
CV往哪卷?李飞飞指出三颗「北极星」:具身智能,视觉推理和场景理解
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
转载自:新智元 | 编辑:LRS
转载自:新智元 | 编辑:LRS
【导读】ImageNet见证了计算机视觉发展的辉煌历程,在部分任务性能已超越人类的情况下,计算机视觉的未来又该如何发展?李飞飞最近发文指了三个方向:具身智能,视觉推理和场景理解。
在深度学习革命进程中,计算机视觉依托大规模数据集ImageNet,在图像分类、目标检测、图像生成等多个任务都表现出惊人的性能,甚至比人类的准确率还要高!
但CV为何能取得如此巨大的成就?未来将向何处发展?
最近,「华人AI女神」李飞飞在美国文理科学院的会刊 Dædalus 上发表了一篇文章,以计算机视觉中的物体识别任务为切入点,研究了ImageNet数据集及相关算法的发展历程。

文章链接:https://www.amacad.org/publication/searching-computer-vision-north-stars
文章认为技术的发展很大程度上源于对北极星(North Stars)的追求。「北极星」在这里指的是研究人员专注于解决一个科学学科中的关键问题,可以激发研究热情并取得突破性的进展。
在ImageNet和物体识别的成功之后,越来越多的北极星问题涌现出来。
这篇文章主要讲述了ImageNet的简要历史、其相关工作以及后续进展。其目的是激发更多北极星问题相关的工作,以推动该领域乃至整个人工智能的发展。

文章第二作者Ranjay Krishna是华盛顿大学艾伦计算机科学与工程学院的助理教授,2021年从斯坦福大学博士毕业,导师为李飞飞,主要研究方向为计算机视觉和人机交互的交叉领域,利用源于社会和行为科学的框架来开发机器学习模型的表示、互动、模型、训练范式、数据收集pipeline和评估协议。

ImageNet的前世今生
ImageNet的前世今生
对大部分普通用户来说,人工智能是一个飞速发展的领域,当然,一切都是源于现代计算机科学的工程壮举,尤其是近几年,AI的工程进展速度越来越快。
从垃圾电子邮件的过滤到个性化的推荐系统,再到汽车里的智能自主刹车,系统内都是大量的工程实践。
工程背后的科学往往被忽视了。

作为AI领域的研究人员,往往对工程和科学有着深刻的认识,会认为二者是密不可分、相辅相成。在实践中激发新的思路和探索,随着时间的推移,将之付诸为工程实践。
一旦确定了基本问题,找到了下一个北极星,你就已经处于领域的前沿了。正如爱因斯坦所说:提出一个问题往往比解决这个问题更重要。
自1950年起,人工智能领域就由各种北极星问题所驱动,当时图灵巧妙地提出了如何判断一台计算机是否值得被称为智能的问题,即「图灵测试」
6年后,当人工智能的奠基人计划举办达特茅斯会议时,他们设定了另一个雄心勃勃的目标,提议建造能够「使用语言、形成抽象和概念、解决现在留给人类的各种问题,并改进自己」的机器。

如果没有这道指路明灯,我们可能永远无法解决新问题。
在人工智能的研究中,视觉是核心,一些进化生物学家假设,动物眼睛的优先进化导致了物种的不同。
那如何教计算机看东西呢?
在世纪之交时,受之前大量相关工作的启发,李飞飞及合作者提出一个物体识别的问题:计算机正确识别给定图像中出现的内容的能力。
这似乎是一个有前途的北极星问题,在1990年到2000年初的十几年时间里,物体识别的研究人员已经朝着这个艰巨的目标取得了巨大的进步,但由于现实世界物体的外观千差万别,取得的进展十分缓慢。
即使在一个单一的、具体的类别(如房子、狗或花)中,物体看起来也可能完全不同。例如,能够准确将照片中的物体识别为狗的AI模型,无论它是德国牧羊犬、贵宾犬还是吉娃娃,无论是从正面还是侧面拍摄,奔跑接球或四肢着地,或者脖子上围着蓝色头巾,都应该能正确识别。简而言之 ,狗相关的图像种类繁多,令人眼花缭乱,而过去教计算机识别此类物体的模型无法应对这种多样性。
一个主要原因是过去的模型倾向于使用手工设计的模板来捕捉图像中的特征,模型缺乏大规模图像数据的输入,无法应付物体的多样性。
这意味着,我们需要一个全新的数据集来实现三个设计目标:大规模、多样性和高质量。

首先是规模,心理学家假设,类似人类的感知需要接触上千种不同的物体。当幼儿开始学习时,他每天的生活已经开始接触大量的图像。例如,六岁的孩子大概已经看过了三千个不同的物体,并且学到了足够多的特征来帮助区分三万多个类别。
而当时,最常用的物体识别数据集只包含20种物体,所以扩展数据集很重要,我们从互联网搜集了1500万张图像,并将其标注出对应的物体类别。
参照WordNet,李飞飞将新的数据集命名为ImageNet
第二是多样性。从互联网上搜集的图像涵盖了许多类别,光鸟类就有八百多种,总共包括21841个类别来组织这上千万张图像。为了让训练后的模型更鲁棒,ImageNet中的数据包含了各种场景下的图像,例如「厨房中的德国牧羊犬」等,并且还给类别标注了上下位词,如哈士奇包括「阿拉斯加哈士奇」和「重毛北极雪橇犬」

第三点是质量。为了创造一个可以复制人类视力敏锐度的金标准数据集,ImageNet只接收高分辨率的图像。为了让标签的准确率更高,研究团队请普林斯顿大学的本科生来标记并验证这些标签,后来使用了亚马逊的众包平台,最终在2007年至2009年间迅速从167个国家和地区雇佣了大约5万名标注人员来标记和验证数据集中的物体。
有了ImageNet数据,如何让它发挥作用成了关键。
ImageNet团队一致认为:免费开放给任何感兴趣的研究人员,还设立了年度竞赛来激励相关模型的开发。
转折点出现在2012年,AlexNet横空出世,首次将卷积神经网络应用于物体识别,并且准确率碾压第二名参赛者。
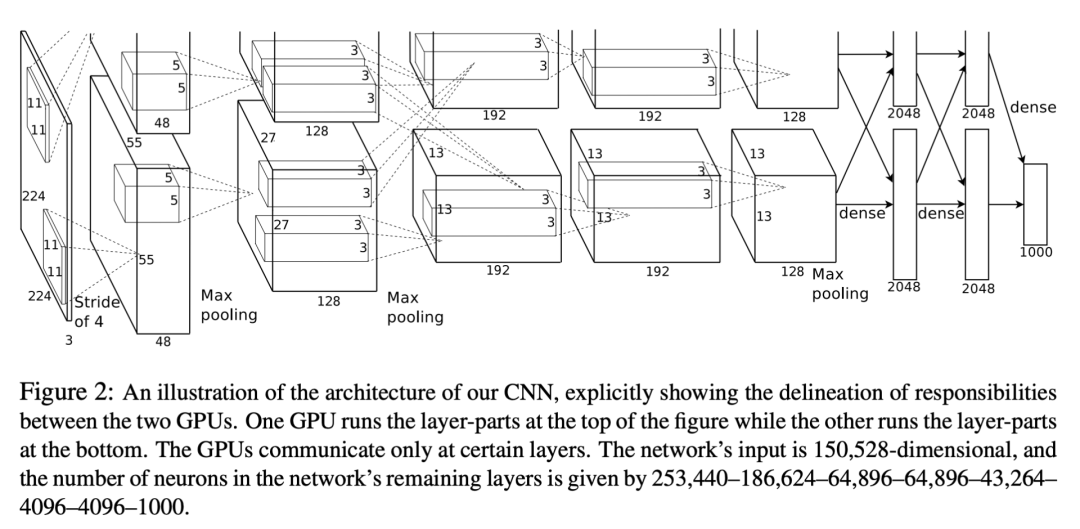
虽然此前神经网络已经研究了几十年,但正是ImageNet让神经网络发挥了其本来的威力。
一年之内,几乎所有的AI论文都是关于神经网络了。随着更多人参与研究,物体识别的准确率也越来越高。
2017年,挑战赛完结。八年来,参赛选手将算法正确识别率从71.8%提升到97.3%,这样的精度甚至已经超越了我们人类自己(95%)。
学会识别物体只是学习「看」的一种形式,计算机视觉领域还有更多的任务,如目标检测等,但它们之间都存在着某些相似之处,这也意味着经验可以用来参考借鉴。
从理论上来讲,计算机应该可以利用到这些相似之处,这一过程也称之为「迁移学习」
人类非常擅长迁移学习,并且迁移学习对AI也有极大的帮助,目前帮助计算机进行迁移学习的方法就是预训练,起点就是用ImageNet数据集学习物体识别。
但这并不是说ImageNet对所有计算机视觉都有用。
一个例子是医学成像。在概念上讲,对医学图像(如筛查肿瘤)进行分类的任务与识别手机拍摄的图像没有本质区别,都需要视觉图像和类别标签,也可以经过适当训练的模型来判断。
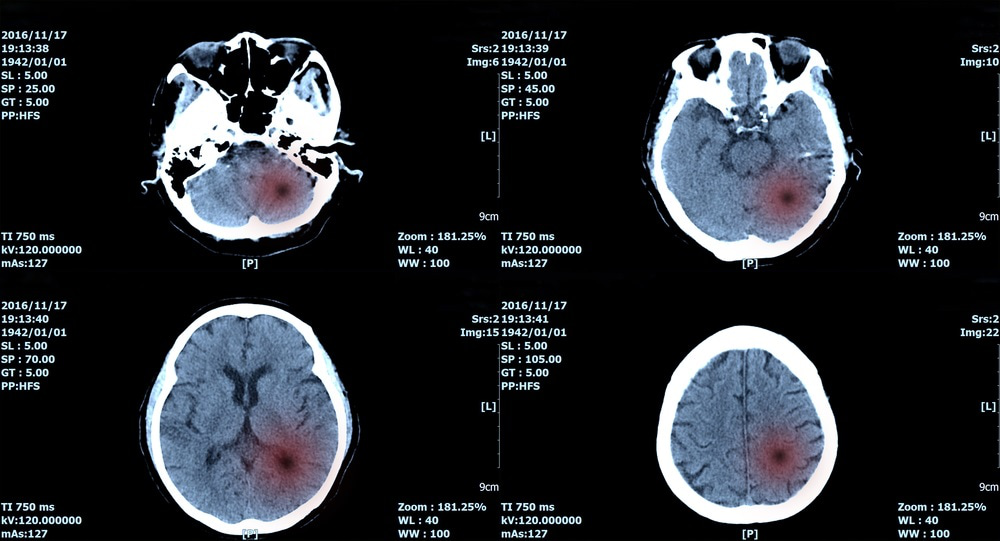
但ImageNet数据集并不能用来筛查肿瘤,因为里面根本没有这个任务的相关数据。更重要的是,使用众包平台也基本不可行,标注医疗诊断相关的数据需要非常高的专业知识,稀缺且昂贵。
计算机视觉当然也有其他应用场景,例如分析卫星图像来帮助政府评估作物产量,水位、森林砍伐和野火的变化,并跟踪气候变化。
ImageNe的使用也带来一个问题,人们过于关注大规模数据,而忽视了单一数据的影响。例如某些「对抗样例」通过修改单个像素,就可以让模型错误地分类图像,目前有研究人员也在致力于研究如何抵御攻击。
最后,ImageNet的广泛影响使数据集接受了一些批评,也引起了一些创立之初没有充分考虑的问题。
其中最严重的是人物肖像的公平问题。尽管我们很早就知道要过滤掉一些诸如种族、性别歧视等公然诋毁的图像标签,但数据集中还是存在一些微妙的问题:例如那些本质上不是贬义,但应用不当可能会引起冒犯的标签。
尽管这些公平问题很难完全消除,但也有一些工作致力于减轻偏差的影响。
CV北极星在哪?
CV北极星在哪?
计算机视觉的下一步朝哪发展?
作者认为其中最具潜力的领域是具身人工智能(embodied AI),即能够用于导航、操作和执行指令等任务的机器人。
机器人并不是指有头、两条腿走路的人形机器人,任何在空间中移动的有形智能机器都是一种具身人工智能的形式,无论是自动驾驶汽车、机器人吸尘器,还是工厂里的机械臂。正如ImageNet旨在代表现实世界广泛而多样的图像一样,具身人工智能的研究需要解决人类任务的复杂多样性,小到叠衣服,大到探索新城市。

另一颗北极星是视觉推理(visual reasoning),例如理解一个二维场景中的三维关系等。可以想象一个场景,即使是让机器人执行一个看似非常简单的指令,如「将杯子带回麦片碗的左边」也需要视觉推理。执行这样的指令当然需要比视觉更多的东西,但视觉是一个重要的组成部分。

理解场景中的人,包括社会关系和人的意图,又增加了另一个层次的复杂性,这种基本的社会智能也是计算机视觉的一颗北极星。比如看到一个女人搂着腿上的小女孩,这两个人很可能是母女关系;如果一个男人打开冰箱,他可能是饿了。但目前计算机还没有足够的智能来推断这些事情。
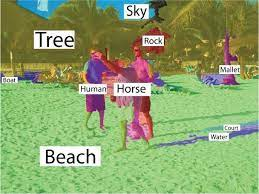
计算机视觉,就像人类视觉一样,不仅仅是感知,还需要深入的认知。毫无疑问,所有这些北极星都是巨大的挑战,比ImageNet还大的挑战。
通过看图片来识别狗或椅子是一回事,而思考和浏览无限的人和空间的世界是另一回事。
但这是一组非常值得追求的挑战:随着计算机视觉智能的展开,世界可以成为一个更好的地方。医生和护士将拥有一双不知疲倦的眼睛来帮助他们诊断和治疗病人,汽车将更安全地运行,机器人将帮助人类勇闯灾区来拯救被困者和伤员。
而科学家们可以在更强大的智能机器的帮助下,突破人类的盲点,发现新的物种、更好的材料,以及探索未知的领域。
参考资料:
ttps://www.amacad.org/publication/searching-computer-vision-north-stars
本文仅做学术分享,如有侵权,请联系删文。