
深度学习attention机制中的Q,K,V分别是从哪来的?
提问:找了各种资料,也读了论文原文,都是详细介绍了怎么把Q,K,V通过什么样的运算得到输出结果,始终没有一个地方有解释Q,K,V是从哪来的?一个layer的输入不就是一个tensor吗,为什么会有Q,K,V这三个tensor?
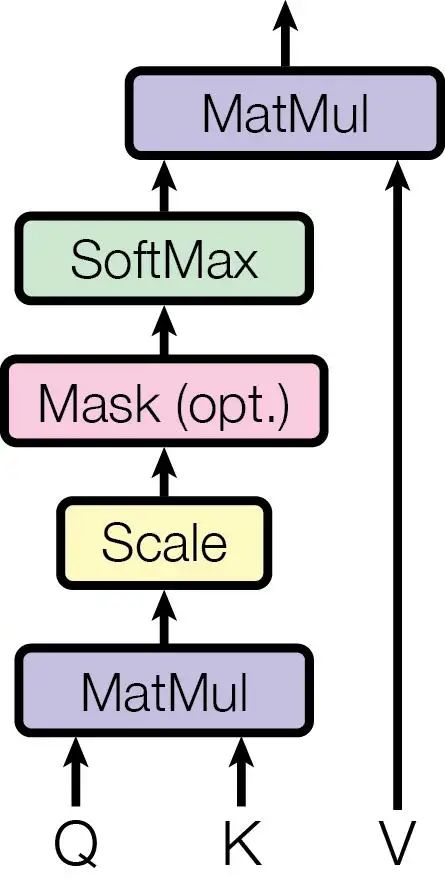
IIIItdaf回答:
我一做CV的,因为在了解Transformer,今天看Self-Attention中的QKV,也产生了此疑惑,为什么非要定义三个tensor,故搜到此问题。感觉各位都讲得不错,但还可以说得更直白一点。我大概意会了一下,因为写答案做图很麻烦也没什么经验,就简单说说我的理解,不一定准确,见谅。
注意力机制说白了就是要通过训练得到一个加权,自注意力机制就是要通过权重矩阵来自发地找到词与词之间的关系。因此肯定需要给每个input定义tensor,然后通过tensor间的乘法来得到input之间的关系。那这么说是不是给每个input定义1个tensor就够了呢?不够啊!如果每个input只有一个相应的q,那么q1和q2之间做乘法求取了a1和a2的关系之后,这个结果怎么存放怎么使用呢?而且a1和a2之间的关系是对偶的吗?如果a1找a2和a2找a1有区别怎么办?只定义一个这模型是不是有点太简单了。
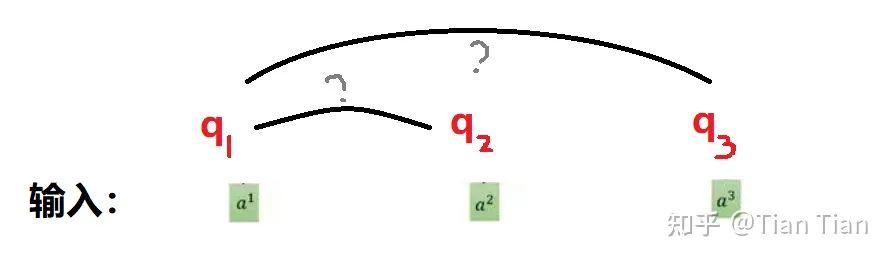
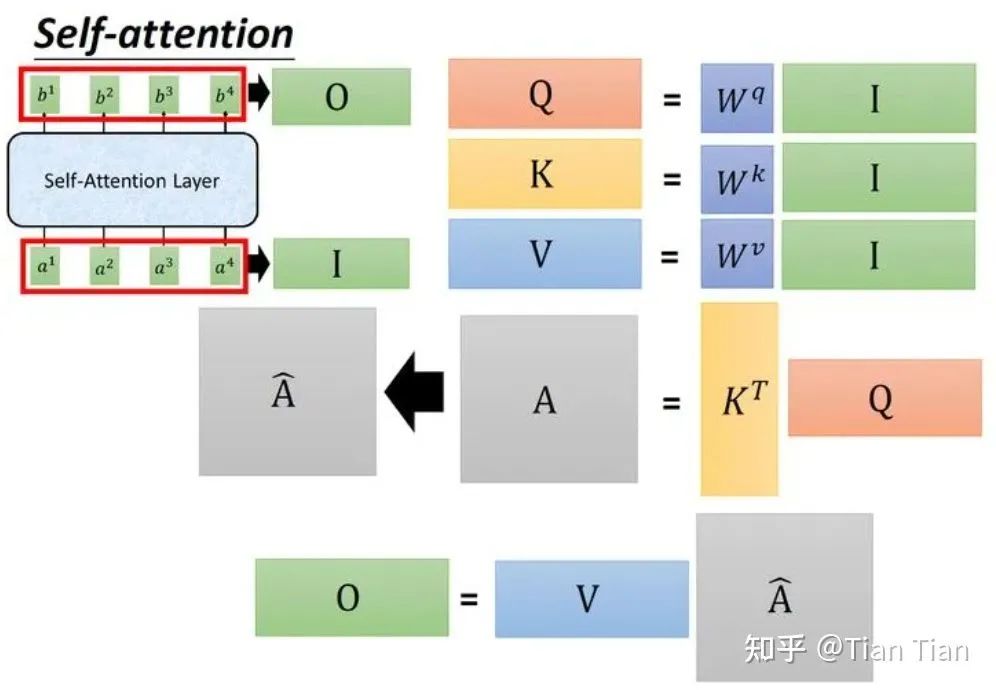
一个不够就定义两个,于是有了q和k。q你可以理解为代表自己用的,用q去和别的输入找关系;k理解为给别人用的,专门对付来跟你找关系的输入。这样子,用自己的q去和别人的k(当然和自己的k也行)做乘法,就可以得到找出的关系:权重 α 了。
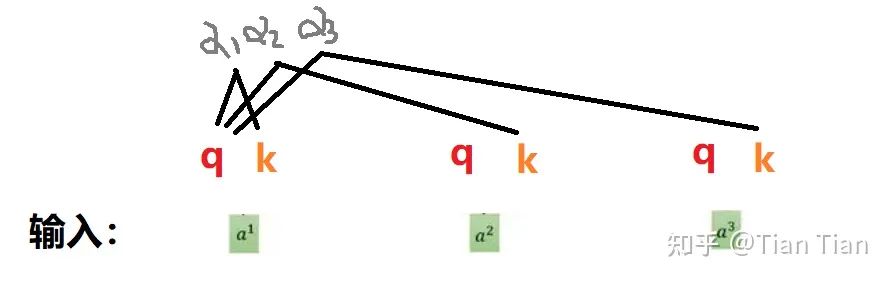
仅定义q和k两个够吗?可能也还是不够的。找出来的关系是要用的,不用等于白找。权重α是要对输入信息做加权,才能体现找到的关系的价值的。那跟输入直接加权行吗?这么做也不是不行,就是显得直接和生硬了点。所以又定义了个v。要知道,v和q、k一样,都是通过系数矩阵对输入a做乘法得到的。所以定义了个v大概等于又对a加了一层可以学习的参数,然后对经过参数调整后的a再去做加权、把通过注意力机制学到的关系给用上。所以,通过α和v的乘法进行加权操作,最终得到输出o。
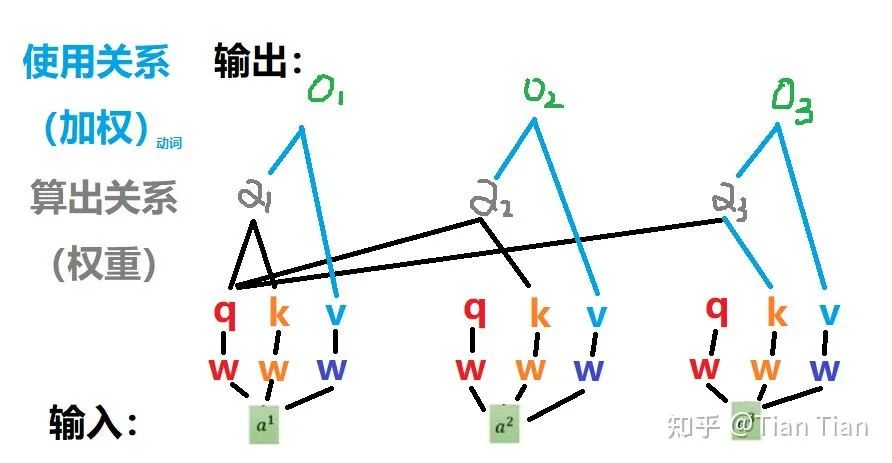
综上,我的感觉是,定义这3个tensor,一方面是为了学习输入之间的关系、找到和记录谁和谁的关系权重,一方面也是在合理的结构下引入了可学习的参数,使得网络具有更强的学习能力。底下这个图把他们之间的关系画得挺好了,来源于“极市平台《搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了》”,侵删。
个人粗浅解读,如有不妥请指教。我继续学习注意力去了……
文章转载自知乎,著作权归属原作者,侵删
——The End——

