spark学习笔记3之spark样例分析
github样例
一开始自己写案例还是比较费劲的,我们还是遵照那个原则,先大步快跑,搞定全局,再回头查缺补漏。
https://github.com/apache/spark/tree/master/examples计算圆周率Pi
scala代码如下:
/**
* @author Ted
* @date 2022/2/9 15:48
* @version 1.0
*/
object SparkPi {
def main(args: Array[String]): Unit = {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("Spark Pi")
.getOrCreate()
val slices = if (args.length > 0) args(0).toInt else 2
val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow
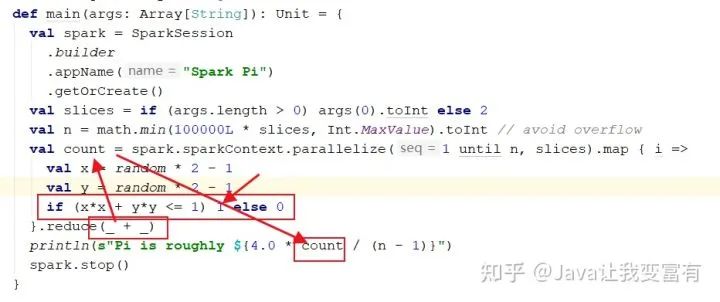
val count = spark.sparkContext.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y <= 1) 1 else 0
}.reduce(_ + _)
println(s"Pi is roughly ${4.0 * count / (n - 1)}")
spark.stop()
}
}
}逻辑分析
我们都知道圆的面积公式为  。此时我们画一个半径为1的圆。然后再往圆上套一个边长为2的正方形。之后我们开始随机向这个正方形领域描点。随着我们描点的数据量越来越大,在圆里面的点和在正方形里的点的数量之比就会越来越趋近于一个常数。而这个常数其实也近似等于 圆和正方形的面积之比。如下:
。此时我们画一个半径为1的圆。然后再往圆上套一个边长为2的正方形。之后我们开始随机向这个正方形领域描点。随着我们描点的数据量越来越大,在圆里面的点和在正方形里的点的数量之比就会越来越趋近于一个常数。而这个常数其实也近似等于 圆和正方形的面积之比。如下:

由于我们的圆半径为1,正方形边长为2。所以就会得出

园中的点用代码表示为如下,当x²+y²小与1时,点肯定落在圆内,取值1,让count总数+1。
运行代码
由于样例函数的jar包在spark安装包中存在,我们直接用如下命令运行程序,并指定参数。本次指定10个分区,100万条数据。
../../bin/spark-submit --master spark://node1:7077,node2:7077 --class org.apache.spark.examples.SparkPi ./spark-examples_2.11-2.3.4.jar 10
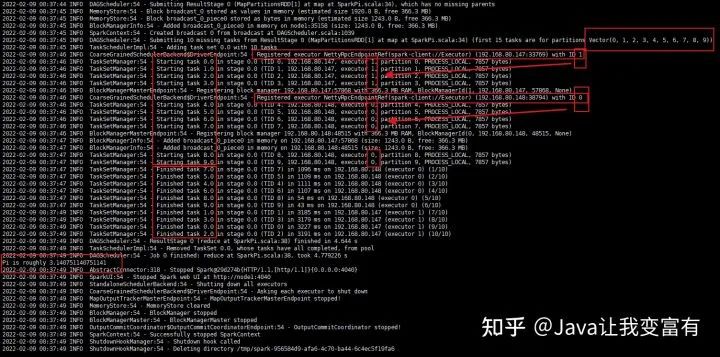
会从后台看到已经运行了一个spark程序,核心数12,执行速度6秒。执行过程如下,启动了10个任务并行计算。每个执行器都有自己的唯一id,每个任务也有自己的唯一id。然后每个任务由指定的执行器进行执行。最后得出结果为Pi is roughly 3.140751140751141。可见还不太准确。那么我们接下来继续加码计算量。
扩大数据量
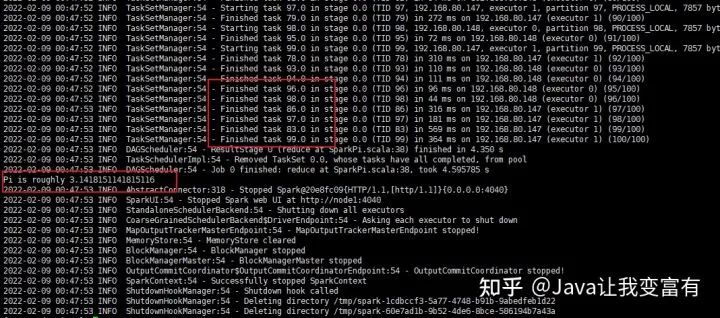
接下来我们输入100参数,1000万条数据进行计算。看来任务量还是不足,计算结果还未接近
Pi is roughly 3.1418151141815116
继续扩大数据量
本次我们开启1000个任务,给他一个亿。可以看到,147和148已经不够用了,把他的兄弟146也叫了起来。但是还是不给力啊。
Pi is roughly 3.1417156714171566
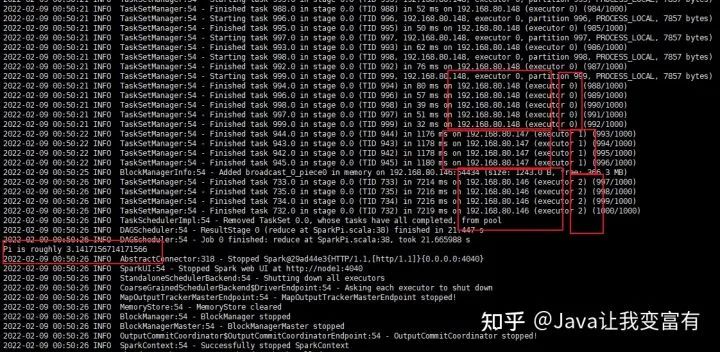
拼了
这次直接开启10000个任务,算它10亿次。终于看到了我脑海中记忆到的那个数字了。
Pi is roughly 3.141595919141596
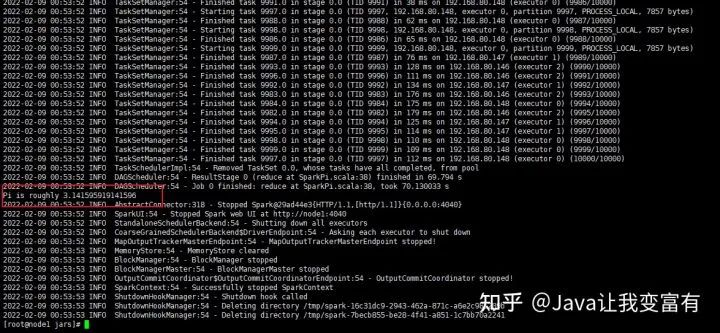
运行脚本
接下来,我们直接编写一个运行脚本来运行我们的spark计算程序。当然平时我们需要养成一个习惯,将这些运行程序收集到一个目录下边。例如如下,我们在root家目录创建于给sparkexe目录。将我们的脚本放到里面。
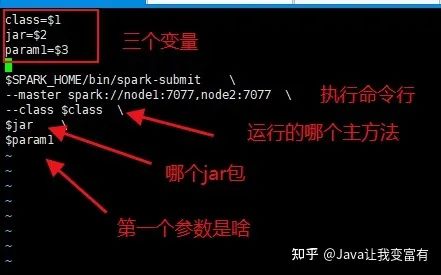
然后我们执行如下命令,就可以了。
. submit 'org.apache.spark.examples.SparkPi' "/opt/bigdata/spark-2.3.4-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.3.4.jar" 100
10000个任务,10亿次计算细节如下。
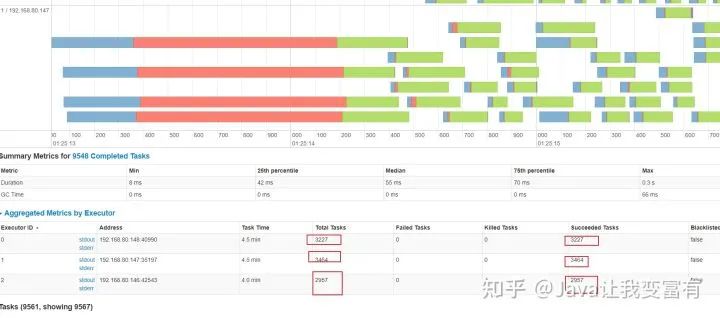
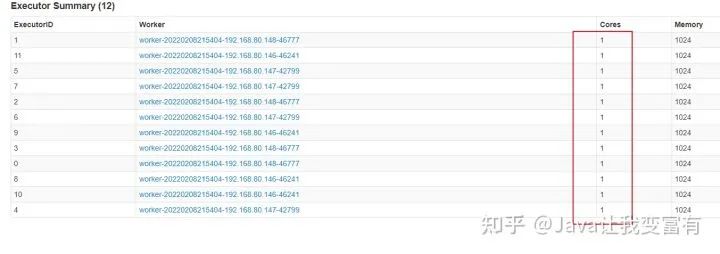
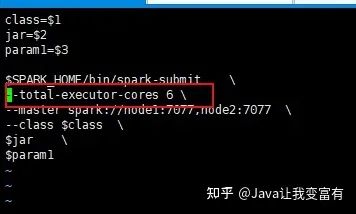
指定核心数量
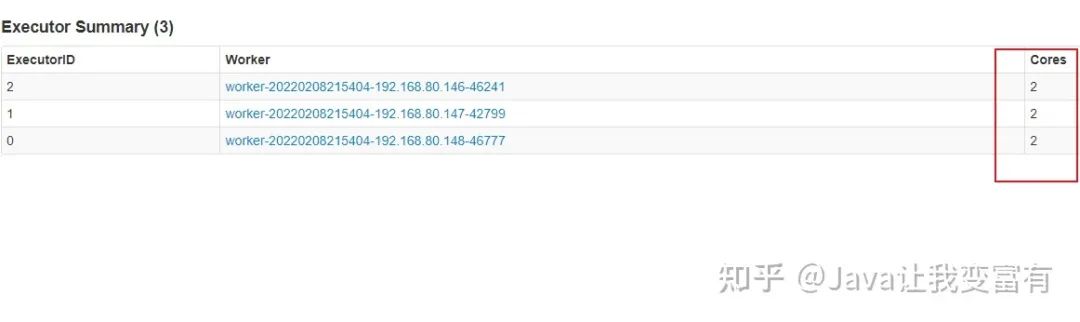
我们还可以指定spark任务执行中可以申请的核心数量,上述过程都直接申请了12个核心,每个执行器4个核心。接下来我们指定核心数量为6个。那么每个执行器会分配两个核心。
指定执行器核心
如果我们制定每个执行器只能拥有一个核心,同时我们指定本次任务分配12个核心。那么就会出现12个执行器。