↑↑↑点击上方蓝字,回复资料,10个G的惊喜
人们常说「隔行如隔山」,机器学习社区在外行人眼里是什么样的?
近日,一位来自传统行业的从业者观察了机器学习研究社区的现状,发现了一些问题并在 reddit 上发帖,不少机器学习从业者也纷纷表达观点,参与讨论。帖子作者注意到,机器学习社区内有很多研究者正致力于优化、控制、信号处理等「旧领域」的交叉研究,他们会突然发表大量声称要解决某个问题的论文,问题本身通常是近期的,使用的方法会包含一些深度神经网络。然而仔细一看,这些研究唯一新颖的地方只有提出的问题,而不是研究人员解决该问题的方案。让他困惑的是,为什么大量这种看起来水平一般,几乎就是对各领域内 20 世纪 80 年代,甚至 60 年代以后的技术重新编排的文章却能够被接受?经过仔细研究,作者发现机器学习社区存在一些问题。许多研究者只在机器学习会议上发表论文,而不会在其研究的专属会议或期刊(例如优化和控制领域期刊)上发表。例如,在一篇对抗机器学习论文中,整篇论文的内容几乎都是关于解决一个优化问题的,但提出的优化方法基本是其他成熟研究成果的变体。作者还注意到,如果一篇论文没有被 NeurIPS 或 ICLR 接收,它就会被转投给 AAAI 或其他名气小一点的会议,真是一点也不浪费。
有人评论称,这其实和会议的名气有关:「在 NeurIPS 等机器学习顶会上发表的研究,收益可能是其他会议的十倍。但有一些子领域的会议也很受重视,比如计算机视觉领域的 CVPR、自然语言处理领域的 ACL 会议等。」
通过开放评审,我发现审稿人(不只是研究者)对所属的具体领域一无所知。他们似乎只是在审核论文的正确性,而不是新颖性。实际上,我对审稿人是否了解该方法的新颖程度表示怀疑。评论区有网友表示:这一问题也是存在的,但似乎很难解决。因为机器学习领域正在呈爆炸式增长,并不是每个审稿人都能够跟得上该领域的发展步伐,有些审稿人掌握的知识信息的确有些滞后。
通常,ML 领域的研究人员只会从最近几年的研究中引用自己或其他机器学习从业者的研究。偶尔会有一个引用数百年前研究的情况,那可能是因为与牛顿、柯西等人的经典研究有关。然后引用研究的年份就会突然跳到 2018、2019 年。有人指出,这一问题主要是追溯难度太大造成的。经过多年的发展,很多名词术语的叫法已经和几十年前不一致了。当前机器学习社区中的论文引用主要来自于谷歌搜索,有些名词想要找到其原始出处并不容易。论文中经常存在堆砌数学公式的情况,形成一堵巨大的「数学墙」,例如证明特征值、梯度、雅可比矩阵等数学问题的深奥条件。有些定理其实并不适用,因为在高度非凸的深度学习应用中,定理的前提条件就不满足。因此,从这些错综复杂的数学定理中唯一获得的东西就是一些微弱的直觉,这些直觉还可能会被立刻推翻。有网友指出,「数学墙」非常令人沮丧。由于带有数学公式的论文似乎更容易被接收,很多论文都加入了公式,但有时公式并不是必要的。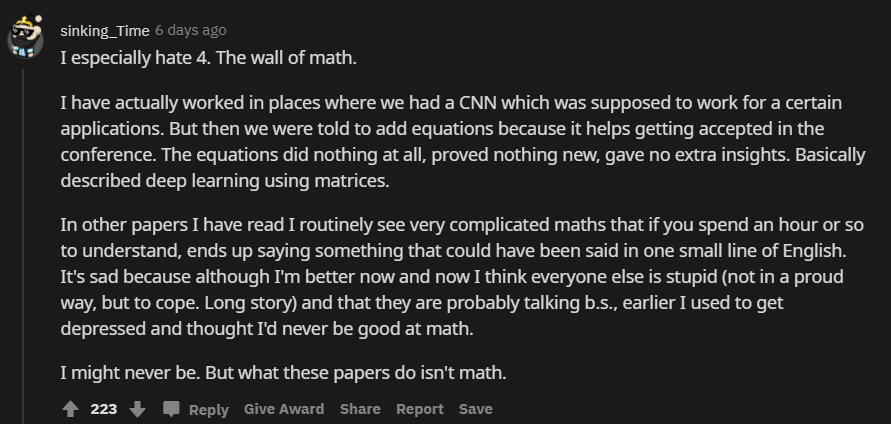
为什么会出现这种情况?有人猜测说,一个不太专业的审稿人可能会拒绝自己看不懂的想法,因为 ta 不喜欢这个想法。但在看到「数学墙」之后,ta 可能会给出更加严谨的审稿结果,如「弱接收(Weak Accept)」或「弱拒稿(Weak Reject)」。
作者还发现,有些研究者在提出一个超越其他研究的新基准之后,并不会进行更多后续研究来进一步发展该研究提出的技术方法。但在其他领域,研究团队中的一些成员后续会花费大量时间和精力去完善该研究所提出的方法,有些研究甚至会贯穿某些研究者的职业生涯。上述几个问题使得机器学习社区在某种程度上成为一个「回声室」,研究者只是将大量已知的研究结果重新编排,并用其问题的新颖性来掩饰创新的缺失。然而这些论文都能被接收,因为很少有人能发现这些研究是缺乏新颖性的。综合以上问题,这位来自传统行业的作者最后表示:「机器学习社区就像一棵自动接收论文的摇钱树。」一位来自物理学领域的研究者表示:「理论物理学等硬科学中也存在一些类似问题。『(论文)不发表就会被埋没(Publish or Perish)』的观念根深蒂固,以至于没有人理智地尝试解决一些实际且有意义的问题。」
这位理论物理学家还指出,不仅研究方向有所偏颇,发表论文的周期也在变短,研究质量因此降低。发表论文量成为了一种评价标准,很少有研究者潜心解决科学难题了。
此外,有人表示:「有些 ML 研究者似乎并不了解性能提升的根本原因,他们只是做了一些简单的改进。」这也是一件令人沮丧的事情。尽管这些问题只代表原帖作者和部分机器学习从业者的看法,但这不失为机器学习社区的一种缩影,有待解决与改善。参考链接:https://www.reddit.com/r/MachineLearning/comments/lvwt3l/d_some_interesting_observations_about_machine/
老铁,三连支持一下,好吗?↓↓↓
 下载APP
下载APP