更具体地说,不只是要有我或你自己的图像(帧)。
记住,这里用的示例数据集只包括一个人(我)的面部。我是个白人(高加索人),而你收集的训练数据中还应该有其他人种或其他肤色的面部。
我们的活体检测器只是针对屏幕上显示的伪造面部训练的——并没有打印出来图像或照片。因此,我的第三个建议是除了屏幕录制得到的伪造面部外,还应该有通过其他方式伪造的面部资源。
我最后要说的是,这里的活体检测并未涉及任何新技术。最好的活体检测器会包含多种活性检测的方法(请参考前文中提到的《What is liveness detection and why do we need it?》)。
花些时间思考并评估你自己的项目、指南和需求——在某些情况下,你可能只需要基本的眨眼检测启发式。
而在另一些情况中,你可能需要将基于深度学习的活体检测和其他启发式结合在一起。
不要急于进行人脸识别和活体检测——花点时间思考你的项目独一无二的需求。这么做可以确保你获得更好、更准确的结果。
你将在本教程中学习如何用 OpenCV 进行活体检测。你现在就可以在自己的面部识别系统中应用这个活体检测器,来发现伪造的面部并进行反面部欺骗。
我们用 OpenCV、深度学习和 Python 创建了自己的活体检测器。
第一步是要收集真实面部和虚假面部的数据集。为了完成这项任务,我们:
首先用智能手机录制了一段自己的视频(即「真实」面部);
将手机放在笔记本电脑或桌面上,重播同样的视频,用网络摄像头录制重播的视频(即「伪造」面部);
在这两段视频上使用面部检测器,来生成最终的活体检测数据集。
在构建数据集之后,我们实现了「LivenessNet」,它集成了 Keras 和深度学习 CNN。
我们有意让这个网络尽可能浅,以确保:
减少模型因数据集太小而导致的过拟合情况;
模型可以实时运行(包括树莓派)
总体来说,我们的活体检测器在验证集上的准确率高达 99%。
为了演示完整的活体检测流程,我们创建了一个 Python+OpenCV 的脚本,它可以加载我们的活体检测器,并且可以将它应用在实时的视频流上。
正如演示所示,我们的活体检测器可以区分真实面部和伪造面部。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~