
【Python基础】Pandas笔记---通过比赛整理出的10条Pandas实用技巧
点击上方“潜心的Python小屋”关注我们,第一时间推送优质文章。
前言
大家好,我是潜心。最近还在参加某比赛,将pandas对数据预处理的方法进行了总结,以下列出的10条是我觉得比较常用、好用的处理操作。
本文约3k字,预计阅读15分钟。
1. 连接Pandas对象---concat()
concat方法是沿着某条轴,将多个DataFrame/Series对象进行连接在一起。
主要用途: 对某些对象只进行简单的行连接或列连接。
def concat(objs, axis=0, join="outer", ignore_index: bool = False, keys=None, levels=None, names=None, verify_integrity: bool = False, copy: bool = True)
主要参数介绍:
objs:多个对象; axis:指定连接的轴,0(行)或1(列); join:连接的方式,outer(外连接)或inter(内连接); ingnore_index:是否重建索引;
例:
In[1]: df1 = pd.DataFrame(np.random.randint(10, size=(3, 3)), columns=['A', 'B', 'C'])
A B C
0 1 4 8
1 8 8 4
2 0 9 3
In[2]: df2 = pd.DataFrame(np.random.randint(10, size=(2, 2)), columns=['A', 'B'])
A B
0 3 9
1 8 6
In[3]: pd.concat([df1, df2], axis=0, join='outer')
A B C
0 1 4 8.0
1 8 8 4.0
2 0 9 3.0
0 3 9 NaN
1 8 6 NaN
In[4]: pd.concat([df1, df2], axis=0, join='inner', ignore_index=True)
A B
0 1 4
1 8 8
2 0 9
3 3 9
4 8 6
In[5]: pd.concat([df1, df2], axis=1, join='outer')
A B C A B
0 1 4 8 3.0 9.0
1 8 8 4 8.0 6.0
2 0 9 3 NaN NaN
2. 合并Pandas对象---merge()
类似于关系数据库的连接方式,根据一个或多个键(即列)将不同的DataFrame连接起来。
主要用途:对于拥有相同的键的两个DataFrame对象,需要将其进行有效的拼接,整合到一个对象。
def merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
主要参数介绍:
left:DataFrame对象; right:DataFrame对象; how:连接方式,inner或outer; on:指定用于连接的键,必须存在于左右两个DataFrame中; left_on:左侧DataFrame中用于连接键的列名,当左右对象列名不同但含义相同时使用; right_on:右侧DataFrame中用于连接键的列名; left_index:使用左侧DataFrame的行索引作为连接键(配合right_on); right_index:使用右侧DataFrame的行索引作为连接键(配合left_on); sort:对其按照连接键进行排序;
例:
In[6]: pd.merge(df1, df2, how='inner', on='A')
A B_x C B_y
0 8 8 4 6
In[7]: pd.merge(df1, df2, how='outer', on='B')
A_x B C A_y
0 1.0 4 8.0 NaN
1 8.0 8 4.0 NaN
2 0.0 9 3.0 3.0
3 NaN 6 NaN 8.0
In[8]: pd.merge(df1, df2, how='outer', left_on='B', right_on='A')
A_x B_x C A_y B_y
0 1.0 4.0 8.0 NaN NaN
1 8.0 8.0 4.0 8.0 6.0
2 0.0 9.0 3.0 NaN NaN
3 NaN NaN NaN 3.0 9.0
3. 删除重复项---drop_duplicates()
删除对象DataFrame中重复的行,重复通过参数subset指定。
主要用途:统计对象中不重复的个数;
def drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
主要参数介绍:
subset:指定的键(列),默认为所有的列(即每行全部相同); keep:删除重复项,除了第1个(first)或者最后一个(last); inplace:是否直接对原来的对象进行修改,默认为False,生成一个拷贝; ignore_index:是否重建索引;
例:
df1
A B C
0 3 2 4
1 6 4 2
2 3 4 3
3 3 7 0
4 5 1 6
5 6 1 4
In[9]: df1.drop_duplicates('A')
A B C
0 3 2 4
1 6 4 2
4 5 1 6
4. Series中的去重---unique()
相比于drop_duplicates方法,unique()只针对于Series对象,类似于Set。
主要用途: 通常是对DataFrame中提取某一键,变成Series,再去重,统计个数。
Series.unique()
例:
In[10]: len(df1['A'].unique().tolist())
3
5. 排序---sort_values()
按照某个键进行排序。
主要用途:查看相同键时行的某些变化,如例子中在A相同时B、C的变化。
def sort_values(by, axis=0, ascending=True, kind='quicksort', na_position='last', ignore_index=False)
主要参数介绍:
by:字符串或字符串列表,指定按照哪个键/索引进行排序; axis:指定排序的轴; ascending:升序或降序,默认为升序; kind:指定排序方法,‘quicksort’, ‘mergesort’, ‘heapsort; ignore_index:是否重建索引;
例:
In[11]: df1.sort_values(by='A')
A B C
0 3 2 4
2 3 4 3
3 3 7 0
4 5 1 6
1 6 4 2
5 6 1 4
6. 采样---sample()
对对象进行采样。
主要用途: 当DataFrame对象数据量太大,导致做实验过满时,可以抽取一部分进行实验,提高效率。
def sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
主要参数介绍:
n:指定采样的数量; frac:指定采样的比例,与n只能选择其中一个; replace:允许或不允许对同一行进行多次采样; weights:采样的权重,默认为“None”将导致相同的概率权重; random_state:类似于seed作用; axis:指定采样的轴,默认为行;
例:
In[12]: df1.sample(n=3)
A B C
0 3 2 4
3 3 7 0
1 6 4 2
In[13]: df1.sample(frac=0.1)
A B C
1 6 4 2
7. 对象分组---groupby()
groupby方法是对对数据内部进行分组处理。
主要用途: 在数据挖掘中主要用在了Word2vec中,例如对每个用户的行为进行分组,形成多个句子。
直观理解:
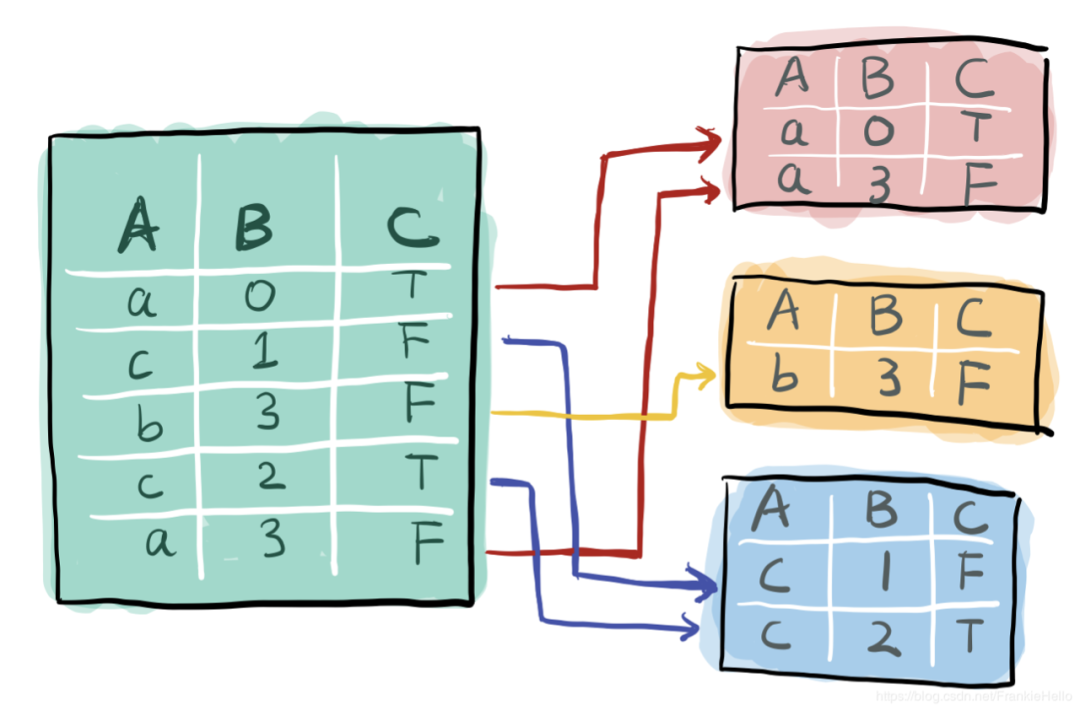
def groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False)
主要参数介绍:
by:用于确定groupby的组; axis:指定轴;
例(以下是最近构造的Word2vec中的句子):
groups = df_log.groupby(['user_id'])
df_log['creative_id'] = df_log['creative_id'].astype('str')
print('starting....')
sentences = [groups.get_group(g)['creative_id'].tolist() for g in groups.groups]
8. 判断与删除缺失值NaN---isna()、isnull()和dropna()
isna方法返回一个布尔对象,每个元素是否为NaN。
例:
df1
A B C
0 1.0 2 3
1 NaN 5 6
In[14]: df1.isna()
A B C
0 False False False
1 True False False
当数据量很大时,上述很难观察到某列是否存在缺失,此时可以用isnull()方法
In[15]: df1.isnull().all() # 某列是否全部为NaN
A False
B False
C False
dtype: bool
In[16]: df1.isnull().any() # 某列是否出现NaN
A True
B False
C False
dtype: bool
dropna方法删除含缺失值的行或列。
def dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
主要参数介绍:
axis:指定轴; how:参数为any时,行或列(axis决定)出现NaN时,就进行删除;为all时,行或列全为NaN时才进行删除; thresh:阈值,要求不为NAN的个数; subset:指定键(列)进行判断NAN删除; inplace:是否更改原对象;
例:
In[17]: df1.dropna(how='any')
A B C
0 1 2 3
In[18]: df1.dropna(how='any', subset=['B'])
A B C
0 1 2 3
1 NaN 5 6
9. 筛选或删除特定值的行---isin()
判断对象中是否存在某个值(列表、Series或DataFrame)。
主要用途: 当缺失值不为NaN时,例如缺失值是一个字符串“\N“(比赛中碰到了),要想更改或删除,则用isin方法较为方便,通过加负号想删除符合条件的行,不写负号是筛选出符合条件的行。
def isin(values)
values:需要判断的值列表(不能为单个数值或字符串),可以为一个Series,或DataFrame(当对象为DataFrame);
例(删除包含某字符串的行):
df1
A B C
0 1 2 3
1 4 \N 6
2 7 8 9
In[19]: df1[-df1.B.isin(['\\N'])]
A B C
0 1 2 3
2 7 8 9
筛选过程中,isin()方法只能判断包含,布尔方法则可以进行更丰富的筛选:
df1
A B C
0 3 4 2
1 0 5 4
2 0 7 5
3 3 2 5
4 2 0 0
5 5 3 7
In[20]: df1[df1.A > 2]
A B C
0 3 4 2
3 3 2 5
5 5 3 7
10. 值替换---where()
通过布尔序列选择一个返回的子集。
主要用途: 对对象进行筛选,并且对于不满足的值,where方法可以对其进行替换。例如若列为性别,元素为字符串,可将其进行替换为数值。
例:
df1
A B C
0 5 7 4
1 2 0 5
2 4 2 4
3 2 6 2
4 5 1 6
5 3 3 4
In[21]: df1.where(df1 > 3, -1)
A B C
0 5 7 4
1 -1 -1 5
2 4 -1 4
3 -1 6 -1
4 5 -1 6
5 -1 -1 4
关于值替换,还可以用如下布尔判断方法:
In[22]: df1[df1.A <= 3] = -1
A B C
0 5 7 4
1 -1 0 5
2 4 2 4
3 -1 6 2
4 5 1 6
5 -1 3 4
注意: where()方法是对不满足的进行替换,上述方法是对满足条件的进行替换
总结
果然真正的打比赛才能发现有那么多知识已经遗忘,记得及时整理才能方便以后进行巩固。
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):