
亚马逊最新Arm服务器芯片详解
2022 年 5 月下旬,AWS 向公众发布了 Graviton 3。Graviton 3 是第一个将 SVE 指令集引入可广泛访问的服务器 CPU 的 ARM CPU。
下载链接:
在 Graviton 3 全面上市之前,Neoverse N1 主导了 ARM 服务器领域。AWS 之前的旗舰产品 Graviton 2 在 2.5 GHz 下实现了 64 个 Neoverse N1 内核。微软的 Azure 和甲骨文的 OCI 都使用 Ampere Altra,它将 80 个 Neoverse N1 内核放在网格上,并以 3 GHz 的频率为它们提供时钟。因此,我们将在 Graviton 3 和 Neoverse N1 之间进行比较。我们将用 AMD 的 Zen 3 和英特尔的 Ice Lake SP (Sunny Cove) 的数据来补充这一点。截至 2022 年中期,这些是云环境中使用的最新广泛部署的 x86 芯片,因此将成为 Graviton 3 最直接的竞争对手。
TheNextPlatform提出了一个令人信服的论点,即 Graviton 3 基于修改后的 Neoverse V1 核心。
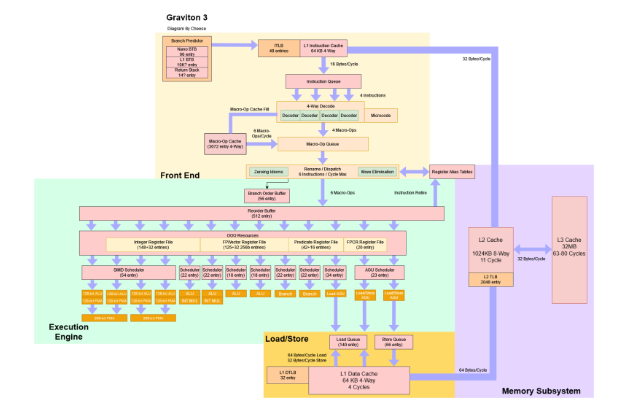
分支预测:向前迈出的一大步
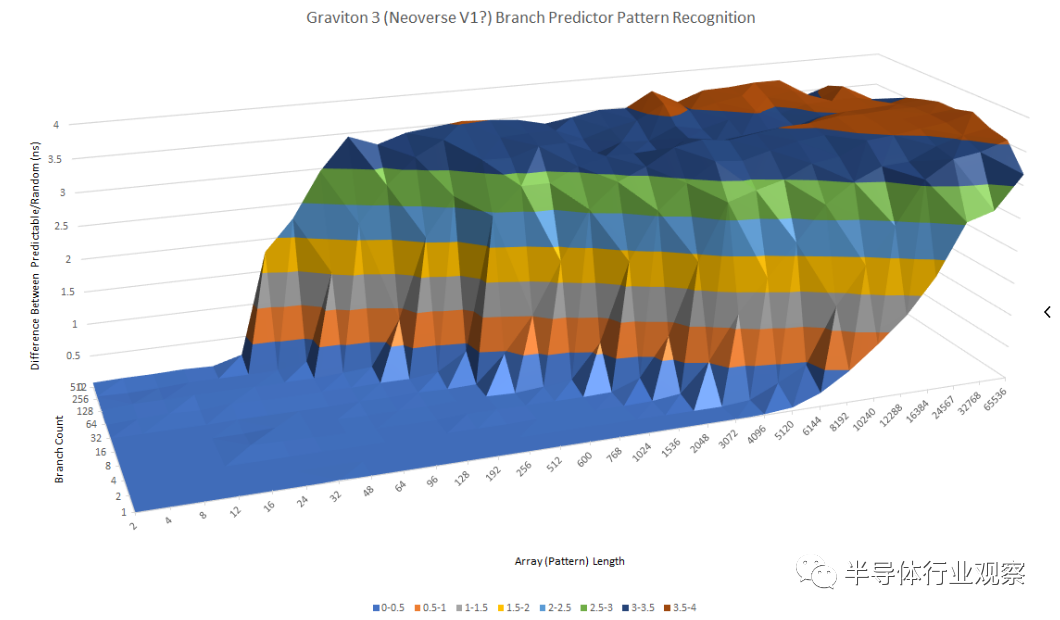
与 N1 相比,ARM 显著改进了分支预测器,并在速度和准确性方面取得了长足的进步。快速浏览一下 Graviton 3 的模式识别功能,可以清楚地看出它与 N1 完全不同。
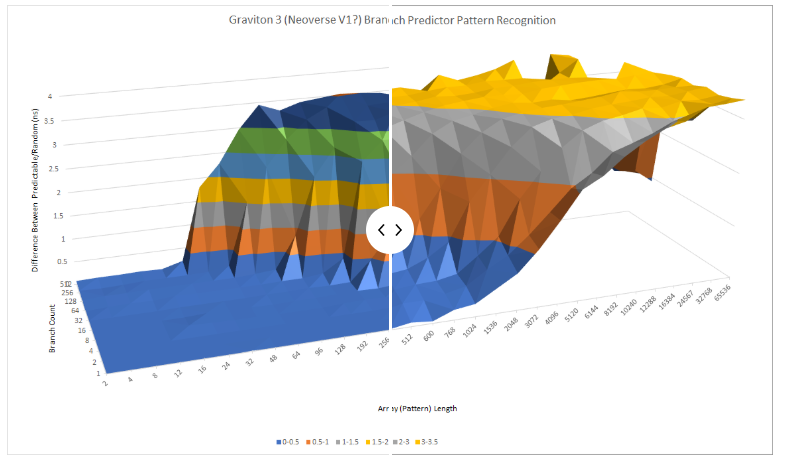
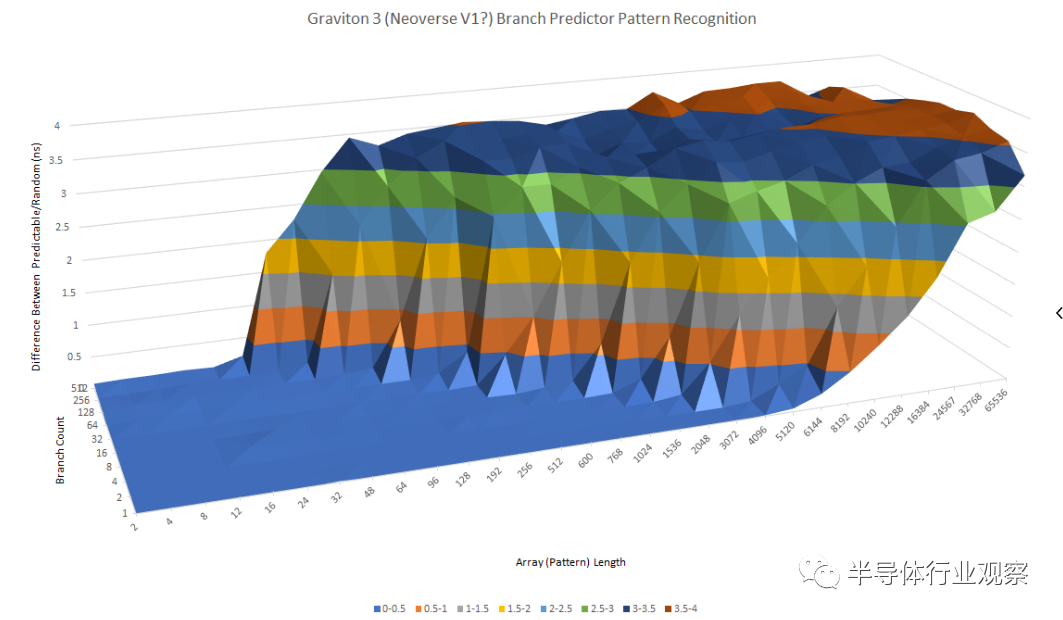
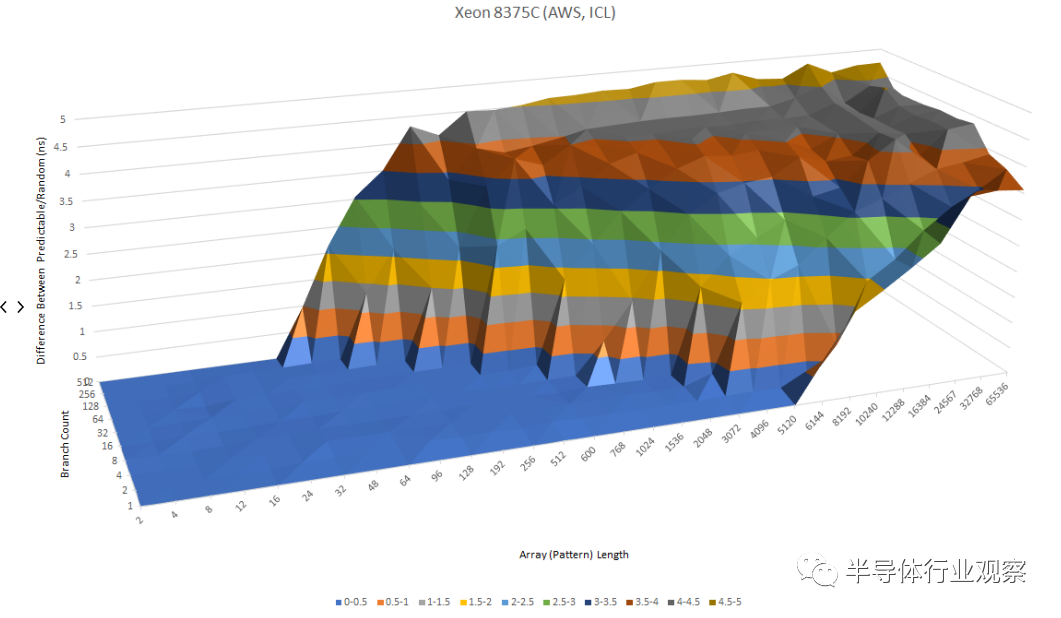
在云市场,Graviton 3 的主要 x86 竞争对手将是英特尔的 Ice Lake SP 和 AMD 的 Zen 3 Milan。Zen 3 似乎使用了一个具有令人难以置信的能力但略慢的二级预测器,而 Ice Lake 采用与 Graviton 3 非常相似的方法。英特尔和 ARM 似乎都使用可以识别很长模式的单级预测器,尽管不是与 AMD 的程度相同。

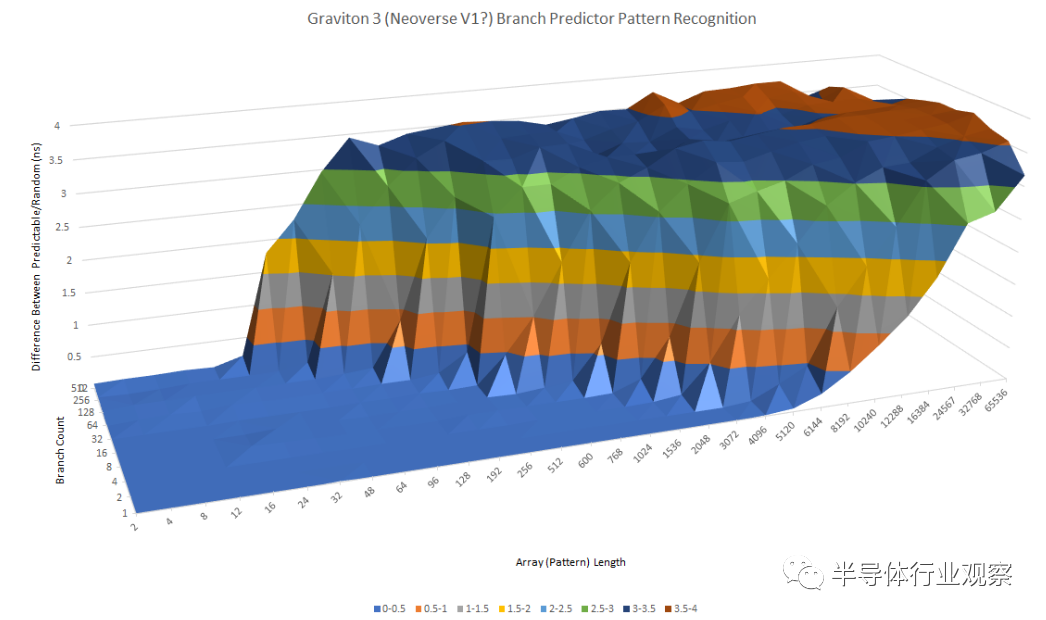
当有很多分支在起作用时,Ice Lake 比 Graviton 3 有一点优势。
Graviton 3 可以识别长达 16 长(long)的模式和 512 个分支,而 Ice Lake 可以在相同的分支数下处理两倍长的模式。同样,AMD 似乎拥有大量的分支历史存储,因为它能够处理多达 96 个模式和 512 个分支。
Graviton 3 还具有令人印象深刻的快速 BTB(分支目标缓冲区)设置,使其能够以非常小的代价处理已提取的分支。微型 BTB 允许核心在每个周期处理两个采用的分支,这是迄今为止我们仅在 Golden Cove 和 Rocket Lake 上看到的功能。但是 Graviton 3 的 micro-BTB 容量比那些 Intel CPU 上的容量要大。Golden Cove 只能跟踪 32 个分支,每个周期处理两个分支,而 Rocket Lake 可以处理八个。

ARM 还为 Graviton 3 配备了一个可能有 4K 条目的非常大的主 BTB,以及一个可能有多达 10K 条目的 L2 BTB。主 BTB 提供超过 Zen 3 的零冒泡分支能力。即使达到 L2 BTB 也不是很昂贵,每个分支只有一两个pipeline 气泡,有 10K 分支在运行。到目前为止,我们只看到 Golden Cove 实施了更大的 BTB。
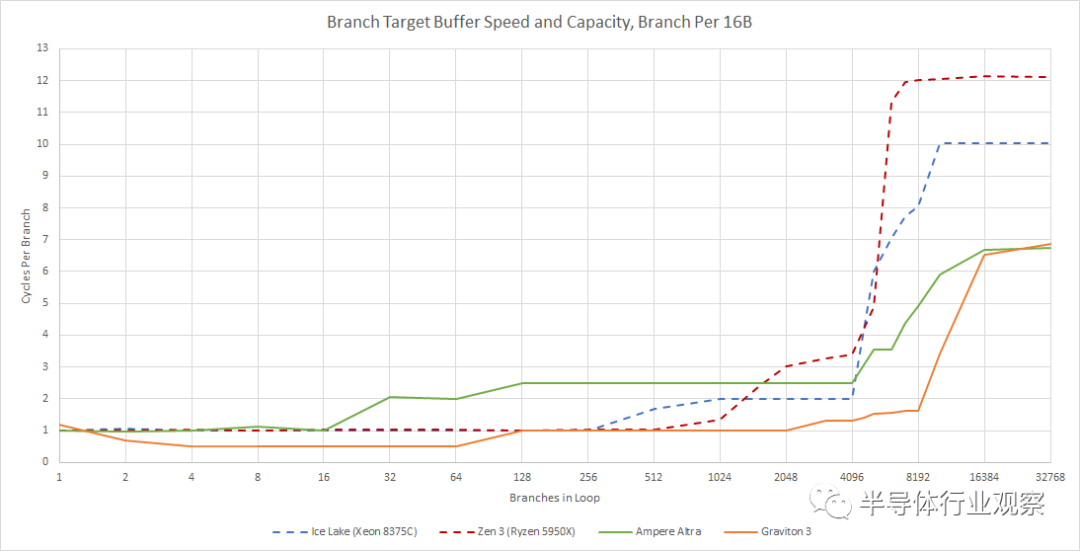
总而言之,Graviton 3 的分支预测器可与 Intel 和 AMD 的最佳预测器相媲美。每个 CPU 制造商做出不同的权衡,每个分支预测器都有其独特的优势,但 Graviton 3 的预测器显示了 ARM 与最好竞争对手竞争的决心。这与 Neoverse N1 中的平庸实现相去甚远,并且对于充分利用 Graviton 3 增加的重新排序能力应该有很长的路要走。
前端:熟悉的模式,有技巧
Graviton 2 和 3 都具有四宽解码器,但差异到此为止。在解码器后面,ARM 实现了一个具有 3K 条目的大型微操作缓存。因此,Graviton 3 的前端与 Intel 和 AMD 的前端非常相似。
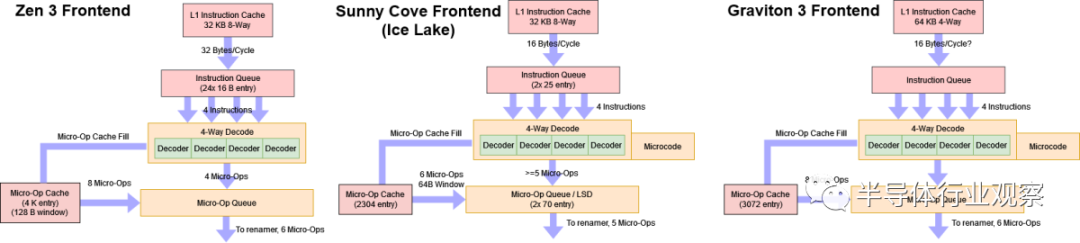
与 Neoverse N1 相比,Graviton 3 的解码器功能要强大得多。它们能够融合各种指令对。这包括 x86 风格的跳转融合,其中标志设置指令和相邻的条件跳转可以融合到单个微操作中。Graviton 3 还实现了 CNS 式的 NOP 融合。成对的 NOP 可以融合到前端的单个微操作中。因为 Graviton 3 具有能够缓存融合微操作的微操作缓存,所以每个周期将执行 12 个 NOP。
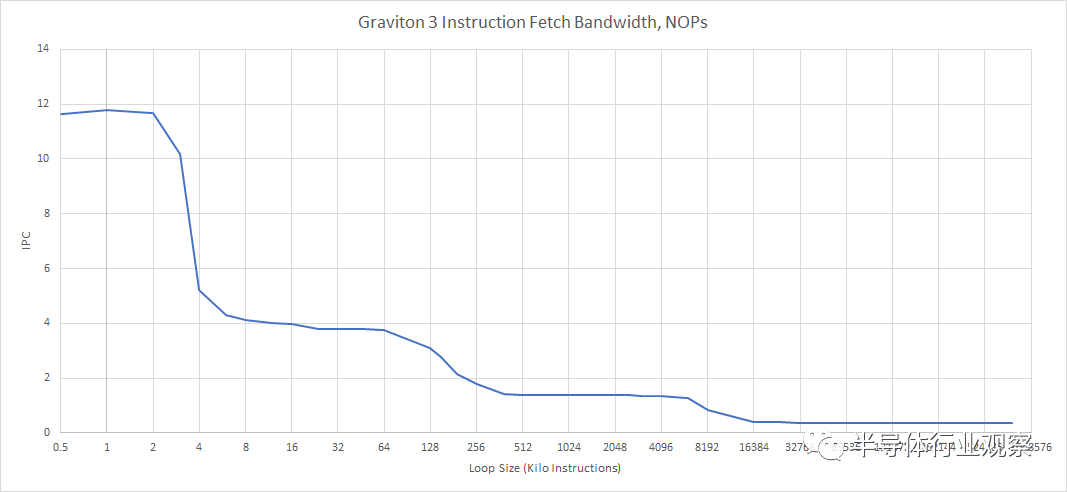 Graviton 3 的 NOP 融合突破了基本的指令获取带宽测试,微操作缓存的结果很有趣但不切实际。
Graviton 3 的 NOP 融合突破了基本的指令获取带宽测试,微操作缓存的结果很有趣但不切实际。
为了解决这个问题,我们用简单地将寄存器设置为零的指令填充了测试数组。这些不能以与 NOP 相同的方式融合,但可以以每个周期 6 次通过重命名器并在那里被消除。
在取指令带宽方面,Graviton 3 表现出与 Zen 3 相似的特点。两者都有超大的 micro-op 缓存,都可以支持 6 个 IPC。除了 L2 之外,Zen 3 具有很大的优势,因为 AMD 的架构优先考虑 L3 性能,而不是试图在芯片上创建单个统一缓存。与云场景中的前身 Neoverse N1 相比,Graviton 3 凭借其微操作缓存享有更高的指令带宽。从 L1D 获取带宽似乎是相等的,因为两种架构(实际上是这个比较中的所有架构)都使用 4 宽解码器。但在缓存层次结构的更下方,Graviton 3 享有更好的指令带宽。
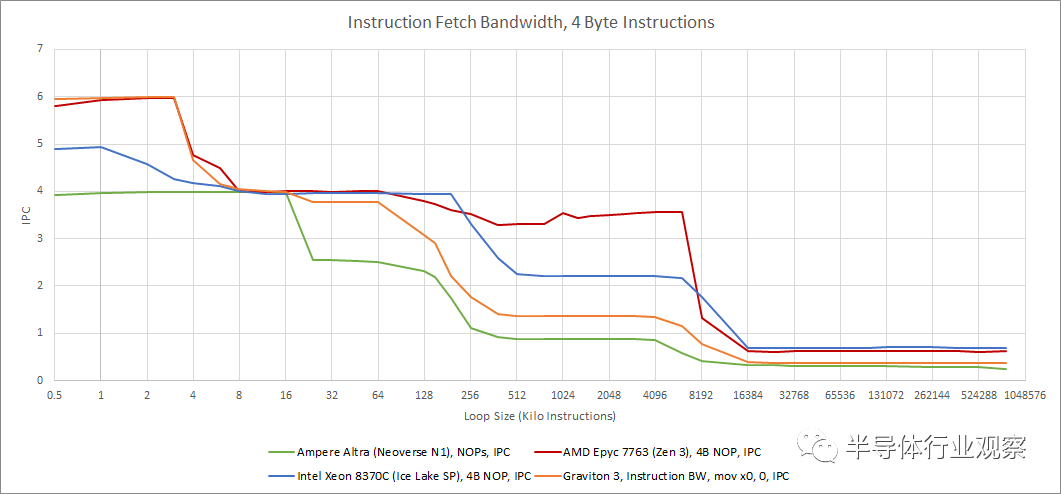
ARM 可能给 Graviton 3 提供了更深的获取队列,让内核使用其大型 BTB 来积极地预取指令。Graviton 3 出色的 L3 实现对此进行了补充,与 Ampere Altra 和 Graviton 2 相比,它提供了更低的延迟。非常大的指令占用空间的获取带宽仍然无法与 Intel 的 Ice Lake SP 或 AMD 的 Milan 相比,但 ARM 肯定在进步。
我们还看到各种消息来源表明 ,Neoverse V1 有一个 5 宽的指令解码器。如果 Graviton 3 基于 V1,解码器似乎已被缩减为 4 宽。一旦我们离开 3K 条目微操作缓存,即使测试循环适合 64 KB L1 指令缓存,我们每个周期也不会看到超过 4 条指令。当从微操作缓存运行时,相同的测试指令可以超过每周期 4 个吞吐量,这表明获取和解码带宽吞吐量限制,而不是进一步的流水线瓶颈。
Graviton 3 的Renamer:新兴能力
Graviton 3 的renamer似乎是 6 宽,让核心在整体宽度上与 Zen 3 相匹配。在renamer优化方面,Graviton 3 对 Neoverse N1 进行了改进。但是作为 CPU 制造商很难,因为你的竞争对手也总是在进步。AMD 在 Zen 中引入了极其强大的移动消除功能,而英特尔在 Sunny Cove 中也做了同样的事情。这两个 x86 CPU 都可以以匹配重命名器宽度的速率消除寄存器到寄存器移动指令。

Graviton 3 无法做到这一点。MOV 显然没有被淘汰,因为吞吐量似乎受到 ALU 端口数的限制。与 Neoverse N1 一样,Graviton 3 有时可以打破寄存器到寄存器 MOV 之间的依赖关系,但在该领域的功能非常有限。
rename阶段还可以打破依赖关系和/或消除将寄存器设置为零的指令,而不管其先前的值如何。据我们所知,只有将零移动到寄存器指令完全消除,并实现了等于renamer宽度的吞吐量。Graviton 3 在这方面比 Ice Lake 有优势,因为英特尔的renamer可以在检测到归零惯用语时打破依赖关系,但不能消除它们。
Zen 3 具有同等的能力——它可以识别常见的 x86 归零惯用语并消除它们。
乱序结构尺寸
我们仍在忙于拆解 AWS 的新云 CPU。在这个预览中,我们将展示一些原始测试结果和合理的解释,因为结果并不总是直截了当的。
让我们从重新排序缓冲区大小开始。这个结构的大小对应于 CPU 的执行引擎可以跟踪多少微操作。通常我们会用 NOP 进行测试,但 Graviton 3 的 NOP 融合能力使结果解释变得复杂。对 NOP 的测试表明,Graviton 3 的 ROB 有 512 个条目。但是 ROB 的实际容量可能是 256 个条目,如果每个条目都存储一个代表两个 NOP 的融合微操作。
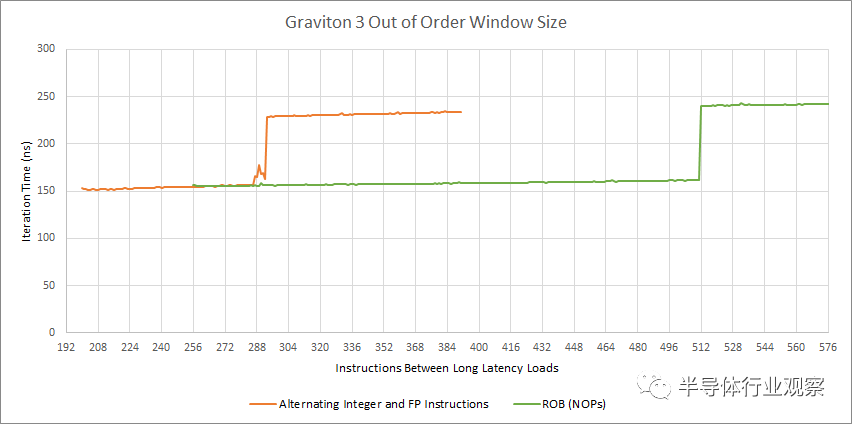
因此,我们运行了一个在整数和 FP 指令之间交替进行的额外测试。该测试的重排序容量超过 256 个条目,这表明 Graviton 3 确实有 512 个 ROB 条目,并且融合的 NOP 在通过renamer后未融合。如果这个解释是正确的,ARM 已经给 Graviton 3 一个比 Zen 3 和 Ice Lake 更大的乱序窗口。
当我们继续逆向工程寄存器文件大小时,另一个情况出现了。Graviton 3 似乎有 125 个 256 位宽的向量寄存器,但可以使用单个向量寄存器来跟踪两个标量 FP 寄存器。奇怪的是,它似乎无法使用单个 256 位 SVE 寄存器来跟踪两个 128 位 NEON 寄存器。
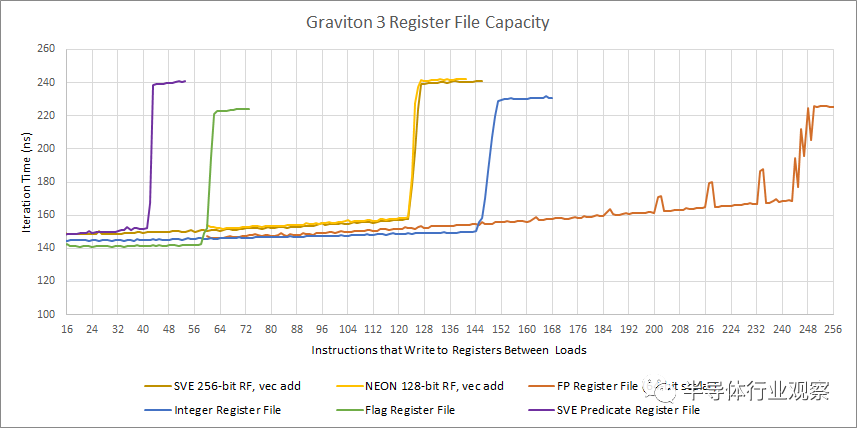
另一个奇怪的现象是,如果我们排除内核对标量浮点寄存器的巨大renaming能力,Graviton 3 的寄存器文件的大小更适合 256 条目的 ROB。
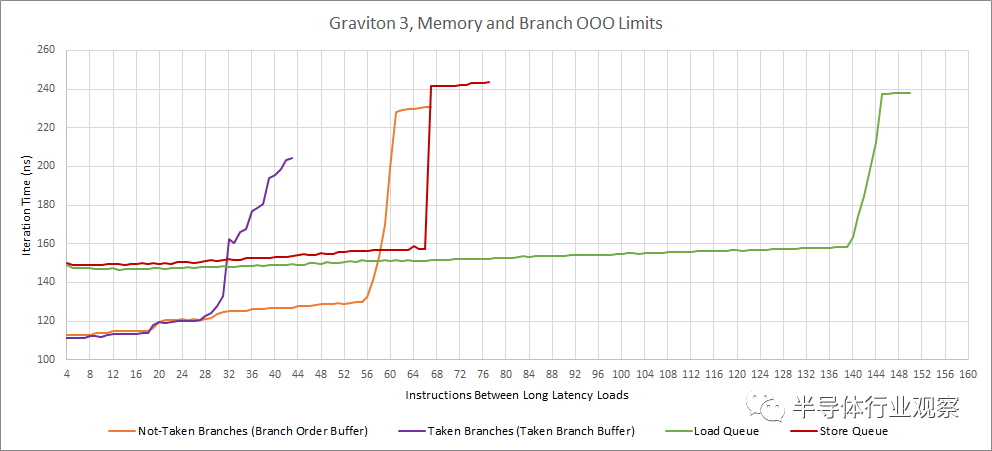
Graviton 3 的加载队列容量也很突出。其他结构尺寸仍然适中,大致与我们在 Zen 2 和 Zen 3 上看到的一致。
调度程序布局
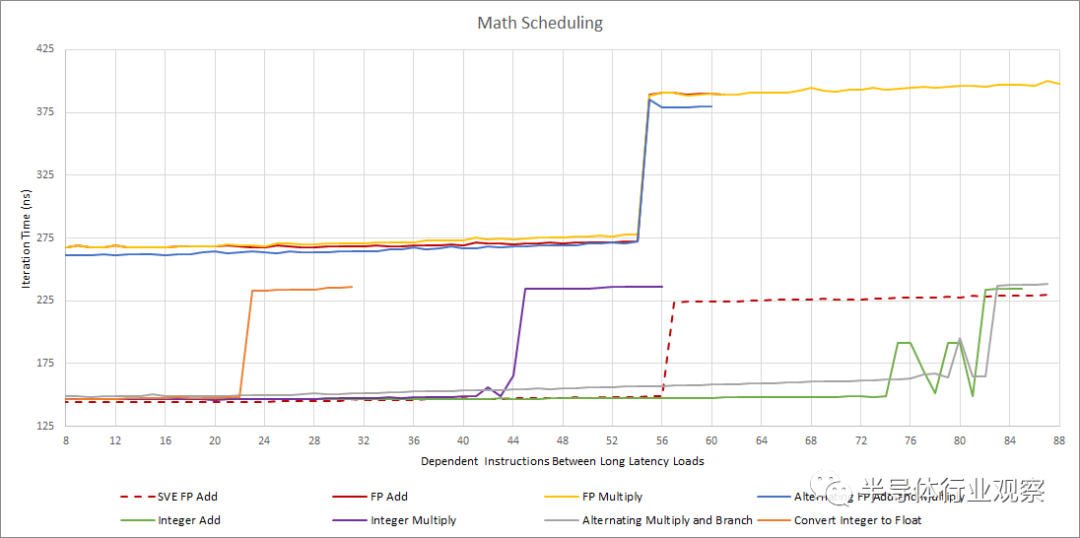 试图弄清楚调度程序的大小需要太多的测试
试图弄清楚调度程序的大小需要太多的测试
对分布式调度程序布局进行逆向工程非常困难、耗时且容易出错。这就是为什么这是一个预览而不是一个适当的深入研究。我们不会测试大量指令类型和组合以得出一个最合理的调度程序布局,而是提供一些指令类型的近似测量调度程序容量。

Graviton 3 有很多调度程序条目可供常见操作使用。虽然我们仍然不确定调度程序的确切布局,但很明显,Graviton 3 比 Neoverse N1 有了很大的飞跃。乍一看,它似乎与 Zen 3 和 Ice Lake 大致相当,至少在可用于常见操作的调度程序条目方面。
这是 Graviton 3 调度程序的一种合理布局:

执行单位
Graviton 3 的执行单元相当强大,符合我们对高性能内核的期望。与 Neoverse N1 的三个相比,有四个整数 ALU,三个内存pipeline( Neoverse N1 只有两个)。Graviton 3 的浮点和向量执行端得到了最大的升级,感觉就像是 Neoverse N1 的向量/FP 执行资源加了一个大的统一调度器的两倍。256 位 SVE 浮点加法和乘法每个时钟最多可以执行两次,从而使 Graviton 3 的浮点吞吐量与支持 AVX 的 x86 内核相当。
Graviton 3 还继承了 Neoverse N1 的向量和浮点执行延迟,只是略微降低了整数乘法延迟。
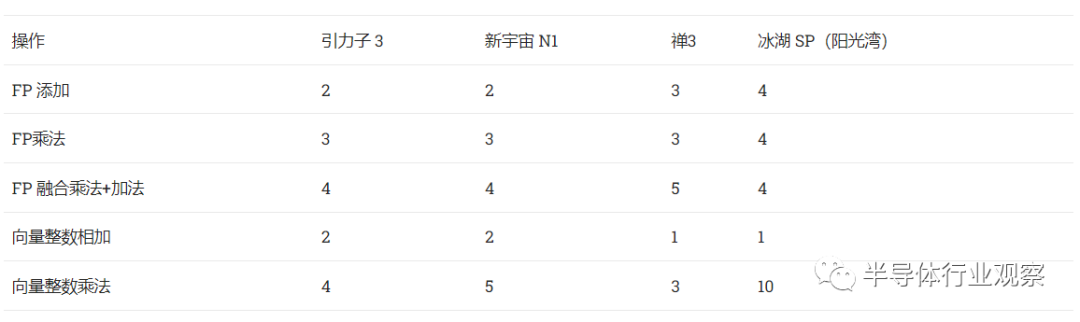
循环中某些操作的延迟。无论向量宽度如何,延迟似乎都是相同的,尽管我们尚未测试 SVE FMA 案例
两个周期浮点加法延迟非常可观,与英特尔的 Golden Cove 相匹配。当然,这对于 ARM 来说要容易得多,因为 Graviton 3 运行在非常低的时钟上。FP 乘法延迟与其他服务器 CPU 的延迟大致相当,并没有什么特别突出的。向量整数执行延迟也很好,如果比 Zen 3 高一点,并且可能高于 Graviton 3 的低时钟速度。
就执行吞吐量而言,Graviton 3 可能有 4 个 128 位向量/FP pipeline ,因为它能够为我们测试的所有操作(FP 加法、FP 乘法、整数加法)在每个周期执行一条以上的 SVE 指令。从理论上讲,这将使 Graviton 3 为 NEON 和标量 FP 操作实现令人印象深刻的吞吐量,但对于 NEON FP 加法/乘法和整数加法,我们无法超过每周期三条指令的吞吐量。这可以通过寄存器文件带宽限制来解释,即每个周期所需的输入。

高速缓存和内存访问
潜伏
Graviton 3 保留了 4 个循环,64 KB L1D。但是,ARM 改进了整个缓存层次结构的延迟。L2 容量保持不变,而延迟下降了两个周期。L3 延迟在 Ampere Altra 上非常糟糕,谢天谢地,Graviton 3 的延迟要好得多。
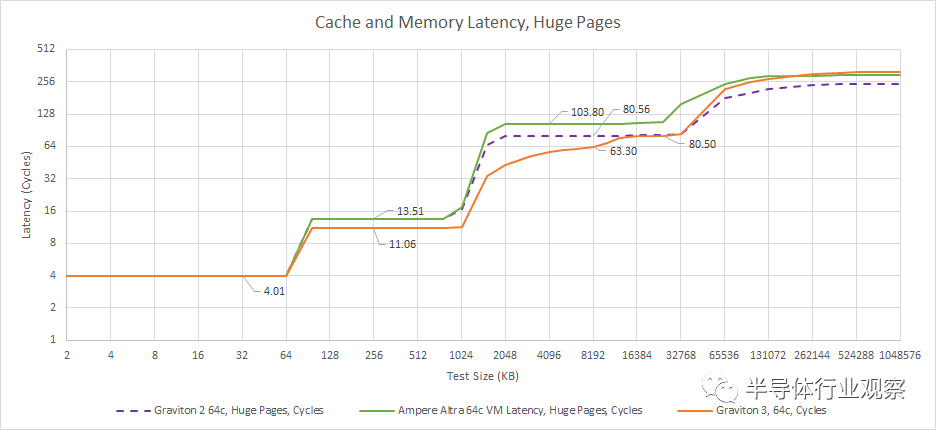
Graviton 2 和 Ampere Altra 使用相同的内核和相同的 L2 实现。这两种设计主要在 L3 中有所不同,其中 Graviton 2 实现的延迟稍小一些,这可能要归功于更小的网格。如果我们实时绘制延迟,Graviton 3 降低的周期计数在某种程度上被 Ampere Altra 的更高时钟抵消了。
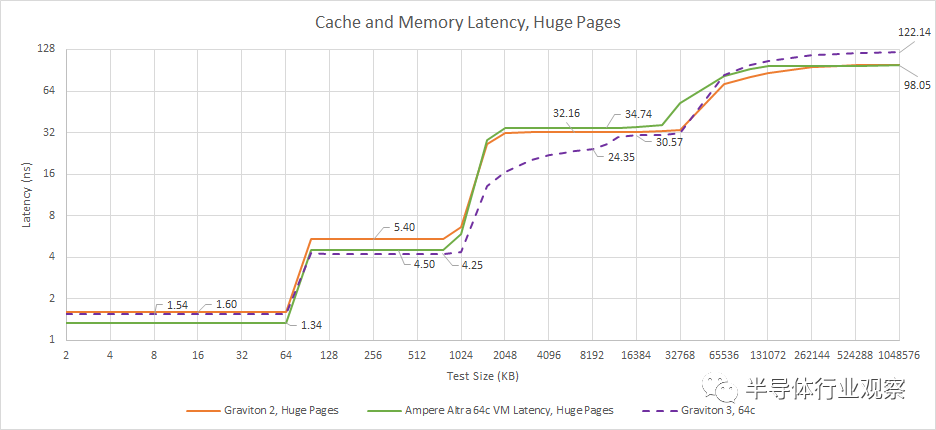
在内存方面,与 Ampere Altra 和 Graviton 2 相比,Graviton 3 的延迟明显下降。这可能是由于 DDR5 的延迟特性比 DDR4 更差。Graviton 3 还将内存控制器放置在单独的 IO 小芯片上。这可能会加剧 DDR5 的延迟问题。
Ice Lake 和 Graviton 3 采用大致并行的缓存策略。两者都实现了芯片范围内的统一 L3。并且两者都为它们的内核提供了大型私有 L2 缓存,以使它们免受 L3 延迟的影响。AMD 采取了不同的方法,放弃了芯片级缓存,转而为每个核心集群提供非常快的 L3。

x86 竞争对手也使用多用途架构。Sunny Cove(在 Ice Lake 中使用)和 Zen 3 在客户端平台中提供双重任务,它们可以达到远远超过 4 GHz 的时钟速度,以最大限度地提高线程受限的性能。这种设计特征也出现在云中,Milan的 Epyc 和 Ice Lake Xeons 的时钟明显高于 Graviton 3。因此,在查看实际时间而不是时钟周期时,我们看到了巨大的差异。
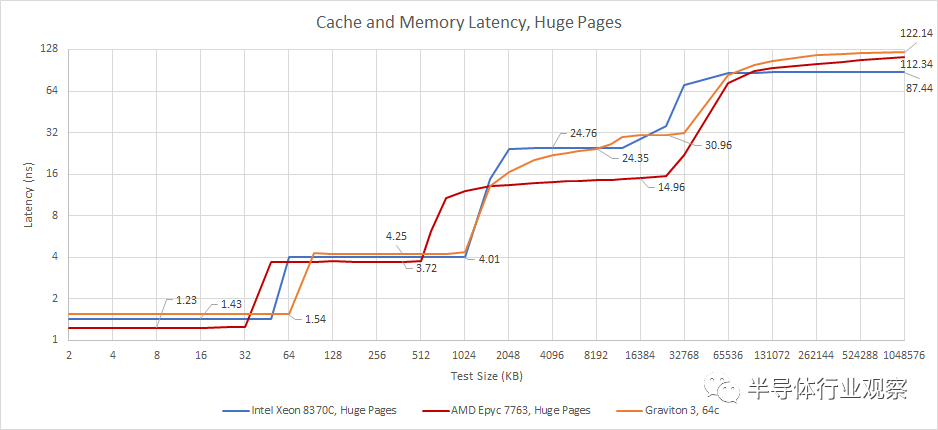 Xeon 运行在 3.5 GHz,而 Epyc 运行在 3.23 GHz,基于寄存器到寄存器的附加延迟
Xeon 运行在 3.5 GHz,而 Epyc 运行在 3.23 GHz,基于寄存器到寄存器的附加延迟
Zen 3 和 Ice Lake 都有更小、更快的 L1 缓存。在 L2,模式重复。Ice Lake 较高的周期计数延迟完全被其较高的时钟所逆转,使其超越了 Graviton 3。英特尔和 ARM 的基于网格的 L3 大致相当,具体取决于您在延迟图中查看的位置。同样,AMD 选择了速度非常快的非统一 L3。
当我们查看更大的测试规模时,DDR5 的延迟回归再次出现。英特尔在单片芯片上使用 DDR4 控制器,为服务器芯片实现了极低的内存延迟。AMD 的 Epyc 使用小芯片,因此是与 Graviton 3 的一个非常有趣的比较。尽管两者都会产生跨小芯片的损失,但 AMD 的内存访问延迟比 Graviton 3 低大约 10 ns。我将这种差异归结为 DDR5。
带宽
在核心数量匹配的情况下,Graviton 3 的缓存提供了合理的性能,与 Ampere Altra 相比,提供了全面的带宽改进。如果 SVE 发挥作用,Graviton 3 的 L1 和 L2 缓存带宽将比 Neoverse N1 高出不少。
 借助广泛支持的 NEON 指令,Ampere Altra 因其更高的时钟而保持接近,但如果使用 SVE,Graviton 3 可能会失控
借助广泛支持的 NEON 指令,Ampere Altra 因其更高的时钟而保持接近,但如果使用 SVE,Graviton 3 可能会失控
但与其 x86 竞争对手相比,它并没有那么令人印象深刻。由于高时钟和同样宽的矢量宽度,Zen 3 的缓存远远领先于 Graviton。Ice Lake 以更高的时钟频率和两倍的矢量宽度更进一步,使其具有无与伦比的每核 L1D 带宽。英特尔的服务器架构还具有到 L2 的宽 64 字节/周期路径。使用 256 位 SVE 加载指令可以稍微缩小差距,但无法绕过低时钟。
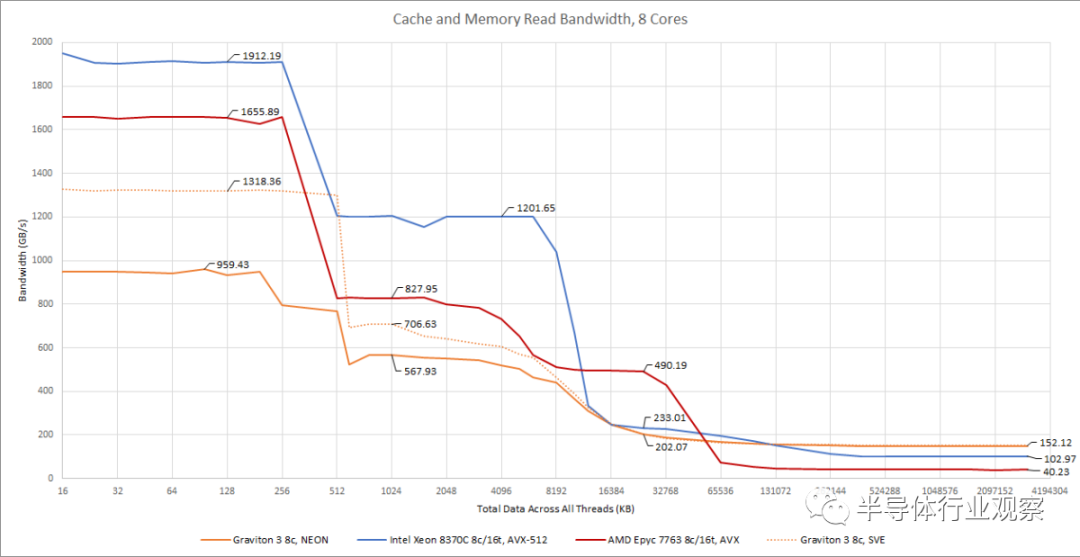
DDR5 在我们的内存延迟测试中表现不佳,但它的优势在带宽测试中确实体现出来了。Graviton 3 的内存带宽领先于其 x86 竞争对手。
我们没有太多关于整个服务器芯片的数据,主要是因为我们不是一个可以轻松获得服务器东西的大型技术网站。但这是与我们拥有的数据的比较:

正如预期的那样,Graviton 3 比 Neoverse N1 具有巨大的优势。与带有 V-Cache 的 Epyc 相比,它在 L1、L2 和内存带宽方面领先。然而,AMD 巨大、快速的 L3 仍然使其在某些测试规模上处于领先地位。
最初的想法
SVE 支持
Graviton 3 之所以引人注目,是因为它是第一个支持 SVE 的通用 64 位 ARM 服务器 CPU。富士通的 A64FX 最先出现,但那是专为超级计算机设计的芯片,而非通用用途。我们还在一些最近发布的高端手机上看到了 SVE2 支持,但在其他服务器芯片上却没有。
在不久的将来,这可能是一个有限的优势。几乎没有支持 SVE 的软件。GCC 将完全拒绝发出 SVE 指令(至少在我们有限的经验中),即使您使用汇编,所以我们使用 Clang 来汇编我们的测试代码。在接下来的几年里,吸收可能会很缓慢。SVE 的市场渗透率远不及 AVX(2),这让 SVE 的情况让人想起 2017 年 Skylake-X 面世时的 AVX-512。
所以 Graviton 3 将不得不等待几年才能判断 SVE 是否给它带来了显着的优势。但这也有问题。SVE2 已经推出,如果软件使用 SVE2 中不存在的指令,那么 Graviton 3 将被抛在后面。
对抗竞争
AWS 的 Graviton 3 使用比 Neoverse N1 更强大的核心架构。N1 是当前 ARM 服务器产品的中流砥柱,这意味着 Graviton 3 是云中性能最高、广泛可用的 ARM CPU。在接下来的几年里,它很可能会留在那个位置。
在 x86 的竞争中,Graviton 3 的单核性能可能比N1更接近 Zen 3 和 Ice Lake 。在分支预测、重新排序能力、执行资源和内核宽度方面,ARM 的 V1 微架构(假设这是 Graviton 3 的基础)与英特尔和 AMD 当前的服务器产品处于同一水平。但我不指望 Graviton 3 能与 AMD 和 Intel 匹敌。Graviton 3 与其 x86 竞争对手之间存在巨大的时钟速度差异,而且 V1 并不是更大更强大。
从亚马逊的角度来看
该设计似乎非常狭隘地针对最大化云中的计算密度。为此,AWS 选择了非常保守的核心时钟。在 2.6 GHz 时,Graviton 3 的时钟频率仅比其前身 Graviton 2 高 100 MHz,而没有增加每个芯片的核心数量。因此,Graviton 3 几乎所有的性能优势都来自每时钟性能的提升。
亚马逊因此选择使用台积电最先进的 5 纳米工艺来降低功耗。台积电的 7 nm 工艺已经为低功耗设计创造了奇迹,而 5 nm 将进一步发展。虽然 Graviton 3 的核心比 N1 更强大,但它远不如英特尔的 Golden Cove 雄心勃勃,仍应被视为中等设计。这样一个在 5 nm 上以 2.6 GHz 运行的内核绝对可以降低功耗。这反过来又让 AWS 将其中三个芯片打包到一个节点中,从而提高了计算密度。最终的结果是一种芯片可以让 AWS 以更低的价格销售每个 Graviton 3 内核,同时仍然比之前的 Graviton 2 芯片提供显着的性能提升。
来源:半导体行业观察
原文链接:
https://chipsandcheese.com/2022/05/29/graviton-3-first-impressions/
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕。
获取方式:点击“阅读原文”即可查看182页 PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
