
PaddleSlim重磅开源SlimX系列小模型,覆盖人脸识别、检测、分类和OCR
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达
模型小型化,why?
AI 服务的计算环境发生了翻天覆地的变化,已逐渐从云端向移动端和 IoT 蔓延渗透。据统计,近几年 AIoT 的市场规模以40%以上的实际速度在增长,而且预期未来几年还保持着一个相当高的增长趋势。与此同时,也带来了前所未有的新型交互需求。比如,在智能屏音箱上,不方便语音的时候使用手势控制;看视频时,在耗电量微乎其微的情况下,可以通过表情识别,为你喜欢的视频自动点赞。

然而,一个反差是,硬件的计算能力,从云到移动端、到 IoT,算力以三个数量级的比例在下降,内存也在大幅下降,尤其是边缘芯片内存只有 100K。而实际需要运行在这些 AIoT 设备上的算法需要关注的三个方面,即:算法效果(精度)、计算速度(FLOPs)、模型大小。最理想的选择是算法效果好、计算量低,尤其是实际耗时要少,同时,模型要小到内存足够放得下。
而云端上的经验告诉我们,要想效果好,模型得足够大!
那怎么样解决这个矛盾呢?很多专家提供人工经验去设计端上的模型,并且得到了广泛的应用。
如何利用现存优秀的云端模型。
如何产生任务自适应的模型。

▲ 图2 PaddleSlim-效果不降的模型压缩工具箱
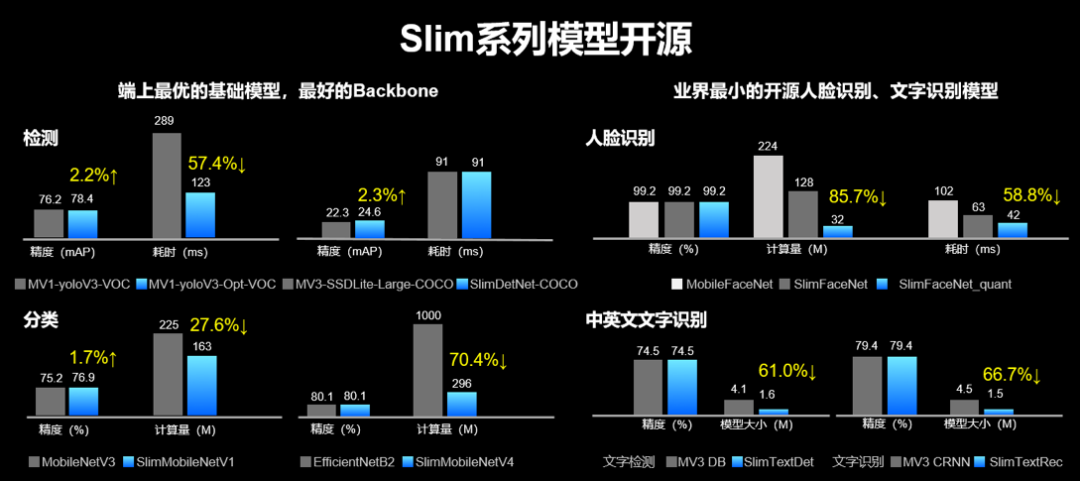
我们的最新成果
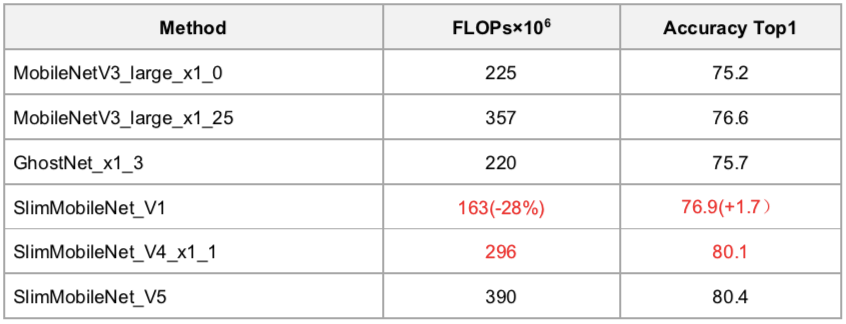
分类:CVPR 冠军模型,业界首个开源的 FLOPs 不超 300M、ImageNet 精度超过80%的分类小模型。
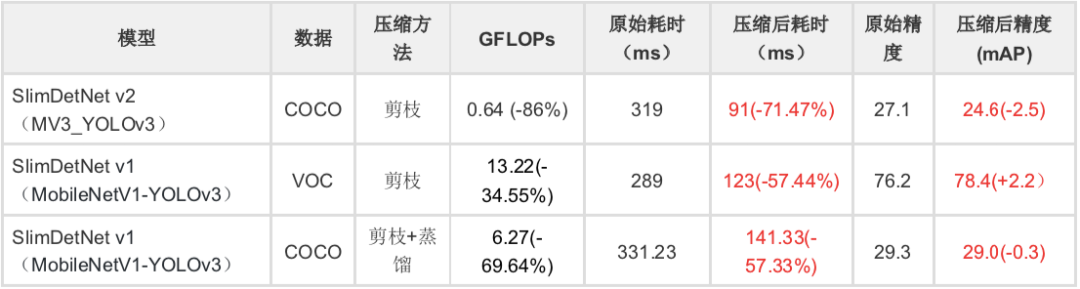
检测:最适合端侧部署的基于
PaddleDetection 的产业级检测模型
注:SlimDetNet v2(MV3_YOLOv3)输入大小为320,测试环境是骁龙845;SlimDetNet v1(MobileNetV1-YOLOv3)输入大小为608,测试环境是骁龙855。
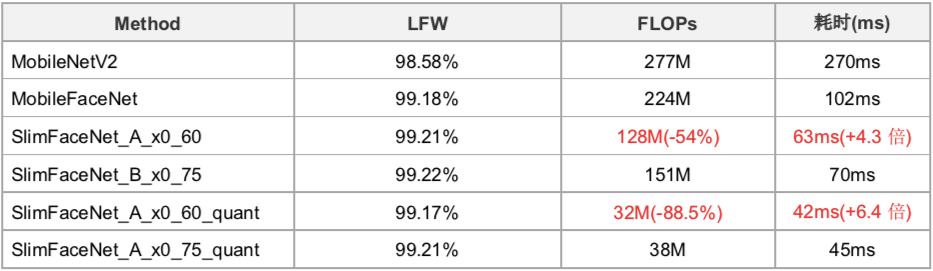
业界最小的开源人脸识别模型
业界最小的开源文字识别模型
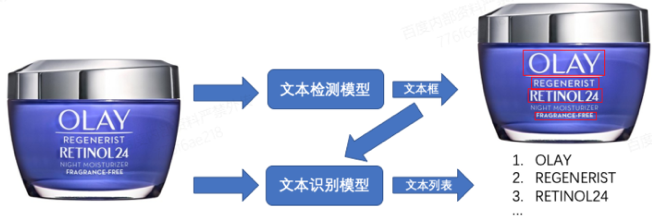
▲ 图4 OCR 识别工作流程
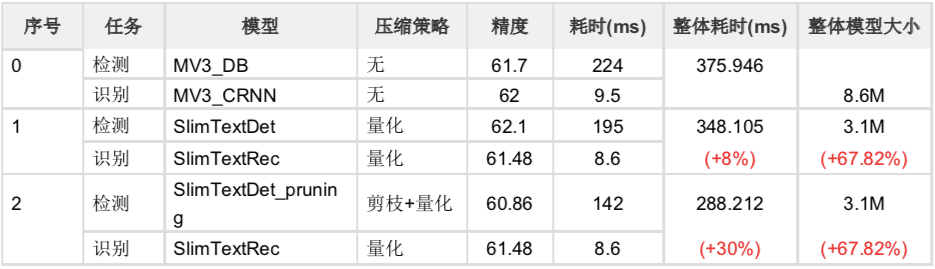
▲ 表4 SlimText系列小模型
我们是如何做到的
搜索压缩策略简介
基于自监督的 Oneshot-NAS 超网络训练方法
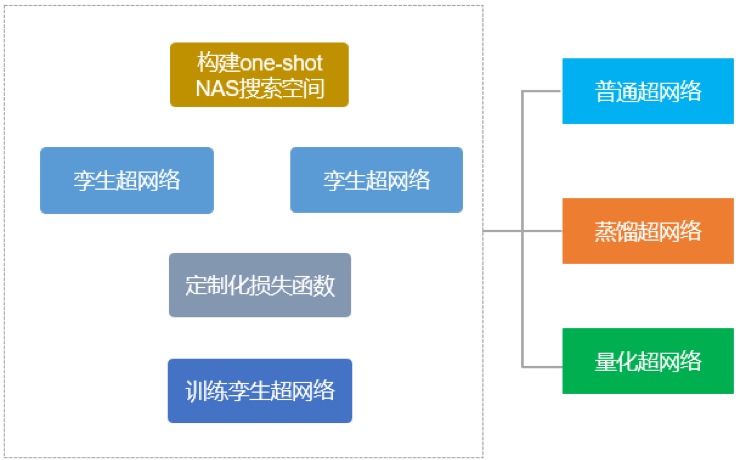
▲ 图5 基于自监督的超网络训练
基于高斯过程的模型结构自动搜索 GP-NAS
GP-NAS 论文地址:
https://openaccess.thecvf.com/content_CVPR_2020/papers/Li_GP-NAS_Gaussian_Process_Based_Neural_Architecture_Search_CVPR_2020_paper.pdf
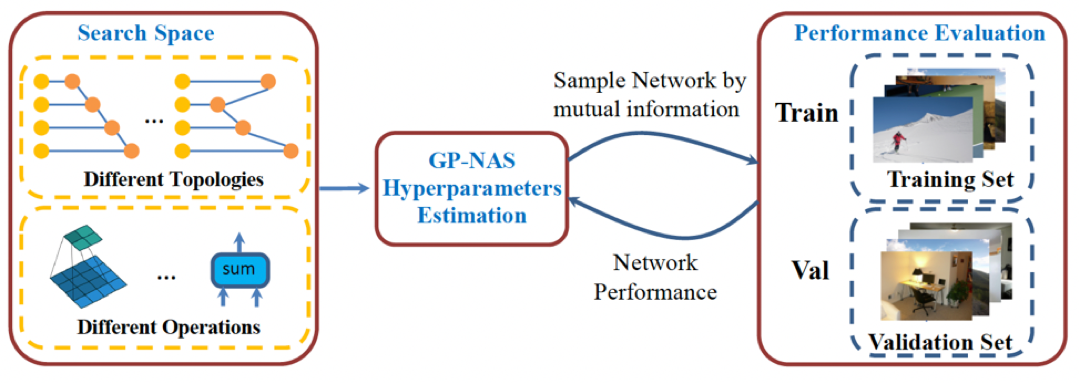
▲ 图6 基于高斯过程的模型结构自动搜索 GP-NAS
量化、剪枝、蒸馏
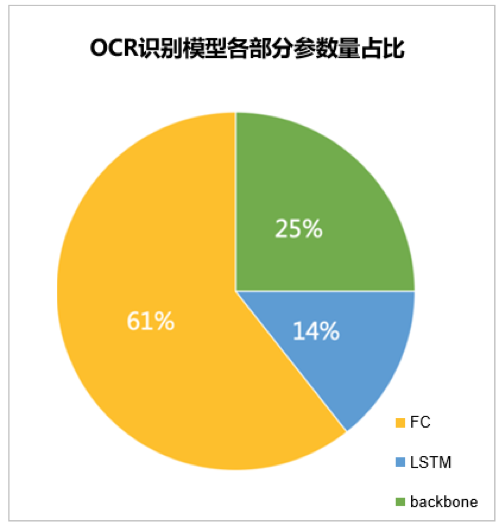
▲ 图7 OCR识别模型各部分参数量占比
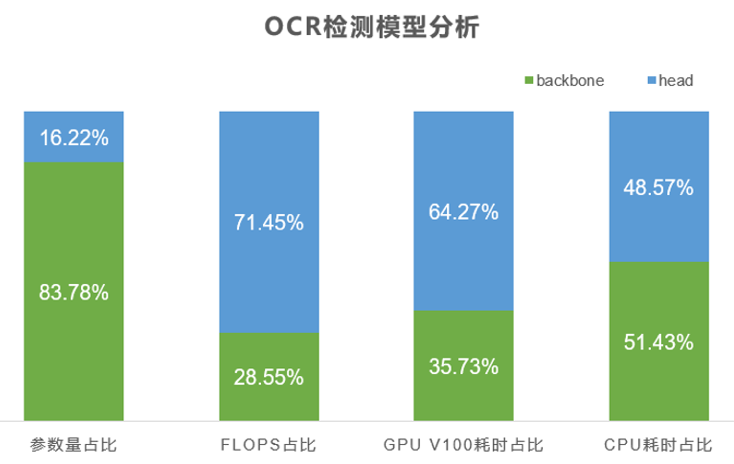
▲ 图8 OCR 检测模型分析
根据第一步的分析,我们制定以下压缩方案:
OCR 识别模型:对 backbone 和 FC 层进行 PACT 量化训练。 OCR 检测模型:对 head 部分先进行剪枝,然后再进行 PACT 量化训练。
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/demo/quant/pact_quant_aware
https://github.com/PaddlePaddle/PaddleSlim/blob/develop/docs/zh_cn/tutorials/image_classification_sensitivity_analysis_tutorial.md
https://aistudio.baidu.com/aistudio/projectdetail/898523
参考链接
https://aistudio.baidu.com/aistudio/projectdetail/898523
https://github.com/PaddlePaddle/PaddleSlim
https://github.com/PaddlePaddle/PaddleSlim