
整理了 25 个 Pandas 实用技巧

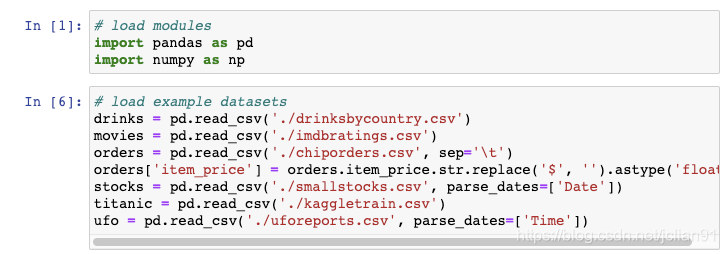
drinksbycountry.csv : http://bit.ly/drinksbycountry imdbratings.csv : http://bit.ly/imdbratings chiporders.csv : http://bit.ly/chiporders smallstockers.csv : http://bit.ly/smallstocks kaggletrain.csv : http://bit.ly/kaggletrain uforeports.csv : http://bit.ly/uforeports
1. 显示已安装的版本
输入下面的命令查询pandas版本:

如果你还想知道pandas所依赖的模块的版本,你可以使用show_versions()函数:

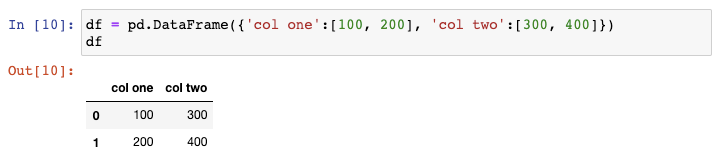
2. 创建示例DataFrame
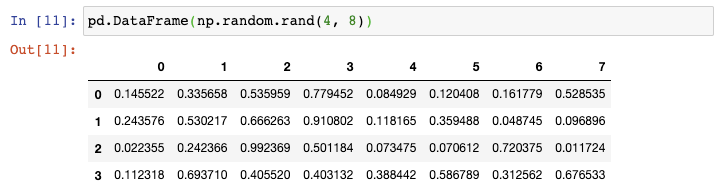
现在如果你需要创建一个更大的DataFrame,上述方法则需要太多的输入。在这种情况下,你可以使用Numpy的random.rand()函数,告诉它行数和列数,将它传递给DataFrame constructor:
这种方式很好,但如果你还想把列名变为非数值型的,你可以强制地将一串字符赋值给columns参数:
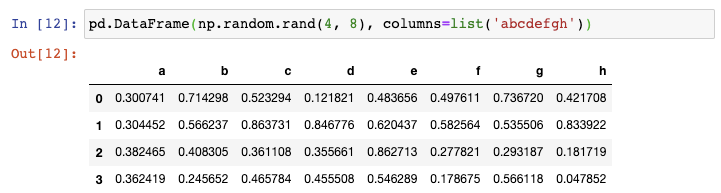
你可以想到,你传递的字符串的长度必须与列数相同。
3. 更改列名
我更喜欢在选取pandas列的时候使用点(.),但是这对那么列名中含有空格的列不会生效。让我们来修复这个问题。

使用这个函数最好的方式是你需要更改任意数量的列名,不管是一列或者全部的列。

如果你需要做的仅仅是将空格换成下划线,那么更好的办法是使用str.replace()方法,这是因为你都不需要输入所有的列名:

上述三个函数的结果都一样,可以更改列名使得列名中不含有空格:

最后,如果你需要在列名中添加前缀或者后缀,你可以使用add_prefix()函数:

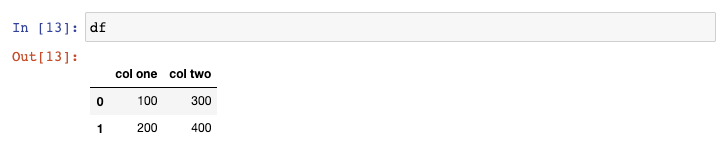
或者使用add_suffix()函数:
4. 行序反转
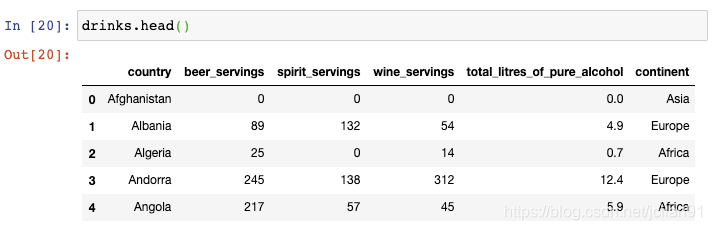
该数据集描述了每个国家的平均酒消费量。如果你想要将行序反转呢?
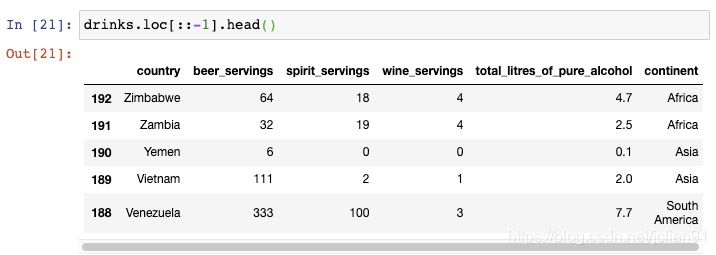
如果你还想重置索引使得它从0开始呢?
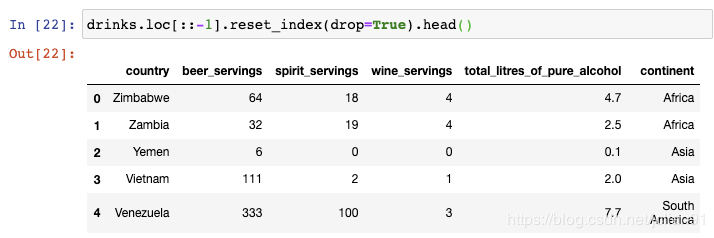
你可以看到,行序已经反转,索引也被重置为默认的整数序号。
5. 列序反转
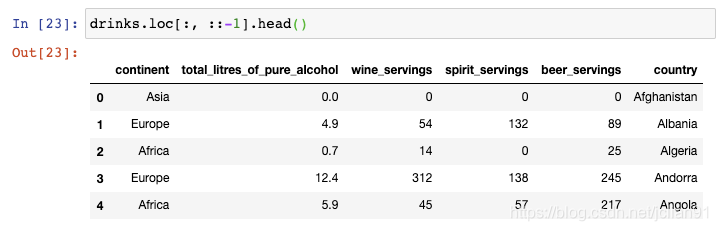
逗号之前的冒号表示选择所有行,逗号之后的::-1表示反转所有的列,这就是为什么country这一列现在在最右边。
6. 通过数据类型选择列
假设你仅仅需要选取数值型的列,那么你可以使用select_dtypes()函数:
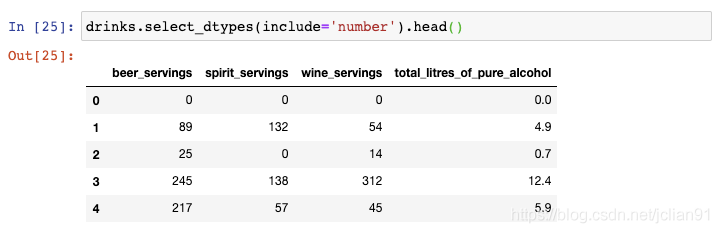
这包含了int和float型的列。
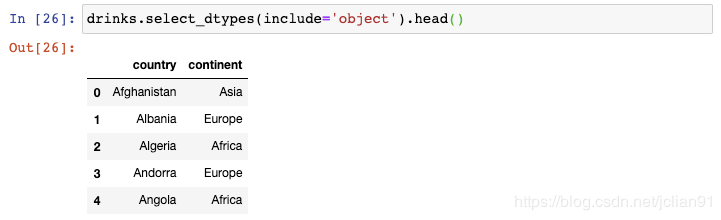
你还可以选取多种数据类型,只需要传递一个列表即可:
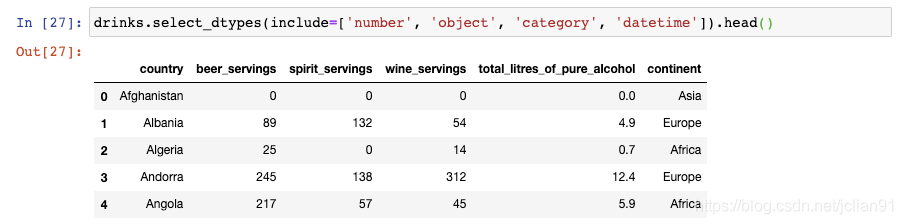
你还可以用来排除特定的数据类型:
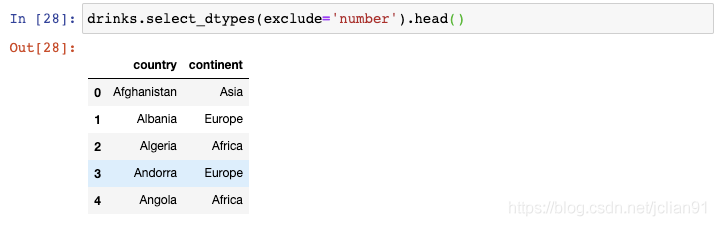
7. 将字符型转换为数值型
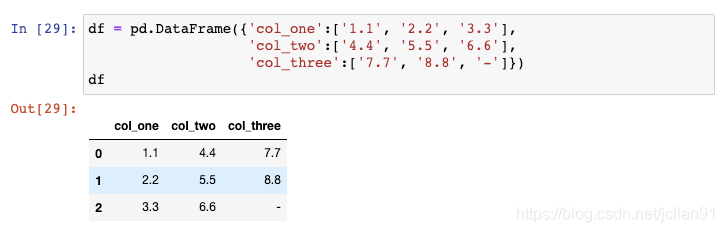
这些数字实际上储存为字符型,导致其数据类型为object:

为了对这些列进行数学运算,我们需要将数据类型转换成数值型。你可以对前两列使用astype()函数:

但是,如果你对第三列也使用这个函数,将会引起错误,这是因为这一列包含了破折号(用来表示0)但是pandas并不知道如何处理它。

如果你知道NaN值代表0,那么你可以fillna()函数将他们替换成0:

最后,你可以通过apply()函数一次性对整个DataFrame使用这个函数:
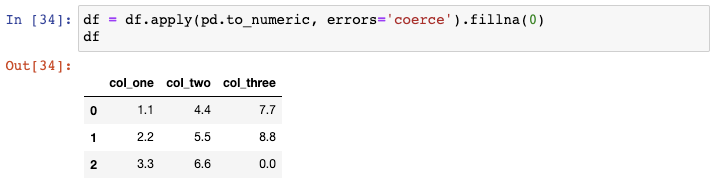
仅需一行代码就完成了我们的目标,因为现在所有的数据类型都转换成float:

8. 减小DataFrame空间大小
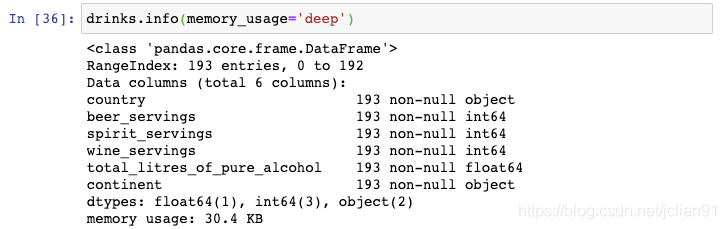
可以看到它使用了304.KB。

通过仅读取用到的两列,我们将DataFrame的空间大小缩小至13.6KB。
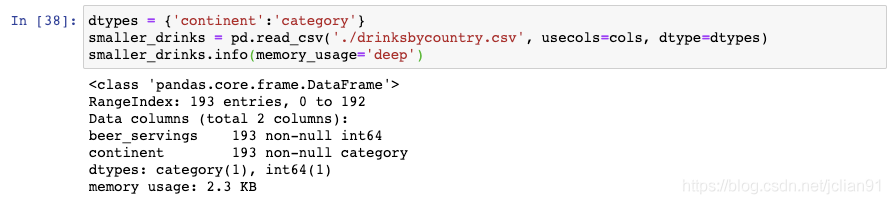
通过将continent列读取为category数据类型,我们进一步地把DataFrame的空间大小缩小至2.3KB。
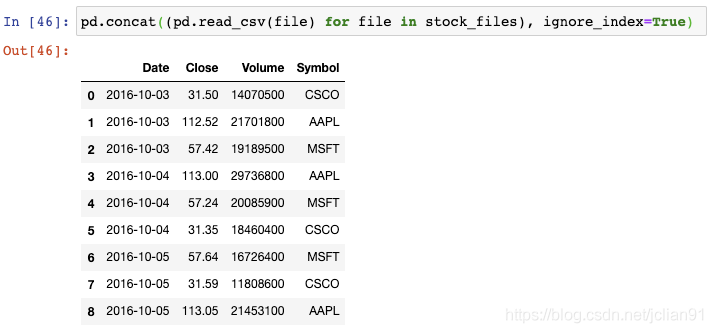
9. 按行从多个文件中构建DataFrame

这是第二天的:

这是第三天的:

你可以将每个CSV文件读取成DataFrame,将它们结合起来,然后再删除原来的DataFrame,但是这样会多占用内存且需要许多代码。

glob会返回任意排序的文件名,这就是我们为什么要用Python内置的sorted()函数来对列表进行排序。
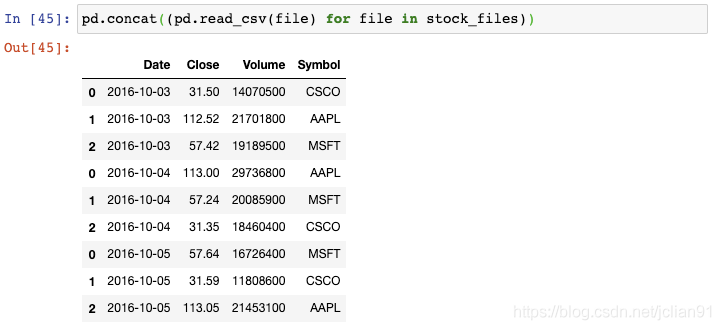
不幸的是,索引值存在重复。为了避免这种情况,我们需要告诉concat()函数来忽略索引,使用默认的整数索引:
10. 按列从多个文件中构建DataFrame
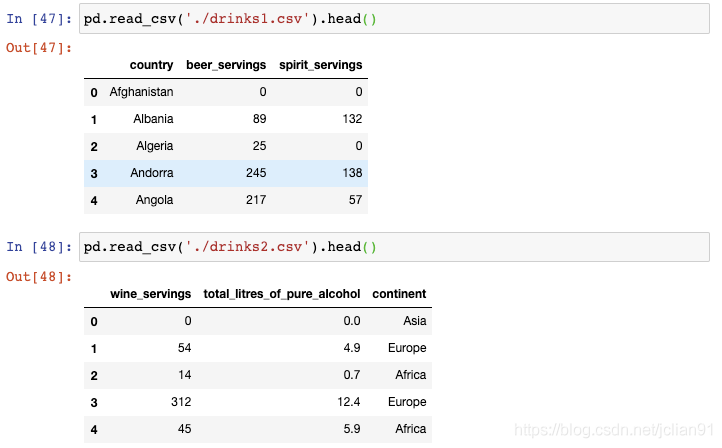
同上一个技巧一样,我们以使用glob()函数开始。这一次,我们需要告诉concat()函数按列来组合:
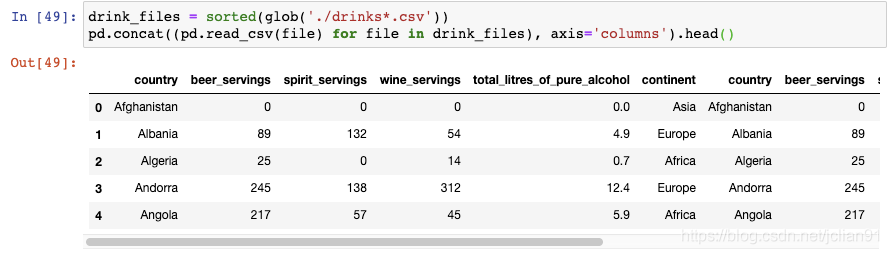
现在我们的DataFrame已经有六列了。
11. 从剪贴板中创建DataFrame
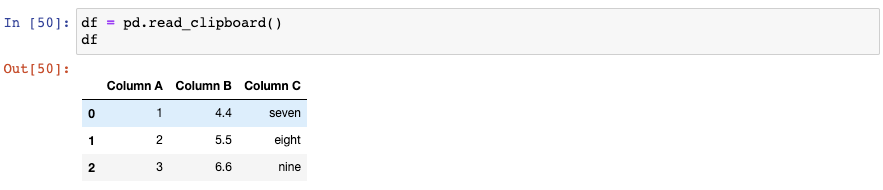
和read_csv()类似,read_clipboard()会自动检测每一列的正确的数据类型:

让我们再复制另外一个数据至剪贴板:
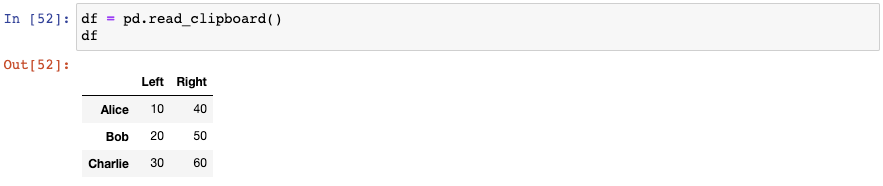
神奇的是,pandas已经将第一列作为索引了:

需要注意的是,如果你想要你的工作在未来可复制,那么read_clipboard()并不值得推荐。
12. 将DataFrame划分为两个随机的子集

我们可以使用sample()函数来随机选取75%的行,并将它们赋值给"movies_1"DataFrame:

接着我们使用drop()函数来舍弃“moive_1”中出现过的行,将剩下的行赋值给"movies_2"DataFrame:

你可以发现总的行数是正确的:

你还可以检查每部电影的索引,或者"moives_1":

或者"moives_2":

需要注意的是,这个方法在索引值不唯一的情况下不起作用。
13. 通过多种类型对DataFrame进行过滤
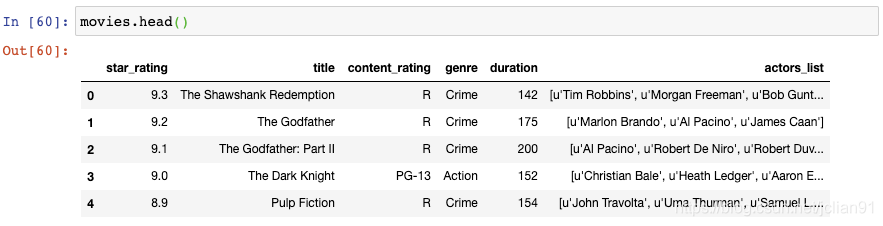
其中有一列是genre(类型):

比如我们想要对该DataFrame进行过滤,我们只想显示genre为Action或者Drama或者Western的电影,我们可以使用多个条件,以"or"符号分隔:

但是,你实际上可以使用isin()函数将代码写得更加清晰,将genres列表传递给该函数:
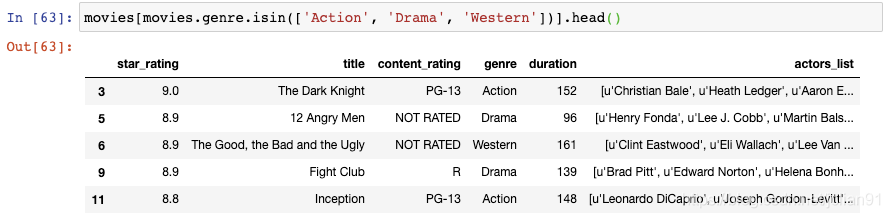
如果你想要进行相反的过滤,也就是你将吧刚才的三种类型的电影排除掉,那么你可以在过滤条件前加上破浪号:
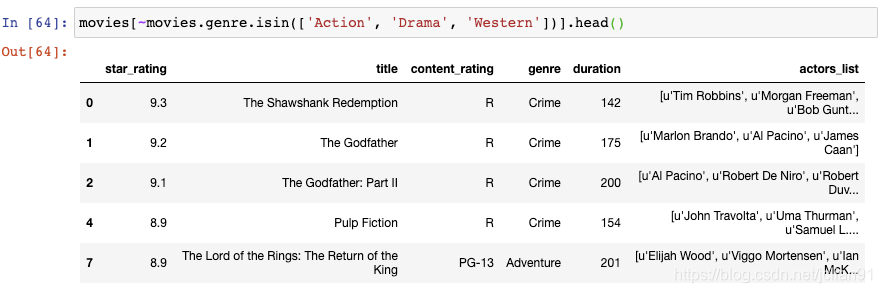
这种方法能够起作用是因为在Python中,波浪号表示“not”操作。
14. 从DataFrame中筛选出数量最多的类别
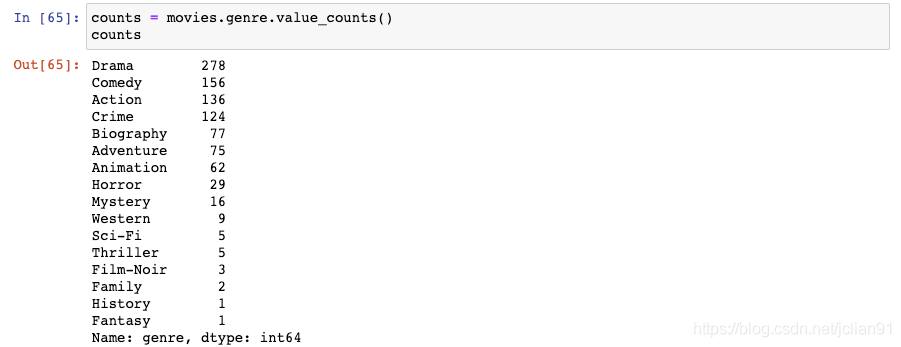
该Series的nlargest()函数能够轻松地计算出Series中前3个最大值:

事实上我们在该Series中需要的是索引:

最后,我们将该索引传递给isin()函数,该函数会把它当成genre列表:
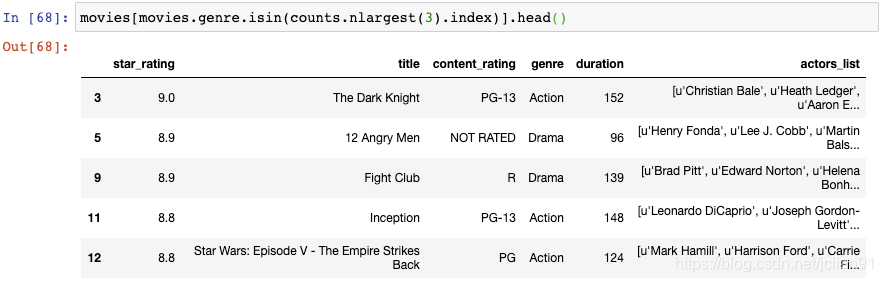
这样,在DataFrame中只剩下Drame, Comdey, Action这三种类型的电影了。
15. 处理缺失值
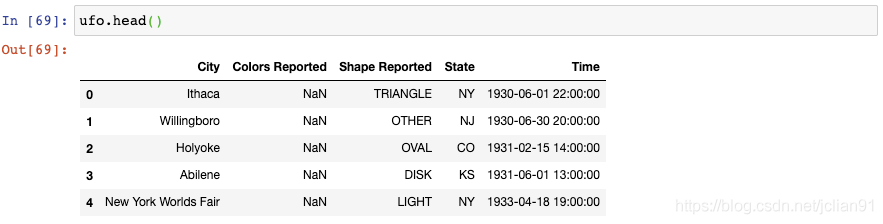
你将会注意到有些值是缺失的。

isna()会产生一个由True和False组成的DataFrame,sum()会将所有的True值转换为1,False转换为0并把它们加起来。

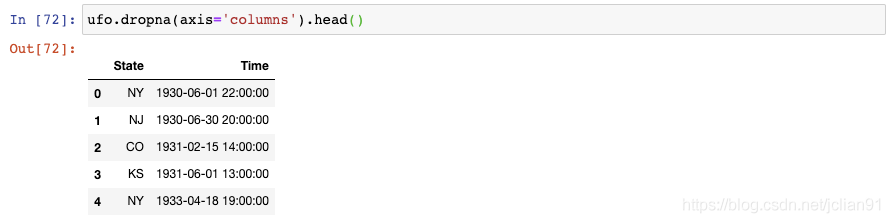
或者你想要舍弃那么缺失值占比超过10%的列,你可以给dropna()设置一个阈值:
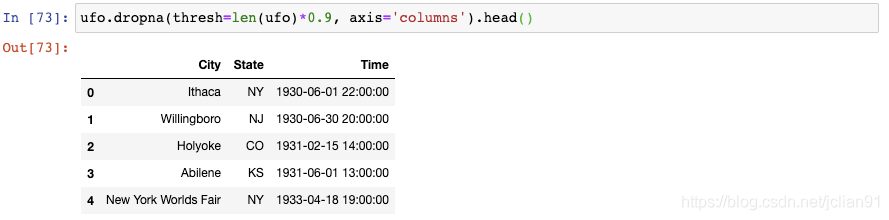
len(ufo)返回总行数,我们将它乘以0.9,以告诉pandas保留那些至少90%的值不是缺失值的列。
16. 将一个字符串划分成多个列
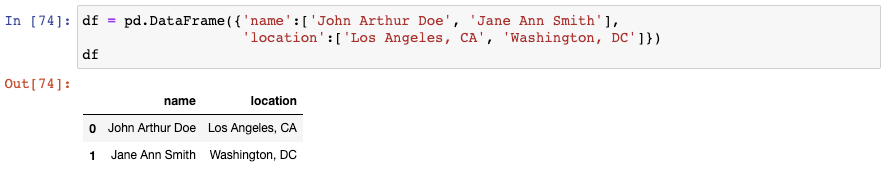
如果我们需要将“name”这一列划分为三个独立的列,用来表示first, middle, last name呢?我们将会使用str.split()函数,告诉它以空格进行分隔,并将结果扩展成一个DataFrame:

这三列实际上可以通过一行代码保存至原来的DataFrame:

如果我们想要划分一个字符串,但是仅保留其中一个结果列呢?比如说,让我们以", "来划分location这一列:

如果我们只想保留第0列作为city name,我们仅需要选择那一列并保存至DataFrame:

17. 将一个由列表组成的Series扩展成DataFrame

这里有两列,第二列包含了Python中的由整数元素组成的列表。

通过使用concat()函数,我们可以将原来的DataFrame和新的DataFrame组合起来:

18. 对多个函数进行聚合
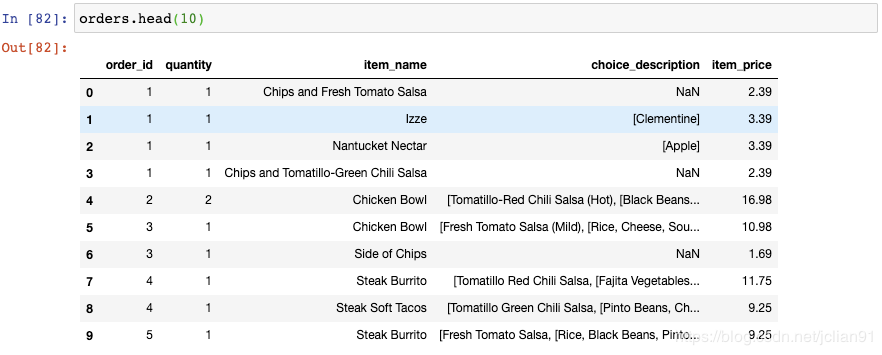
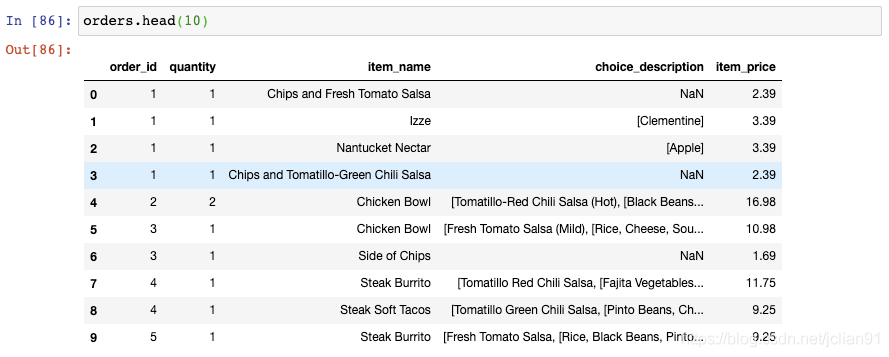
每个订单(order)都有订单号(order_id),包含一行或者多行。为了找出每个订单的总价格,你可以将那个订单号的价格(item_price)加起来。比如,这里是订单号为1的总价格:

如果你想要计算每个订单的总价格,你可以对order_id使用groupby(),再对每个group的item_price进行求和。

但是,事实上你不可能在聚合时仅使用一个函数,比如sum()。为了对多个函数进行聚合,你可以使用agg()函数,传给它一个函数列表,比如sum()和count():
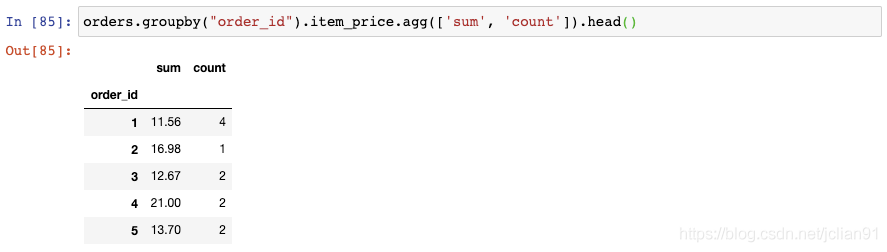
这将告诉我们没定订单的总价格和数量。
19. 将聚合结果与DataFrame进行组合
如果我们想要增加新的一列,用于展示每个订单的总价格呢?回忆一下,我们通过使用sum()函数得到了总价格:

sum()是一个聚合函数,这表明它返回输入数据的精简版本(reduced version )。

比这个函数的输入要小:

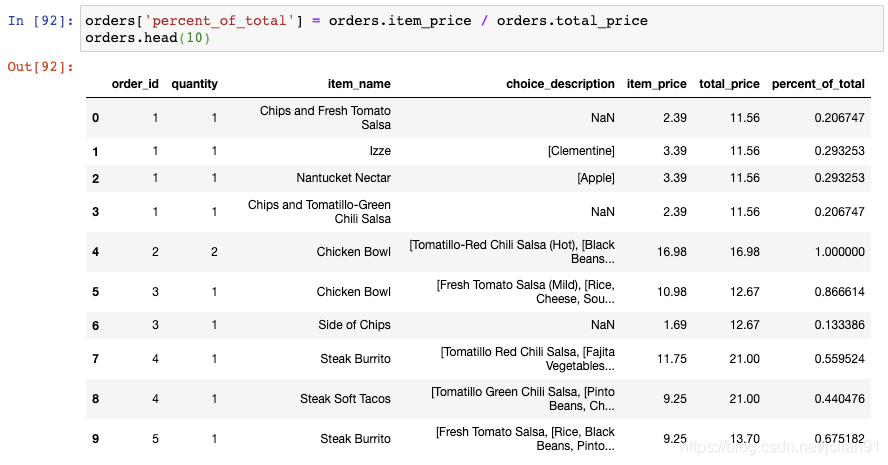
解决的办法是使用transform()函数,它会执行相同的操作但是返回与输入数据相同的形状:

我们将这个结果存储至DataFrame中新的一列:
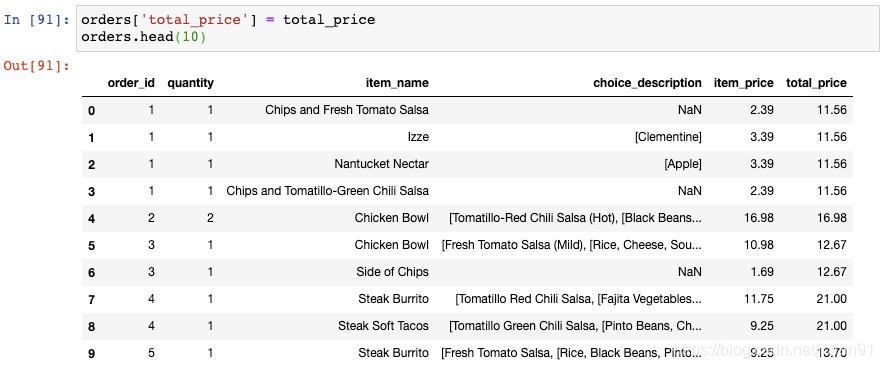
你可以看到,每个订单的总价格在每一行中显示出来了。
20. 选取行和列的切片
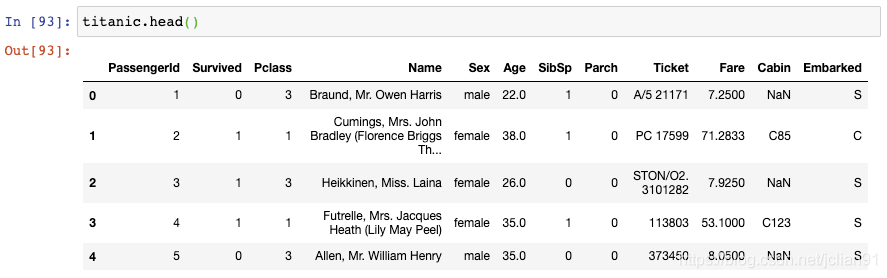
这就是著名的Titanic数据集,它保存了Titanic上乘客的信息以及他们是否存活。
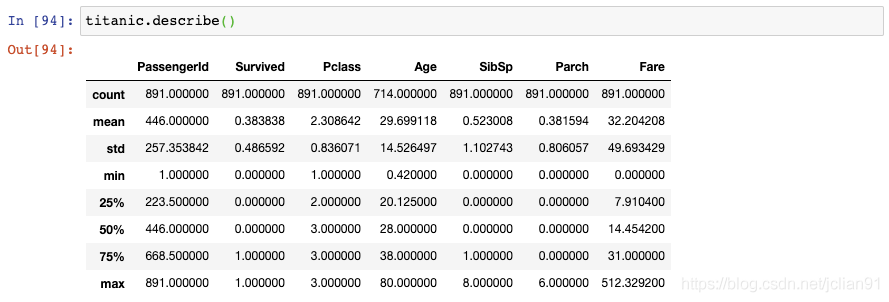
但是,这个DataFrame结果可能比你想要的信息显示得更多。
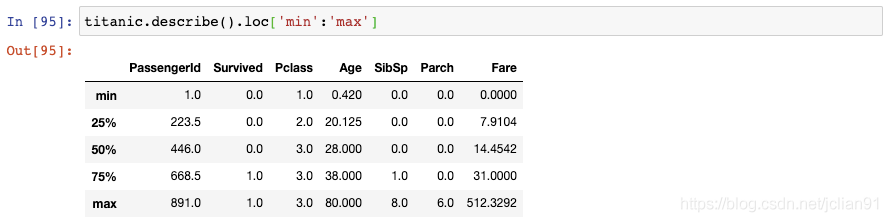
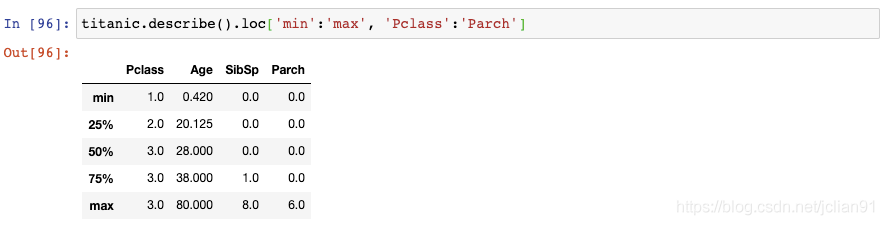
如果你不是对所有列都感兴趣,你也可以传递列名的切片:
21. 对MultiIndexed Series进行重塑

如果你想对某个类别,比如“Sex”,计算存活率,你可以使用groupby():

如果你想一次性对两个类别变量计算存活率,你可以对这些类别变量使用groupby():
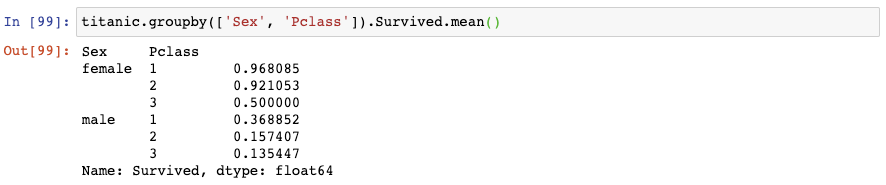
该结果展示了由Sex和Passenger Class联合起来的存活率。它存储为一个MultiIndexed Series,也就是说它对实际数据有多个索引层级。

该DataFrame包含了与MultiIndexed Series一样的数据,不同的是,现在你可以用熟悉的DataFrame的函数对它进行操作。
22. 创建数据透视表(pivot table)

想要使用数据透视表,你需要指定索引(index), 列名(columns), 值(values)和聚合函数(aggregation function)。
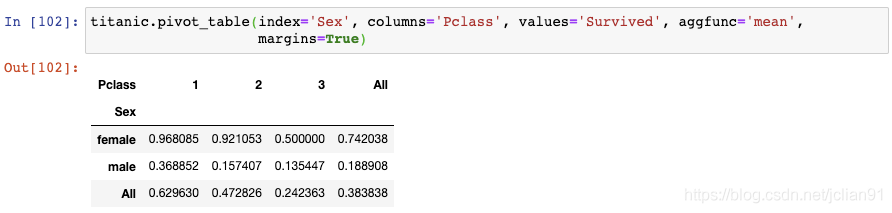
这个结果既显示了总的存活率,也显示了Sex和Passenger Class的存活率。
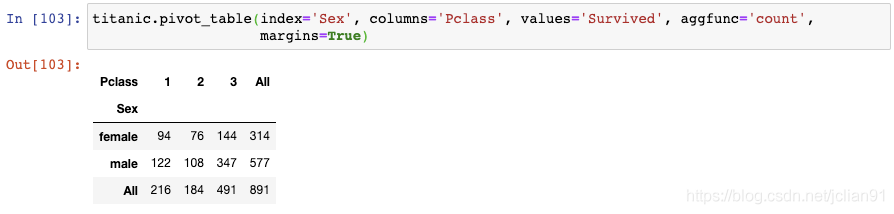
这个结果展示了每一对类别变量组合后的记录总数。
23. 将连续数据转变成类别数据
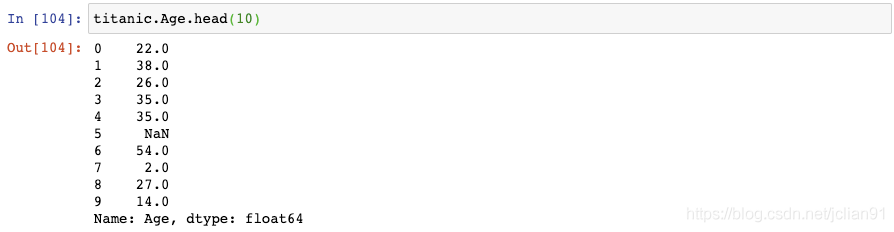
它现在是连续性数据,但是如果我们想要将它转变成类别数据呢?

这会对每个值打上标签。0到18岁的打上标签"child",18-25岁的打上标签"young adult",25到99岁的打上标签“adult”。
24. 更改显示选项
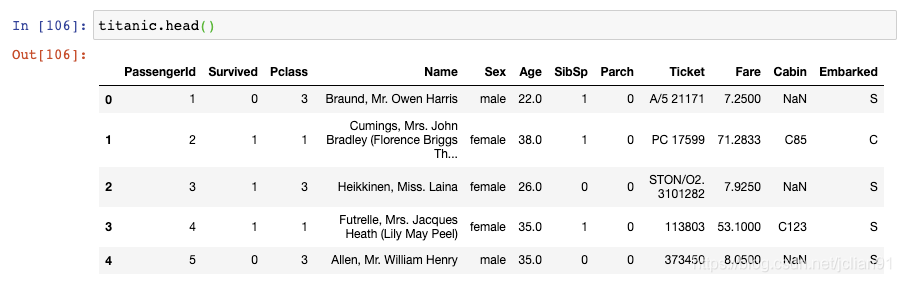
注意到,Age列保留到小数点后1位,Fare列保留到小数点后4位。如果你想要标准化,将显示结果保留到小数点后2位呢?
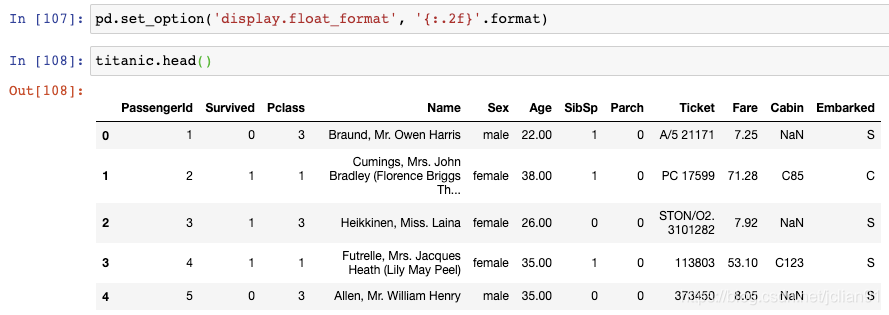
set_option()函数中第一个参数为选项的名称,第二个参数为Python格式化字符。可以看到,Age列和Fare列现在已经保留小数点后两位。注意,这并没有修改基础的数据类型,而只是修改了数据的显示结果。
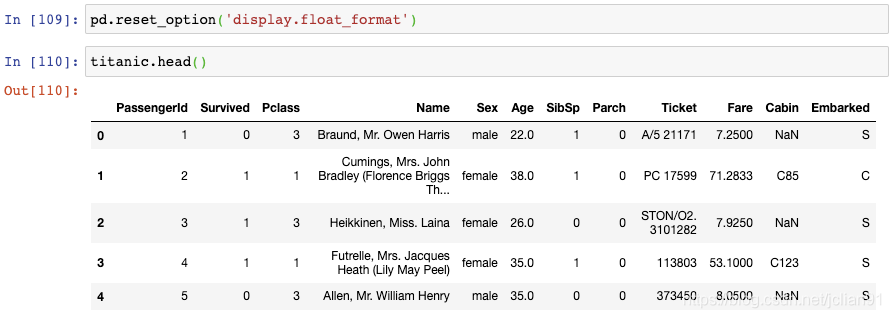
对于其它的选项也是类似的使用方法。
25. Style a DataFrame
我们可以创建一个格式化字符串的字典,用于对每一列进行格式化。然后将其传递给DataFrame的style.format()函数:
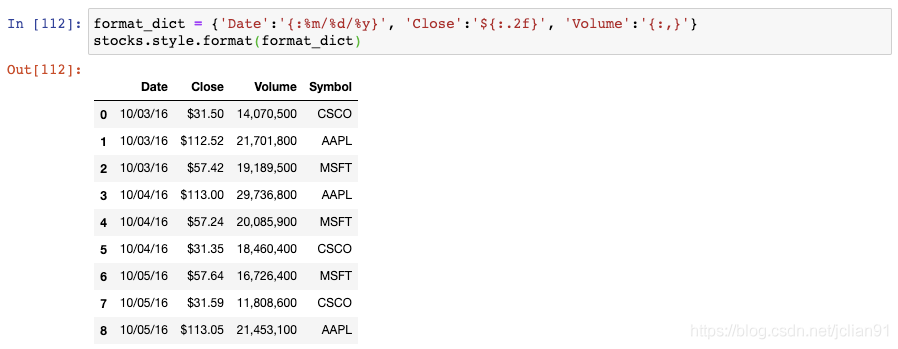
注意到,Date列是month-day-year的格式,Close列包含一个$符号,Volume列包含逗号。
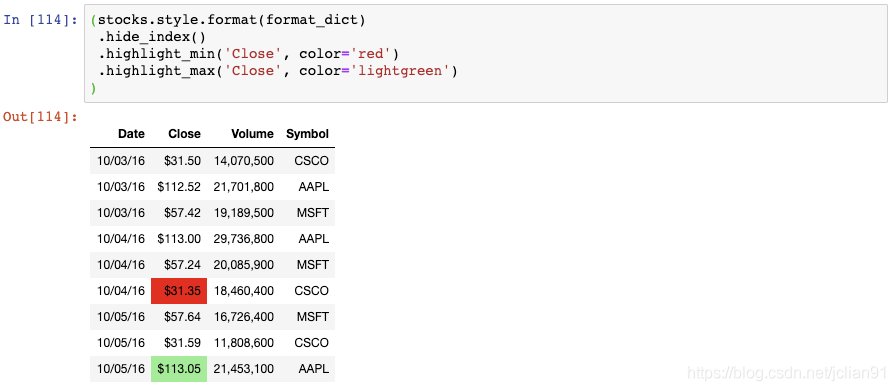
我们现在隐藏了索引,将Close列中的最小值高亮成红色,将Close列中的最大值高亮成浅绿色。
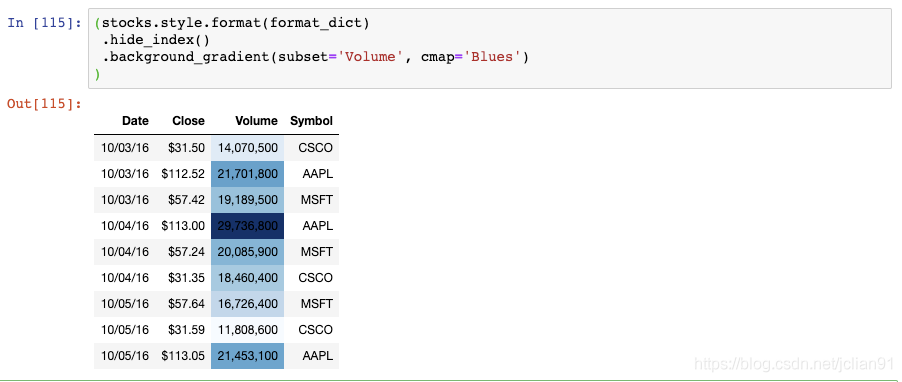
Volume列现在有一个渐变的背景色,你可以轻松地识别出大的和小的数值。
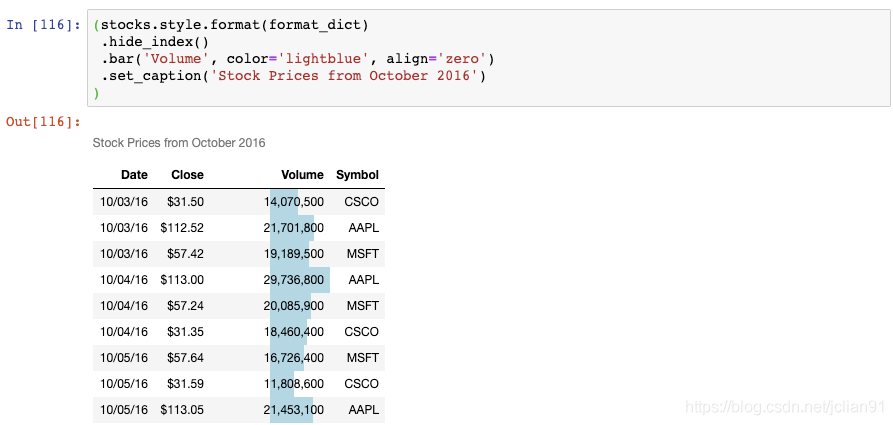
现在,Volumn列上有一个条形图,DataFrame上有一个标题。
零基础学 Python,请往看下嘛 送您价值 109 的视频课 只需7天时间,跨进Python编程大门,已有3800+加入 【基础】0基础入门python,24小时有人快速解答问题;
【提高】40多个项目实战,老手可以从真实场景中学习python;
【直播】不定期直播项目案例讲解,手把手教你如何分析项目;
【分享】优质python学习资料分享,让你在最短时间获得有价值的学习资源;圈友优质资料或学习分享,会不时给予赞赏支持,希望每个优质圈友既能赚回加入费用,也能快速成长,并享受分享与帮助他人的乐趣。
【人脉】收获一群志同道合的朋友,并且都是python从业者
【价格】本着布道思想,只需 69元 加入一个能保证学习效果的良心圈子。【赠予】价值109元 0基础入门在线课程,免费送给圈友们,供巩固 如果看到这里,说明你喜欢这篇文章,请转发、点赞。 老铁,三连支持一下,好吗?↓↓↓
评论