
我们在学习Spark的时候,到底在学习什么?
我必须要说,Spark这个框架出现之前,我对很多大数据领域的框架源码甚至都是嗤之以鼻的。
很多小伙伴在群里或者私信留言问我关于Spark的学习路径问题。
Spark发展至今,应该说已经非常成熟了。是大数据计算领域不得不学习的框架。尤其是Spark在稳定性和社区发展的成熟度方面,基本可以吊打其他的大数据处理框架。
我之前发过一篇关于阅读Spark源码的文章:《Spark源码阅读的正确打开方式》。
我们在这篇文章的基础上总结一下我曾经总结过的关于Spark的路径。如果有什么更好的资料,欢迎大家加我微信推荐给我。
Spark的背景和核心论文
假如你是第一次接触Spark,那么你需要对Spark的设计思想有所了解,知道Spark用了哪些抽象,Spark在提出RDD的时候是基于什么样的考虑。
在这里给大家推荐几篇论文如下:
第一篇:《弹性分布式数据集:一种为内存化集群计算设计的容错抽象》,链接如下:
https://fasionchan.com/blog/2017/10/19/yi-wen-tan-xing-fen-bu-shi-shu-ju-ji-yi-zhong-wei-nei-cun-hua-ji-qun-ji-suan-she-ji-de-rong-cuo-mo-xing/
这篇文章中提出了弹性分布式数据集(RDD,Resilient Distributed Datasets)这个概念,这个概念是贯穿Spark设计的始终,是Spark最重要的概念之一。RDD是一种分布式的内存抽象,允许在大型集群上执行基于内存的计算(In-Memory Computing),与此同时还保持了MapReduce等数据流模型的容错特性。
这篇文章中提到,Spark实现RDD在迭代计算方面比Hadoop快二十多倍,同时还可以在5-7秒的延时内交互式地查询1TB的数据集。
- 第二篇:《大型集群上的快速和通用数据处理架构》
这本书我不给连接了。因为这个文章长达170多页,堪比一篇博士论文。相信绝大多数人都是没兴趣读完的。
我在这里给出一个读后小总结:
这本书是Spark框架设计者–计算机科学博士Matei Alexandru Zaharia和加州大学伯克利分校教授、主席Scott Shenker撰写的。书中作者主要分析了当前流行的各种计算框架的使用场景以及他们对应的缺点,然后谈了下为什么编写了Spark这个框架和spark每个模块详细的设计理念及运行原理,这里是做一部分摘要。
随着现在需要处理的数据量越来越大,单机处理要向集群进行扩展,这就会带来三个集群维度上的问题
1)并行化:多个节点同时进行数据处理
2)容错:在多节点上处理数据,节点的故障和慢节点会变得非常常见
3)资源的动态分配:一般集群都是在多个用户之前进行切换,所以资源的动态扩展和缩减就变得非常重要
和MapReduce对比 MapReduce做为计算引擎与Spark的区别在于:Spark RDD在并行计算阶段之间能够高效的共享数据。MapReduce计算模型中,map结果必须要从内存落到磁盘,然后reduce再将数据加载到内存中,得到的结果再次落到磁盘中;如果是多个MapReduce操作数据,那么reduce结果数据还要再次加载到下一个map内存。正是由于数据一次次从磁盘加载到内存,所以MapReduce才会异常的慢。这也是Spark和MapReduce的区别,Spark RDD能够将数据cache到内存中,省去了从磁盘加载的过程,同时Spark shuffle过程中的数据也是直接放在内存中的(为了避免shuffle失败map数据丢失Spark框架还对shuffle进行了checkpoint),这就是为什么spark比MapReduce块的原因。Spark解决的核心问题也就是数据流模型在计算过程中高效的共享数据 。RDD具有可容错和并行数据结构特征,这使得用户可以指定数据存储到硬盘还是内存、控制数据的分区方法并在数据集上进行种类丰富的操作。
容错 一般的框架有两种容错方式,提供容错性的方法就要么是在主机之间复制数据,要么对各主机的更新情况做日志记录。
第一种容错的方式恢复时间短但需要消耗更多的内存和磁盘空间用来存储数据。
第二种方式不需要额外内存但是恢复时间比较长。这两种方法对于数据密集型的任务来说代价很高,因为它们需要在带宽远低于内存的集群网络间拷贝大量的数据,同时还将产生大量的存储开销。与上述系统不同的是,RDD提供一种基于粗粒度变换(如, map, filter, join)的接口,该接口会将相同的操作应用到多个数据集上。这使得他们可以通过记录用来创建数据集的变换(lineage),而不需存储真正的数据,进而达到高效的容错性。当一个RDD的某个分区丢失的时候,RDD记录有足够的信息记录其如何通过其他的RDD进行计算,且只需重新计算该分区。因此,丢失的数据可以被很快的恢复,而不需要昂贵的复制代价。
RDD RDD是一个分区的只读记录的集合,用户可以控制RDD的其他两个方面:持久化和分区。用户可以选择重用哪个RDD,并为其制定存储策略(比如,内存存储),也可以让RDD中的数据根据记录的key分布到集群的多个机器,这对位置优化来说是有用的,比如可用来保证两个要Jion的数据集都使用了相同的哈希分区方式。默认情况下,Spark会将调用过persist的RDD存在内存中。但若内存不足,也可以将其写入到硬盘上。通过指定persist函数中的参数,用户也可以请求其他持久化策略并通过标记来进行persist,比如仅存储到硬盘上,又或是在各机器之间复制一份。最后,用户可以在每个RDD上设定一个持久化的优先级来指定内存中的哪些数据应该被优先写入到磁盘。RDD的第一个优点是可以使用lineage恢复数据,不需要检查点的开销,此外,当出现失败时,RDDs的分区中只有丢失的那部分需要重新计算,而且该计算可在多个节点上并发完成,不必回滚整个程序 RDD的第二个优点是,不可变性让系统像MapReduce那样用后备任务代替运行缓慢的任务来减少缓慢节点 (stragglers) 的影响 在RDDs上的批量操作过程中,任务的执行可以根据数据的所处的位置来进行优化,从而提高性能,其次,只要所进行的操作是只基于扫描的,当内存不足时,RDD的性能下降也是平稳的。不能载入内存的分区可以存储在磁盘上,其性能也会与当前其他数据并行系统相当。RDDS最适合对数据集中所有的元素进行相同的操作的批处理类应用。RDDS不太适用于通过异步细粒度更新来共享状态的应用,比如针对Web应用或增量网络爬虫的存储系统
宽窄依赖 窄依赖允许在单个集群节点上流水线式执行,这个节点可以计算所有父级分区 。相反,宽依赖需要所有的父RDD数据可用并且数据已经通过类MapReduce的操作shuffle完成 其次,在窄依赖中,节点失败后的恢复更加高效。因为只有丢失的父级分区需要重新计算,并且这些丢失的父级分区可以并行地在不同节点上重新计算。与此相反,在宽依赖的继承关系中,单个失败的节点可能导致一个RDD的所有先祖RDD中的一些分区丢失,导致计算的重新执行。
Spark的调度器会额外考虑被持久化(persist)的RDD的那个分区保存在内存中并可供使用,当用户对一个RDD执行Action(如count 或save)操作时,调度器会根据该RDD的lineage,来构建一个由若干 阶段(stage) 组成的一个DAG(有向无环图)以执行程序,每个stage都包含尽可能多的连续的窄依赖型转换。各个阶段之间的分界则是宽依赖所需的shuffle操作,或者是DAG中一个经由该分区能更快到达父RDD的已计算分区。之后,调度器运行多个任务来计算各个阶段所缺失的分区,直到最终得出目标RDD。调度器向各机器的任务分配采用延时调度机制并根据数据存储位置(本地性)来确定。若一个任务需要处理的某个分区刚好存储在某个节点的内存中,则该任务会分配给那个节点。否则,如果一个任务处理的某个分区,该分区含有的RDD提供较佳的位置(例如,一个HDFS文件),我们把该任务分配到这些位置。对应宽依赖类的操作 {比如w shuffle依赖),我们会将中间记录物理化到保存父分区的节点上。这和MapReduce物化Map的输出类似,能简化数据的故障恢复过程 对于执行失败的任务,只要它对应stage的父类信息仍然可用,它便会在其他节点上重新执行。如果某些stage变为不可用(例如,因为shuffle在map阶段的某个输出丢失了),则重新提交相应的任务以并行计算丢失的分区。(DAGscheduler官方定义) 若某个任务执行缓慢 (即"落后者"straggler),系统则会在其他节点上执行该任务的拷贝。这与MapReduce做法类似,并取最先得到的结果作为最终的结果。
Spark内存管理 Spark提供了三种对持久化RDD的存储策略:未序列化Java对象存于内存中、序列化后的数据存于内存及磁盘存储。第一个选项的性能表现是最优秀的,因为可以直接访问在JAVA虚拟机内存里的RDD对象。在空间有限的情况下,第二种方式可以让用户采用比JAVA对象图更有效的内存组织方式,代价是降低了性能。第三种策略适用于RDD太大难以存储在内存的情形,但每次重新计算该RDD会带来额外的资源开销。
对于有限可用内存,我们使用以RDD为对象的LRU(最近最少使用)回收算法来进行管理。当计算得到一个新的RDD分区,但却没有足够空间来存储它时,系统会从最近最少使用的RDD中回收其一个分区的空间。
除非该RDD便是新分区对应的RDD,这种情况下,Spark会将旧的分区继续保留在内存,防止同一个RDD的分区被循环调入调出。这点很关键–因为大部分的操作会在一个RDD的所有分区上进行,那么很有可能已经存在内存中的分区将会被再次使用。到目前为止,这种默认的策略在我们所有的应用中都运行很好, 当然我们也为用户提供了“持久化优先级”选项来控制RDD的存储。
大家可以看到,这7个概念都是Spark中最最核心的几个概念。我们在学习过程中是万万绕不过去的。
模块拆分&学习
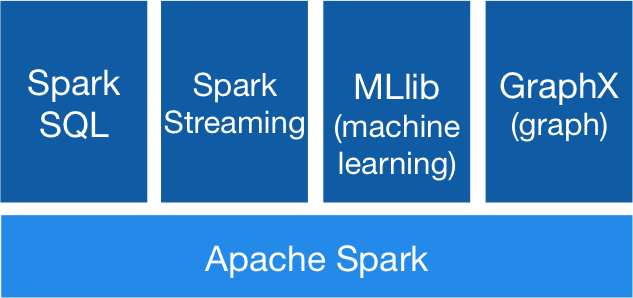

第一张图是官方给出的Spark架构图,我们可以看到几个最重要的模块:Spark Core、Spark Streaming、Spark SQL。曾经还有一个部分叫做Structured Streaming,但是这部分好像慢慢被官方抛弃了,现在Spark官方主推SQL并且基于Spark SQL进行的优化和迭代非常之多。如果你是第一次接触Spark,并且业务没有特殊需要,可以暂时忽略Structured Streaming。此外Spark社区在努力的像机器学习和深度学习靠拢,Spark在完成最初的流计算目标后开始发力机器学习方向,如果有兴趣可以接触这一部分的内容。
第二张图是一个简单的Spark快速学习的路线图,一些基本的Linux操作和运维基础,一点简单的搭建虚拟机的基础,我相信这些对大家来说都不是问题。然后我们就可以按照官网的demo进行第一次体验了:http://spark.apache.org/examples.html
Spark的官网中给出了非常简单的Spark入门案例,同样我们也可以直接访问Spark在Github的仓库直接看更多的Demo:
https://github.com/apache/spark/tree/master/examples/src/main/java/org/apache/spark/examples
书推荐
关于Spark的书,我个人读了应该有4-5本,每本书都没有达到我的预期,如果说你真的需要一本书来当成工具,我觉得下面的书和Github项目可以用来参考:
第一本书是:《大数据处理框架Apache Spark设计与实现》,这本书主要是介绍Spark的设计和原理,包含一部分源码。你可以把它当成一本八股文书来背,当然也可以当成一本指南来深入理解Spark的设计理念和深层次的原理。
这本书对应了一个Github的Repo:
https://github.com/wangzhiwubigdata/SparkInternals

还有一本电子书:http://marsishandsome.github.io/SparkSQL-Internal/
是关于Spark SQL的,这本书写的可谓用心良苦。对SparkSQL的发展历程和性能的优化、SparkSQL的使用方法、调优、架构、优化器Catalyst以及其他的各个模块都有详细介绍。
当然我也写过一些关于Spark SQL的经典文章:
《真·屠龙之术 | 一次SparkSQL性能分析与优化之旅及相关工具小结》
《SparkSQL的自适应执行-Adaptive Execution》
Github推荐
除了上面的推荐书对应的repo,还有一个酷玩Spark:
https://github.com/wangzhiwubigdata/CoolplaySpark
这个仓库是由腾讯广告部的同学发起的,主要是Spark 源代码解析、Spark 类库等,源代码部分对Spark Streaming 和 Structured Streaming部分由非常深入的解释。但是这个仓库最后一次维护已经是2019年五月份。大家都知道2019年底Flink开源,可能抢了一部分热度,很多公司都开始转向对Flink的研究。
源码阅读
Spark至今只经历过1.x、2.x和3.x三个大版本的变化,在核心实现上,我们在Github能看到的最早的实现是0.5版本,这个版本只有1万多行代码,就把Spark的核心功能实现了。
当然我们不可能从这么古老的版本看,假如你接触过Spark,现在准备看源码,那么我建议从2.x版本中选取一个,最好是2.3或者2.4。但是经过如此多的迭代,Spark的代码量已经暴增了几倍。关于Spark3.x中的新增功能和优化例如动态资源分配,可以针对性的进行补充即可。
我把最重要的模块列表如下:
Spark的初始化
SparkContext SparkEnv SparkConf RpcEnv SparkStatusTracker SecurityManager SparkUI MetricsSystem TaskScheduler
Spark的存储体系
SerializerManager BroadcastManager ShuffleManager MemoryManager NettyBlockTransferService BlockManagerMaster BlockManager CacheManager
Spark的内存管理
MemoryManager MemoryPool ExecutionMemoryPool StorageMemoryPool MemoryStore UnifiedMemoryManager
Spark的运算体系
LiveListenerBus MapOutputTracker DAGScheduler TaskScheduler ExecutorAllocationManager OutputCommitCoordinator ContextClearner
Spark的部署模式
LocalSparkCluster Standalone Mater/Executor/Worker的容错
Spark Streaming
StreamingContext Receiver Dstream 窗口操作
Spark SQL
Catalog TreeNode 词法解析器Parser RuleExecutor Analyzer与Optimizer HiveSQL相关
其他
假如你对图计算Spark GraphX和机器学习Spark MLlib感兴趣,可以单独看看。
一些可以直接入门的项目
我曾经发过一些可以直接入门的项目,大家可以参考:
这里就不得不说B站了,你可以在B站找到非常丰富的学习资源,甚至我自己也曾经上传过关于Spark的项目。
我这里找了一个不错的入门视频:https://www.bilibili.com/video/BV1tp4y1B7qd
另外下面这篇文章也是一个完整的入门案例:
《Spark Streaming + Canal + Kafka打造Mysql增量数据实时进行监测分析》
另外,给自己打个广告,我个人从一个弱鸡资源UP主正式开始自己录制视频,要当一个合格的大数据领域硬核原创作者。主要专注关于面试&学习路线&个人成长&职场进阶。欢迎各位大大关注:
调优和面试
好了,这部分就是我个人曾经发过的文章总结了,大家面试不会吃亏的:
《Spark Streaming性能优化: 如何在生产环境下动态应对流数据峰值》
好了,本次分享就到这里了。欢迎大家「分享」和「在看」。
我是王知无,一个大数据领域的硬核原创作者,关注技术提升&个人成长&职场进阶,欢迎关注。