
Spark 学习
小编推荐
来源:子雨大数据
http://dblab.xmu.edu.cn/blog
内容:运行原理,RDD设计,DAG,安装与使用
第1章 Spark的设计与运行原理(大概了解)
1.1 Spark简介 http://dblab.xmu.edu.cn/blog/1710-2/
(1)主要特点
运行速度快:Spark使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍;
容易使用:Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程;
通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算;
运行模式多样:Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
(2) Hadoop 的缺点
回顾Hadoop的工作流程,可以发现Hadoop存在如下一些缺点:
表达能力有限。计算都必须要转化成Map和Reduce两个操作,但这并不适合所有的情况,难以描述复杂的数据处理过程;
磁盘IO开销大。每次执行时都需要从磁盘读取数据,并且在计算完成后需要将中间结果写入到磁盘中,IO开销较大;
延迟高。一次计算可能需要分解成一系列按顺序执行的MapReduce任务,任务之间的衔接由于涉及到IO开销,会产生较高延迟。而且,在前一个任务执行完成之前,其他任务无法开始,难以胜任复杂、多阶段的计算任务。
(3)相比于 Hadoop 的优势
Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题。相比于MapReduce,Spark主要具有如下优点:
Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活;
Spark提供了内存计算,中间结果直接放到内存中,带来了更高的迭代运算效率;
Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
Spark最大的特点就是将计算数据、中间结果都存储在内存中,大大减少了IO开销,因而,Spark更适合于迭代运算比较多的数据挖掘与机器学习运算。使用Hadoop进行迭代计算非常耗资源,因为每次迭代都需要从磁盘中写入、读取中间数据,IO开销大。而Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据。
在实际进行开发时,使用Hadoop需要编写不少相对底层的代码,不够高效。相对而言,Spark提供了多种高层次、简洁的API,通常情况下,对于实现相同功能的应用程序,Spark的代码量要比Hadoop少2-5倍。更重要的是,Spark提供了实时交互式编程反馈,可以方便地验证、调整算法。
尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替Hadoop,主要用于替代Hadoop中的MapReduce计算模型。实际上,Spark已经很好地融入了Hadoop生态圈,并成为其中的重要一员,它可以借助于YARN实现资源调度管理,借助于HDFS实现分布式存储。此外,Hadoop可以使用廉价的、异构的机器来做分布式存储与计算,但是,Spark对硬件的要求稍高一些,对内存与CPU有一定的要求。
(4)Spark 生态系统
在实际应用中,大数据处理主要包括以下三个类型:
复杂的批量数据处理:时间跨度通常在数十分钟到数小时之间;
基于历史数据的交互式查询:时间跨度通常在数十秒到数分钟之间;
基于实时数据流的数据处理:时间跨度通常在数百毫秒到数秒之间。
目前已有很多相对成熟的开源软件用于处理以上三种情景,比如,可以利用Hadoop MapReduce来进行批量数据处理,可以用Impala来进行交互式查询(Impala与Hive相似,但底层引擎不同,提供了实时交互式SQL查询),对于流式数据处理可以采用开源流计算框架Storm。一些企业可能只会涉及其中部分应用场景,只需部署相应软件即可满足业务需求,但是,对于互联网公司而言,通常会同时存在以上三种场景,就需要同时部署三种不同的软件,这样做难免会带来一些问题:
不同场景之间输入输出数据无法做到无缝共享,通常需要进行数据格式的转换;
不同的软件需要不同的开发和维护团队,带来了较高的使用成本;
比较难以对同一个集群中的各个系统进行统一的资源协调和分配。
Spark的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成了一套完整的生态系统,既能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习和图计算等。Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案。因此,Spark所提供的生态系统足以应对上述三种场景,即同时支持批处理、交互式查询和流数据处理。
现在,Spark生态系统已经成为伯克利数据分析软件栈BDAS(Berkeley Data Analytics Stack)的重要组成部分。BDAS的架构如图所示,从中可以看出,Spark专注于数据的处理分析,而数据的存储还是要借助于Hadoop分布式文件系统HDFS、Amazon S3等来实现的。因此,Spark生态系统可以很好地实现与Hadoop生态系统的兼容,使得现有Hadoop应用程序可以非常容易地迁移到Spark系统中。
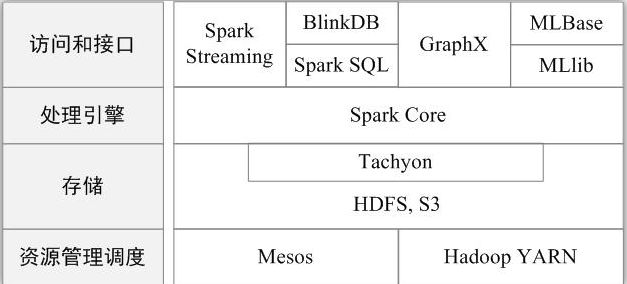
Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX 等组件,各个组件的具体功能如下:
* Spark Core:Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景;通常所说的Apache Spark,就是指Spark Core;
* Spark SQL:Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析;
* Spark Streaming:Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等;
* MLlib(机器学习):MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习的工作;
* GraphX(图计算):GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化,Graphx性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
1.2 Spark运行架构 http://dblab.xmu.edu.cn/blog/1711-2/
(1)基本概念
在具体讲解Spark运行架构之前,需要先了解几个重要的概念:
* RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型;
* DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系;
* Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据;
* 应用:用户编写的Spark应用程序;
* 任务:运行在Executor上的工作单元;
* 作业:一个作业包含多个RDD及作用于相应RDD上的各种操作;
* 阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”。
(2)架构设计
如图9-5所示,Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:一是利用多线程来执行具体的任务(Hadoop MapReduce采用的是进程模型),减少任务的启动开销;二是Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时,就可以直接读该存储模块里的数据,而不需要读写到HDFS等文件系统里,因而有效减少了IO开销;或者在交互式查询场景下,预先将表缓存到该存储系统上,从而可以提高读写IO性能。
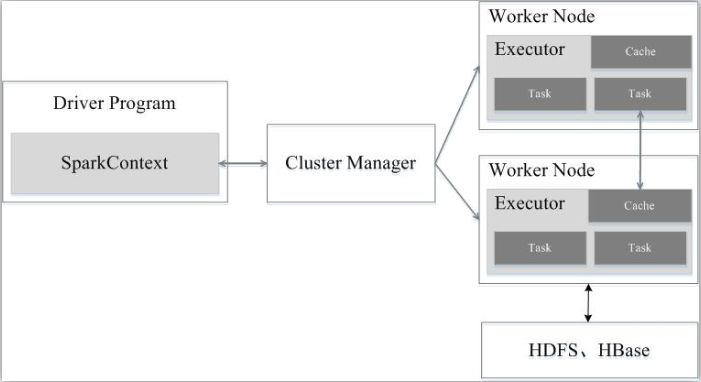
图9-5 Spark运行架构
总体而言,如图9-6所示,在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
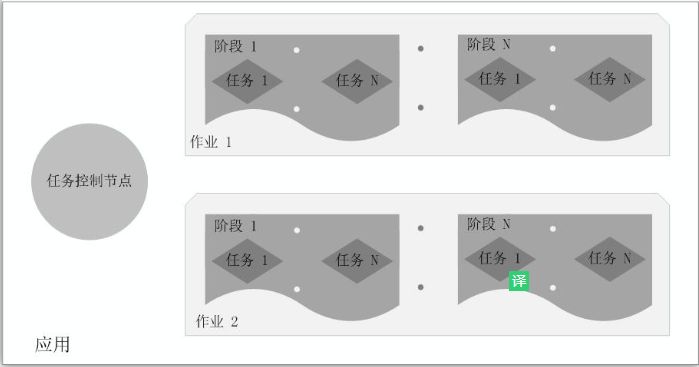
图9-6 Spark中各种概念之间的相互关系
(3)Spark 运行基本流程
如图9-7 所示,Spark的基本运行流程如下:
(1)当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源;
(2)资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上;
(3)SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度器(DAGScheduler)进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor;
(4)任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。

图9-7 Spark运行基本流程图
总体而言,Spark运行架构具有以下特点:
(1)每个应用都有自己专属的Executor进程,并且该进程在应用运行期间一直驻留。Executor进程以多线程的方式运行任务,减少了多进程任务频繁的启动开销,使得任务执行变得非常高效和可靠;
(2)Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可;
(3)Executor上有一个BlockManager存储模块,类似于键值存储系统(把内存和磁盘共同作为存储设备),在处理迭代计算任务时,不需要把中间结果写入到HDFS等文件系统,而是直接放在这个存储系统上,后续有需要时就可以直接读取;在交互式查询场景下,也可以把表提前缓存到这个存储系统上,提高读写IO性能;
(4)任务采用了数据本地性和推测执行等优化机制。数据本地性是尽量将计算移到数据所在的节点上进行,即“计算向数据靠拢”,因为移动计算比移动数据所占的网络资源要少得多。而且,Spark采用了延时调度机制,可以在更大的程度上实现执行过程优化。比如,拥有数据的节点当前正被其他的任务占用,那么,在这种情况下是否需要将数据移动到其他的空闲节点呢?答案是不一定。因为,如果经过预测发现当前节点结束当前任务的时间要比移动数据的时间还要少,那么,调度就会等待,直到当前节点可用。
1.3 RDD的设计与运行原理 http://dblab.xmu.edu.cn/blog/1681-2/
(1)RDD 设计背景
在实际应用中,存在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘工具,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。虽然,类似Pregel等图计算框架也是将结果保存在内存当中,但是,这些框架只能支持一些特定的计算模式,并没有提供一种通用的数据抽象。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销。
(2)RDD 概念
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。
RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用,比如Web应用系统、增量式的网页爬虫等。正因为这样,这种粗粒度转换接口设计,会使人直觉上认为RDD的功能很受限、不够强大。但是,实际上RDD已经被实践证明可以很好地应用于许多并行计算应用中,可以具备很多现有计算框架(比如MapReduce、SQL、Pregel等)的表达能力,并且可以应用于这些框架处理不了的交互式数据挖掘应用。
Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作。RDD典型的执行过程如下:
RDD读入外部数据源(或者内存中的集合)进行创建;
RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标量)。
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中(如图9-8所示),真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。

图9-8 Spark的转换和行动操作
例如,在图9-9中,从输入中逻辑上生成A和C两个RDD,经过一系列“转换”操作,逻辑上生成了F(也是一个RDD),之所以说是逻辑上,是因为这时候计算并没有发生,Spark只是记录了RDD之间的生成和依赖关系。当F要进行输出时,也就是当F进行“行动”操作的时候,Spark才会根据RDD的依赖关系生成DAG,并从起点开始真正的计算。
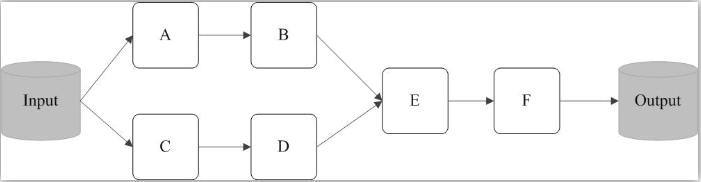
图9-9 RDD执行过程的一个实例
上述这一系列处理称为一个“血缘关系(Lineage)”,即DAG拓扑排序的结果。采用惰性调用,通过血缘关系连接起来的一系列RDD操作就可以实现管道化(pipeline),避免了多次转换操作之间数据同步的等待,而且不用担心有过多的中间数据,因为这些具有血缘关系的操作都管道化了,一个操作得到的结果不需要保存为中间数据,而是直接管道式地流入到下一个操作进行处理。同时,这种通过血缘关系把一系列操作进行管道化连接的设计方式,也使得管道中每次操作的计算变得相对简单,保证了每个操作在处理逻辑上的单一性;相反,在MapReduce的设计中,为了尽可能地减少MapReduce过程,在单个MapReduce中会写入过多复杂的逻辑。
(2)RDD 特性
总体而言,Spark采用RDD以后能够实现高效计算的主要原因如下:
(1)高效的容错性。现有的分布式共享内存、键值存储、内存数据库等,为了实现容错,必须在集群节点之间进行数据复制或者记录日志,也就是在节点之间会发生大量的数据传输,这对于数据密集型应用而言会带来很大的开销。在RDD的设计中,数据只读,不可修改,如果需要修改数据,必须从父RDD转换到子RDD,由此在不同RDD之间建立了血缘关系。所以,RDD是一种天生具有容错机制的特殊集合,不需要通过数据冗余的方式(比如检查点)实现容错,而只需通过RDD父子依赖(血缘)关系重新计算得到丢失的分区来实现容错,无需回滚整个系统,这样就避免了数据复制的高开销,而且重算过程可以在不同节点之间并行进行,实现了高效的容错。此外,RDD提供的转换操作都是一些粗粒度的操作(比如map、filter和join),RDD依赖关系只需要记录这种粗粒度的转换操作,而不需要记录具体的数据和各种细粒度操作的日志(比如对哪个数据项进行了修改),这就大大降低了数据密集型应用中的容错开销;
(2)中间结果持久化到内存。数据在内存中的多个RDD操作之间进行传递,不需要“落地”到磁盘上,避免了不必要的读写磁盘开销;
(3)存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化开销。
(4)RDD 之间的依赖关系
RDD中不同的操作会使得不同RDD中的分区会产生不同的依赖。RDD中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency),图9-10展示了两种依赖之间的区别。
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区;比如图9-10(a)中,RDD1是RDD2的父RDD,RDD2是子RDD,RDD1的分区1,对应于RDD2的一个分区(即分区4);再比如,RDD6和RDD7都是RDD8的父RDD,RDD6中的分区(分区15)和RDD7中的分区(分区18),两者都对应于RDD8中的一个分区(分区21)。
宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。比如图9-10(b)中,RDD9是RDD12的父RDD,RDD9中的分区24对应了RDD12中的两个分区(即分区27和分区28)。
总体而言,如果父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖,否则就是宽依赖。窄依赖典型的操作包括map、filter、union等,宽依赖典型的操作包括groupByKey、sortByKey等。对于连接(join)操作,可以分为两种情况。
(1)对输入进行协同划分,属于窄依赖(如图9-10(a)所示)。所谓协同划分(co-partitioned)是指多个父RDD的某一分区的所有“键(key)”,落在子RDD的同一个分区内,不会产生同一个父RDD的某一分区,落在子RDD的两个分区的情况。
(2)对输入做非协同划分,属于宽依赖,如图9-10(b)所示。
对于窄依赖的RDD,可以以流水线的方式计算所有父分区,不会造成网络之间的数据混合。对于宽依赖的RDD,则通常伴随着Shuffle操作,即首先需要计算好所有父分区数据,然后在节点之间进行Shuffle。
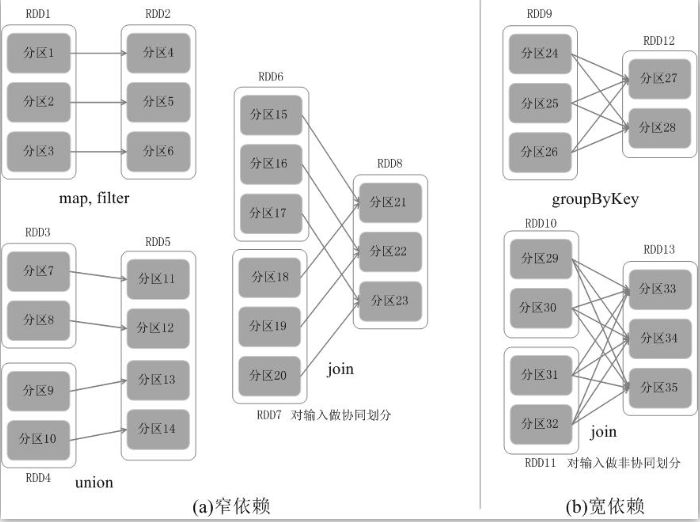
图9-10 窄依赖与宽依赖的区别
Spark的这种依赖关系设计,使其具有了天生的容错性,大大加快了Spark的执行速度。因为,RDD数据集通过“血缘关系”记住了它是如何从其它RDD中演变过来的,血缘关系记录的是粗颗粒度的转换操作行为,当这个RDD的部分分区数据丢失时,它可以通过血缘关系获取足够的信息来重新运算和恢复丢失的数据分区,由此带来了性能的提升。相对而言,在两种依赖关系中,窄依赖的失败恢复更为高效,它只需要根据父RDD分区重新计算丢失的分区即可(不需要重新计算所有分区),而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父RDD分区,开销较大。此外,Spark还提供了数据检查点和记录日志,用于持久化中间RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark会对数据检查点开销和重新计算RDD分区的开销进行比较,从而自动选择最优的恢复策略。
(5)阶段的划分
Spark通过分析各个RDD的依赖关系生成了DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分阶段,具体划分方法是:在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算(具体的阶段划分算法请参见AMP实验室发表的论文《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》)。例如,如图9-11所示,假设从HDFS中读入数据生成3个不同的RDD(即A、C和E),通过一系列转换操作后再将计算结果保存回HDFS。对DAG进行解析时,在依赖图中进行反向解析,由于从RDD A到RDD B的转换以及从RDD B和F到RDD G的转换,都属于宽依赖,因此,在宽依赖处断开后可以得到三个阶段,即阶段1、阶段2和阶段3。可以看出,在阶段2中,从map到union都是窄依赖,这两步操作可以形成一个流水线操作,比如,分区7通过map操作生成的分区9,可以不用等待分区8到分区9这个转换操作的计算结束,而是继续进行union操作,转换得到分区13,这样流水线执行大大提高了计算的效率。
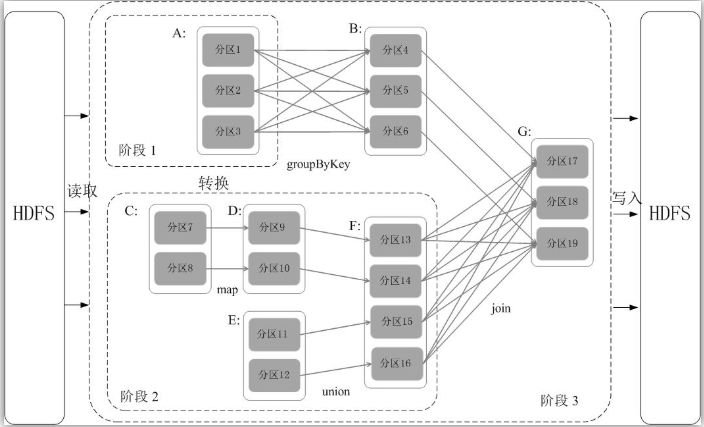
图9-11根据RDD分区的依赖关系划分阶段
由上述论述可知,把一个DAG图划分成多个“阶段”以后,每个阶段都代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集合。每个任务集合会被提交给任务调度器(TaskScheduler)进行处理,由任务调度器将任务分发给Executor运行。
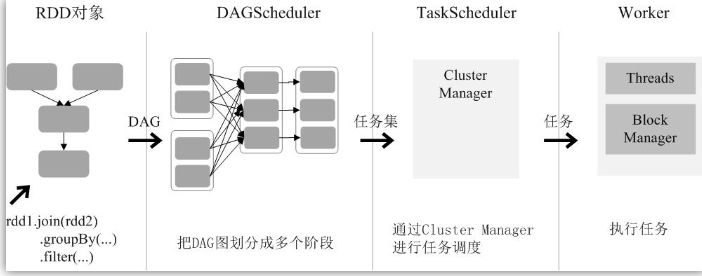
(6)RDD运行过程
通过上述对RDD概念、依赖关系和阶段划分的介绍,结合之前介绍的Spark运行基本流程,这里再总结一下RDD在Spark架构中的运行过程(如图9-12所示):
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
1.4 Spark的部署模式 http://dblab.xmu.edu.cn/blog/1713-2/
第2章 Spark的安装与使用(主要内容)
2.1 Spark的安装和使用 http://dblab.xmu.edu.cn/blog/1689-2/
如果想在window上安装,之后可以用pyspark或者jupyter上进行学习 https://blog.csdn.net/SummerHmh/article/details/89518567
(1) jdk 安装(这个太简单了,不想说)
(2) spark安装
Spark 从官网上下载Spark-2.4.1 解压后 bin目录为可执行文件,conf目录为配置目录
{https://www-eu.apache.org/dist/spark/spark-2.4.3/}
注意文件名之间不要有空格
SPARK_HOMED:\spark\spark-2.4.1-bin-hadoop2.7PATH ;%SPARK_HOME%\bin;%SPARK_HOME%;
Win10 的用户需要注意,需要进行小许改变,即分开,这里小编安装中遇到问题,所以尝试把 SPARK_HOME 删了,后期又闲懒,没复原,没影响的

运行效果:
C:\Users\ASUS>spark-shell09:49:49 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:379)at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:394)at org.apache.hadoop.util.Shell.(Shell.java:387) at org.apache.hadoop.util.StringUtils.(StringUtils.java:80) at org.apache.hadoop.security.SecurityUtil.getAuthenticationMethod(SecurityUtil.java:611)at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:273)at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:261)at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:791)at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:761)at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:634)at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2422)at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2422)at scala.Option.getOrElse(Option.scala:121)at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2422)at org.apache.spark.SecurityManager.(SecurityManager.scala:79) at org.apache.spark.deploy.SparkSubmit.secMgr$lzycompute$1(SparkSubmit.scala:359)at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$secMgr$1(SparkSubmit.scala:359)at org.apache.spark.deploy.SparkSubmit$$anonfun$prepareSubmitEnvironment$7.apply(SparkSubmit.scala:367)at org.apache.spark.deploy.SparkSubmit$$anonfun$prepareSubmitEnvironment$7.apply(SparkSubmit.scala:367)at scala.Option.map(Option.scala:146)at org.apache.spark.deploy.SparkSubmit.prepareSubmitEnvironment(SparkSubmit.scala:366)at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:143)at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)09:49:49 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableUsing Spark's default log4j profile: org/apache/spark/log4j-defaults.propertiesSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).Spark context Web UI available at http://DESKTOP-VMLNBLM:4040Spark context available as 'sc' (master = local[*], app id = local-1557712201588).Spark session available as 'spark'.Welcome to____ ____/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_/.__/\_,_/_/ /_/\_\ version 2.4.3/_/Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_131)Type in expressions to have them evaluated.Type :help for more information.scala>
出现一个小问题。
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.该问题是你缺少一个hadoop 编译 winutils.exe 解决方法如下:
step 1 : 从 (https://github.com/steveloughran/winutils)下载适合自己版本的文件;
step 2: 对该文件进行解压;
step 3: 配置环境变量:
①增加系统变量HADOOP_HOME,值是下载的zip包解压的目录,我这里解压后将其重命名为 hadoop-2.7.1
②在系统变量path里增加%HADOOP_HOME%\bin
③重启电脑,使环境变量配置生效,上述问题即可解决。
step 4: 重新运行程序
PS E:\pythonWp\sparkWP\wordCount> spark-shellUsing Spark's default log4j profile: org/apache/spark/log4j-defaults.propertiesSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).Spark context Web UI available at http://DESKTOP-VMLNBLM:4040Spark context available as 'sc' (master = local[*], app id = local-1557797366830).Spark session available as 'spark'.Welcome to____ ____/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_/.__/\_,_/_/ /_/\_\ version 2.4.3/_/Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_131)Type in expressions to have them evaluated.Type :help for more information.scala>
问题参考资料:
解Windows系统下运行hadoop、spark程序出错Could not locate executablenull\bin\winutils.exe in the Hadoop binaries
https://blog.csdn.net/love666666shen/article/details/78812622
(null) entry in command string exception in saveAsTextFile() on Pyspark
https://stackoverflow.com/questions/40764807/null-entry-in-command-string-exception-in-saveastextfile-on-pyspark
(3) spark与python 关联
需要利用pip安装 findspark
pip install findspark使用 findspark 模块调用 spark
# 引入模块import findspark
#可在环境变量中进行设置,即PATH中加入如下地址findspark.init("D:/progrom/spark")from pyspark import SparkContext as scfrom pyspark import SparkConf as conf
2.2 第一个Spark应用程序:WordCount
(1) scala 版本 http://dblab.xmu.edu.cn/blog/1311-2/
Step 1: 启动 spark-shell;
Step 2: 创建工作目录 wordCount;
Step 3: 创建文件 word.txt,并在里面写入信息。
Step 4: 利用 Scala 读取 文件
scala> val textFile = sc.textFile("E:/pythonWp/sparkWP/wordCount/word.txt")textFile: org.apache.spark.rdd.RDD[String] = E:/pythonWp/sparkWP/wordCount/word.txt MapPartitionsRDD[1] at textFile at <console>:24
上面代码中,val后面的是变量textFile,而sc.textFile()中的这个textFile是sc的一个方法名称,这个方法用来加载文件数据。这两个textFile不是一个东西,不要混淆。实际上,val后面的是变量textFile,你完全可以换个变量名称,比如,val lines = sc.textFile("E:/pythonWp/sparkWP/wordCount/word.txt")。这里使用相同名称,就是有意强调二者的区别。
注意,要加载本地文件,必须采用“file:///”开头的这种格式(linux 环境下)。执行上上面这条命令以后,并不会马上显示结果,因为,Spark采用惰性机制,只有遇到“行动”类型的操作,才会从头到尾执行所有操作。所以,下面我们执行一条“行动”类型的语句,就可以看到结果:
scala> textFile.first()res0: String = This is a first spark program . Now , We will study how to count the words by scala and python .
first()是一个“行动”(Action)类型的操作,会启动真正的计算过程,从文件中加载数据到变量textFile中,并取出第一行文本。屏幕上会显示很多反馈信息,这里不再给出,你可以从这些结果信息中,找到word.txt文件中的第一行的内容。
Step 5:文件保存
好了,现在我们可以练习一下如何把textFile变量中的内容再次写回到另外一个文本文件:
textFile.saveAsTextFile("E:/pythonWp/sparkWP/wordCount/writeback")执行这一句的时候,需要保证 已经配置好 hadoop 编译 winutils.exe , 否则会报错!
上面的saveAsTextFile()括号里面的参数是保存文件的路径,不是文件名。saveAsTextFile()是一个“行动”(Action)类型的操作,所以,马上会执行真正的计算过程,从word.txt中加载数据到变量textFile中,然后,又把textFile中的数据写回到本地文件目录“/usr/local/spark/mycode/wordcount/writeback/”下面:
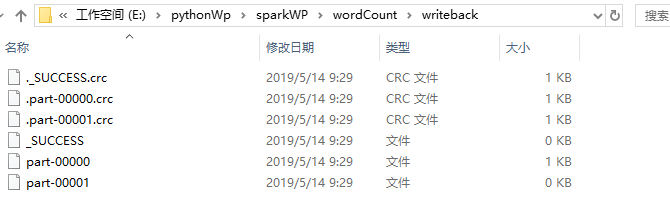
也就是说,该目录下包含两个文件,我们可以使用cat命令查看一下part-00000文件(注意:part-后面是五个零):
cat part-00000显示结果,是和上面word.txt中的内容一样的。
有了前面的铺垫性介绍,下面我们就可以开始第一个Spark应用程序:WordCount。
请切换到spark-shell窗口:
scala> val textFile = sc.textFile("E:/pythonWp/sparkWP/wordCount/word.txt")textFile: org.apache.spark.rdd.RDD[String] = E:/pythonWp/sparkWP/wordCount/word.txt MapPartitionsRDD[1] at textFile at <console>:24scala> textFile.first()res0: String = This is a first spark program . Now , We will study how to count the words by scala and python .scala> textFile.saveAsTextFile("E:/pythonWp/sparkWP/wordCount/writeback")scala> val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)wordCount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[5] at reduceByKey at <console>:25scala> wordCount.collect()res2: Array[(String, Int)] = Array((scala,1), (is,1), (.,2), (how,1), (will,1), (python,1), (Now,1), (This,1), (first,1), (We,1), (,,1), (program,1), (spark,1), (a,1), (to,1), (by,1), (count,1), (words,1), (study,1), (and,1), (the,1))
上面只给出了代码,省略了执行过程中返回的结果信息,因为返回信息很多。
下面简单解释一下上面的语句。
textFile包含了多行文本内容,textFile.flatMap(line => line.split(” “))会遍历textFile中的每行文本内容,当遍历到其中一行文本内容时,会把文本内容赋值给变量line,并执行Lamda表达式line => line.split(” “)。line => line.split(” “)是一个Lamda表达式,左边表示输入参数,右边表示函数里面执行的处理逻辑,这里执行line.split(” “),也就是针对line中的一行文本内容,采用空格作为分隔符进行单词切分,从一行文本切分得到很多个单词构成的单词集合。这样,对于textFile中的每行文本,都会使用Lamda表达式得到一个单词集合,最终,多行文本,就得到多个单词集合。textFile.flatMap()操作就把这多个单词集合“拍扁”得到一个大的单词集合。
然后,针对这个大的单词集合,执行map()操作,也就是map(word => (word, 1)),这个map操作会遍历这个集合中的每个单词,当遍历到其中一个单词时,就把当前这个单词赋值给变量word,并执行Lamda表达式word => (word, 1),这个Lamda表达式的含义是,word作为函数的输入参数,然后,执行函数处理逻辑,这里会执行(word, 1),也就是针对输入的word,构建得到一个tuple,形式为(word,1),key是word,value是1(表示该单词出现1次)。
程序执行到这里,已经得到一个RDD,这个RDD的每个元素是(key,value)形式的tuple。最后,针对这个RDD,执行reduceByKey((a, b) => a + b)操作,这个操作会把所有RDD元素按照key进行分组,然后使用给定的函数(这里就是Lamda表达式:(a, b) => a + b),对具有相同的key的多个value进行reduce操作,返回reduce后的(key,value),比如(“hadoop”,1)和(“hadoop”,1),具有相同的key,进行reduce以后就得到(“hadoop”,2),这样就计算得到了这个单词的词频。
(2) python 版本 http://dblab.xmu.edu.cn/blog/1692-2/
Step 1: 启动 pyspark
因为 pyspark 已经集成在spark 中了,所以只需要执行以下命令即可:
> pysparkPython 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32Type "help", "copyright", "credits" or "license" for more information.Using Spark's default log4j profile: org/apache/spark/log4j-defaults.propertiesSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).19/05/14 10:15:05 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//__ / .__/\_,_/_/ /_/\_\ version 2.4.3/_/Using Python version 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017 18:11:49)SparkSession available as 'spark'.Failed calling sys.__interactivehook__Traceback (most recent call last):File "D:\progrom\python\python\python3\lib\site.py", line 418, in register_readlinereadline.read_history_file(history)File "D:\progrom\python\python\python3\lib\site-packages\pyreadline\rlmain.py", line 165, in read_history_fileself.mode._history.read_history_file(filename)File "D:\progrom\python\python\python3\lib\site-packages\pyreadline\lineeditor\history.py", line 82, in read_history_filefor line in open(filename, 'r'):UnicodeDecodeError: 'gbk' codec can't decode byte 0xa7 in position 1332: illegal multibyte sequence>>>
Step 2: 加载本地文件
> textFile = sc.textFile('E:/pythonWp/sparkWP/wordCount/word.txt')> textFile.first()'This is a first spark program . Now , We will study how to count the words by scala and python .'> textFile.saveAsTextFile("E:/pythonWp/sparkWP/wordCount/writeback")
以上命令和之前介绍的类似,无须重复介绍。
Step 3: 词频统计
wordCount = textFile.flatMap(lambda line: line.split(" ")).map(lambda word: (word,1)).reduceByKey(lambda a, b : a + b)wordCount.collect()[Stage 2:> (0 + 2) / 2]D:\progrom\spark\python\lib\pyspark.zip\pyspark\shuffle.py:60: UserWarning: Please install psutil to have better support with spillingD:\progrom\spark\python\lib\pyspark.zip\pyspark\shuffle.py:60: UserWarning: Please install psutil to have better support with spilling[Stage 3:> (0 + 2) / 2]D:\progrom\spark\python\lib\pyspark.zip\pyspark\shuffle.py:60: UserWarning: Please install psutil to have better support with spillingD:\progrom\spark\python\lib\pyspark.zip\pyspark\shuffle.py:60: UserWarning: Please install psutil to have better support with spilling[('is', 1), ('.', 2), ('Now', 1), ('count', 1), ('scala', 1), ('python', 1), ('This', 1), ('a', 1), ('first', 1), ('spark', 1), ('program', 1), (',', 1), ('We', 1), ('will', 1), ('study', 1), ('how', 1), ('to', 1), ('the', 1), ('words', 1), ('by', 1), ('and', 1)]
上面只给出了代码,省略了执行过程中返回的结果信息,因为返回信息很多。
下面简单解释一下上面的语句。
textFile包含了多行文本内容,textFile.flatMap(labmda line : line.split(” “))会遍历textFile中的每行文本内容,当遍历到其中一行文本内容时,会把文本内容赋值给变量line,并执行Lamda表达式line : line.split(” “)。line : line.split(” “)是一个Lamda表达式,左边表示输入参数,右边表示函数里面执行的处理逻辑,这里执行line.split(” “),也就是针对line中的一行文本内容,采用空格作为分隔符进行单词切分,从一行文本切分得到很多个单词构成的单词集合。这样,对于textFile中的每行文本,都会使用Lamda表达式得到一个单词集合,最终,多行文本,就得到多个单词集合。textFile.flatMap()操作就把这多个单词集合“拍扁”得到一个大的单词集合。
然后,针对这个大的单词集合,执行map()操作,也就是map(lambda word : (word, 1)),这个map操作会遍历这个集合中的每个单词,当遍历到其中一个单词时,就把当前这个单词赋值给变量word,并执行Lamda表达式word : (word, 1),这个Lamda表达式的含义是,word作为函数的输入参数,然后,执行函数处理逻辑,这里会执行(word, 1),也就是针对输入的word,构建得到一个tuple,形式为(word,1),key是word,value是1(表示该单词出现1次)。
程序执行到这里,已经得到一个RDD,这个RDD的每个元素是(key,value)形式的tuple。最后,针对这个RDD,执行reduceByKey(labmda a, b : a + b)操作,这个操作会把所有RDD元素按照key进行分组,然后使用给定的函数(这里就是Lamda表达式:a, b : a + b),对具有相同的key的多个value进行reduce操作,返回reduce后的(key,value),比如(“hadoop”,1)和(“hadoop”,1),具有相同的key,进行reduce以后就得到(“hadoop”,2),这样就计算得到了这个单词的词频。
(3) 编写python独立应用程序执行词频统计 http://dblab.xmu.edu.cn/blog/1692-2/
Step 1: 安装 pyspark
pip install pysparkStep 2:请在“/usr/local/spark/mycode/wordcount/”目录下新建一个test.py文件,里面包含如下代码:
from pyspark import SparkContextsc = SparkContext( 'local', 'test')textFile = sc.textFile("E:/pythonWp/sparkWP/wordCount/word.txt")wordCount = textFile.flatMap(lambda line: line.split(" ")).map(lambda word: (word,1)).reduceByKey(lambda a, b : a + b)wordCount.foreach(print)
Step 3: 运行程序
> python .\wordcount.pyUsing Spark's default log4j profile: org/apache/spark/log4j-defaults.propertiesSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).19/05/14 10:26:19 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.19/05/14 10:26:19 WARN Utils: Service 'SparkUI' could not bind on port 4041. Attempting port 4042.[Stage 0:> (0 + 1) / 1]D:\progrom\python\python\python3\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:60: UserWarning: Please install psutil to have better support with spilling[Stage 1:> (0 + 1) / 1]D:\progrom\python\python\python3\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:60: UserWarning: Please install psutil to have better support with spilling('This', 1)('is', 1)('a', 1)('first', 1)('spark', 1)('program', 1)('.', 2)('Now', 1)(',', 1)('We', 1)('will', 1)('study', 1)('how', 1)('to', 1)('count', 1)('the', 1)('words', 1)('by', 1)('scala', 1)('and', 1)('python', 1)

【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!