
OCR文字检测与识别
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
作者|Gidi Shperber 编译|AI公园
导读
OCR中的研究,工具和挑战,都在这儿了。

介绍
我喜欢OCR(光学字符识别)。对我来说,它代表了数据科学,尤其是计算机视觉的真正挑战。这是一个现实世界的问题,它有很多方法,包括计算机视觉,pipeline调整,甚至一些自然语言处理。它也需要大量的工程设计。它概括了数据科学中的许多问题:破坏了强大的基准,过分强调方法的复杂性和“新颖性”,而不是关注现实世界的进步。
两年前,我发表了一篇关于OCR的文章。像我的大多数文章一样,这篇文章意在回顾这个领域的研究和实践,阐明你能做什么,不能做什么,如何做,为什么做,并提供实用的例子。
它的本质是,当时的深度学习OCR是好的,但还不够好。现在,OCR 要好得多。但还是不太好。
但是,考虑到深度学习领域的活力,在我看来,它需要一个更新,甚至是完全重写。就是这样。如果你来到这里,你可能对OCR感兴趣。你要么是一名学生,要么是一名想要研究这个领域的研究员,要么你有商业兴趣。不管怎样,这篇文章应该能让你跟上进度。
开始
首先,让我们理清我们的概念:
OCR - 光学字符识别。这是一个常见的术语,主要指文档上的结构化文本。
STR - 场景文本识别。大多指的是在野外场景中更具有挑战性的文本。为了简单起见,我们将它们都称为OCR。
如前所述,OCR描述了深度学习和一般数据科学领域的许多成就,但也面临着挑战。一方面,这是我们之前的巨大进步。同样是令人印象深刻的同比进步。然而,OCR仍然没有解决。
还有一些非常恼人的失败案例,原因各不相同,大部分都是源于标准深度学习的根本原因 —— 缺乏泛化、易受噪声影响等。因此,即使模型可以处理许多情况(不同的字体、方向、角度、曲线、背景),也有一些偏差是不能工作的(只要它们不是手动引入到训练集中):不流行的字体、符号、背景等等。

任意形状的文本 — 来自ICDAR 2019数据集
此外,还出现了一个伟大而有用的库Easy OCR:https://github.com/JaidedAI/EasyOCR,它的目标是使最先进的OCR方法在开源中易于访问和使用。作为额外的好处,这个库还解决了OCR中的多语言问题(目前包括大约80种语言和更多的语言)和模型的速度(仍处于早期阶段)。这个库并不完美,但它确实是一个很好的解决方案。稍后再详细介绍。
因此,废话不多说,让我们看一下OCR当前的状态。
值得注意的研究
一如既往,数据科学任务的边界被研究扩展,而实践在创新方面落后,但在稳健性方面领先。
在我之前的文章中,我回顾了3种方:
当时流行的经典计算机视觉方法
一般深度学习方法,检测和识别,效率高,易于使用。
特定的深度学习方法,如CRNN和STN能取得良好的结果,但“太新,不能信任”。
在这篇文章中,我们可以说,特定的深度学习方法已经成熟,并且在研究和实践中都占据主导地位。
任务
在上一篇文章中,我们使用了一些例子,它们在当前状态下看起来可能很简单:车牌识别,验证码识别等等。今天的模型更有效,我们可以讨论更困难的任务,例如:
解析截图
解析商业手册
数字媒体解析
街道文本检测
Pipeline
在OCR上应用标准的目标检测和分割方法后,方法开始变得更加具体,并针对文本属性:
文本是同构的,文本的每个子部分仍然是文本
文本可能在不同的层次上被检测到,字符,单词,句子,段落等。
因此,现代的OCR方法“隔离”特定的文本特征,并使用不同模型的“pipeline”来处理它们。
在这里,我们将专注于一个特定的设置,实际上是一个模型pipeline,除了视觉模型(特征提取器),还有一些更有用的组件:

Pipeline的图
Pipeline的第一个部分是文本检测。显然,如果要使用不同的部分的文本,在识别实际字符之前检测文本的位置可能是个好主意。这部分是与其他部分分开训练的。
Pipeline的第二个部分是可选的:转换层。它的目标是处理各种扭曲的文本,并将其转换为更“常规”的格式(参见pipeline图)。
第三部分是视觉特征提取器,它可以是你最喜欢的深度模型。
Pipeline的第四个部分是RNN,它的目的是学习重复的文本序列。
第五部分也就是最后一部分是CTC的损失。最近的文章用注意机制取代了它。
该pipeline除了检测部分外,大多是端到端训练,以减少复杂性。
Pipeline的问题
Pipeline中有不同的组件是很好的,但是它有一些缺点。每个组件都有它自己的偏差和超参数集,这导致了另一个层次的复杂性。
数据集
众所周知,所有好的数据科学工作的基础都是数据集,而在OCR中,数据集是至关重要的:选择的训练和测试数据集对结果有重要的影响。多年来,OCR任务在十几种不同的数据集中进行了磨砺。然而,它们中的大多数并没有包含超过几千张带标注的图像,这对于扩展来说似乎不够。另一方面,OCR任务是最容易使用合成数据的任务之一。
让我们看看有哪些重要的数据集可用:
“真实” 数据集
一些数据集利用了谷歌街景。这些数据集可以被划分为规则或不规则(扭曲的、有角度的、圆角的)文本。

SVHN — 街景编号,我们在上一篇文章的例子中使用过。
SVT — 街景文字,文字图像来自谷歌街景。
ICDAR (2003, 2013,2015, 2019) — 为ICDAR和竞赛创建的一些数据集,具有不同的重点。例如,2019年的数据集被称为“任意形状的文本”,这意味着,无论它变得多么不规则都有可能。
生成数据集
目前流行的合成数据集有两种,它们在大多数OCR工作中被使用。不一致的使用使得作品之间的比较具有挑战性。
MJ Synth — 包括相对简单的单词组成。数据集本身包括~9M的图像。
Synth text — 具有更复杂的机制,它在第一阶段应用分割和图像深度估计,然后在推断的表面上“种出”文本。数据集本身包含约5.5M的图像。

DALL-E — 这有点不确定,但是文本图像生成(可能还有OCR)的未来似乎更加趋向于无监督。

这些合成数据集还擅长生成不同的语言,甚至是比较难的语言,比如汉语、希伯来语和阿拉伯语。
度量
在讨论具体的研究论文之前,我们需要确定成功的标准。显然有不止一种选择。
首先,让我们考虑一下文本检测的方式,它可以使用标准的目标检测指标,如平均平均精度,甚至标准精度和召回。
现在到了有趣的部分:识别。有两个主要的指标:单词级别的准确性和字符级别的准确性。特定的任务可能需要更高的准确性(例如文本块的准确性)。目前最先进的方法在具有挑战性的数据集上显示了80%的准确性(我们将在后面讨论)。
字符级别本身用“归一化编辑距离”来封装,该距离度量单词之间相似字符的比例。
研究论文
在这篇文章中,我们关注的是最佳实践,而不是构想。我建议你去看看篇综述:https://arxiv.org/pdf/1811.04256.pdf,你会发现有很多方法让你很难做出选择。
场景文本识别的问题是什么?
这个工作名字很不一样,文章https://arxiv.org/abs/1904.01906本身也很出色。这是一种前瞻性的调研,内容有:
定义统一的训练和测试集(经过一些优化后)。
在数据集上测试基准的最佳实践。
对方法进行逻辑结构的整理,并“帮助”读者理解使用什么方法。
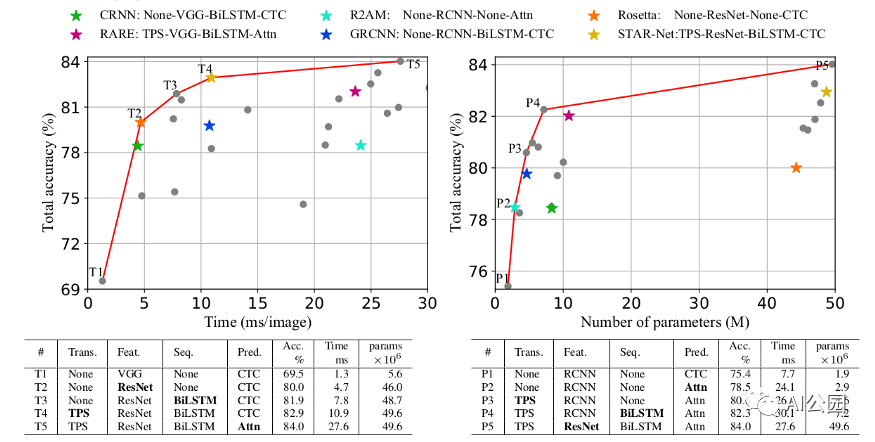
固定测试集上OCR pipeline的分类
所以本文的重点是:
对于OCR来说,训练数据集(可能被认为是“最好的”)是两个合成数据集:MJ和Synthtext。此外,重要的特征不是数量而是多样性(减少数据量不会对模型的性能造成太大的影响,但删除一个数据集却会造成太大的影响)
测试数据集约为5个真实世界数据集。
论文论证了随着每次pipeline的更新,结果逐渐改善。最显著的改进是从VGG到ResNet特征提取器的改动,精度从60%提高到80%。RNN和归一化的补充将模型推高到了83%。CTC到注意力更新增加了1%的准确性,但推理时间增加了三倍。

文本检测
在本文的大部分内容中,我们将讨论文本识别,但你可能还记得,pipeline的第一部分是文本检测。实现当前这一代的文本检测模型有点棘手。以前,文本检测作为目标检测的一个分支。然而,目标检测有一些设置是通用的目标,如汽车,人脸等。当引入文本检测时,需要进行一些重要的更新。
其实质是文本既具有同质性,又具有局部性。这意味着,一方面,文本的每个部分都是文本本身,另一方面,文本的子集应该统一到更大的类别上(如把字符统一为单词)。因此,基于分割的方法比基于目标检测的方法更适合于文本检测。
CRAFT
我们最喜欢的目标检测方法被称为CRAFT — Character Region Awareness for Text Detection,它也被集成到easy OCR中。该方法应用了一个简单的分割网络,很好地使用了真实图像和合成图像,以及字符级和单词级的标注。
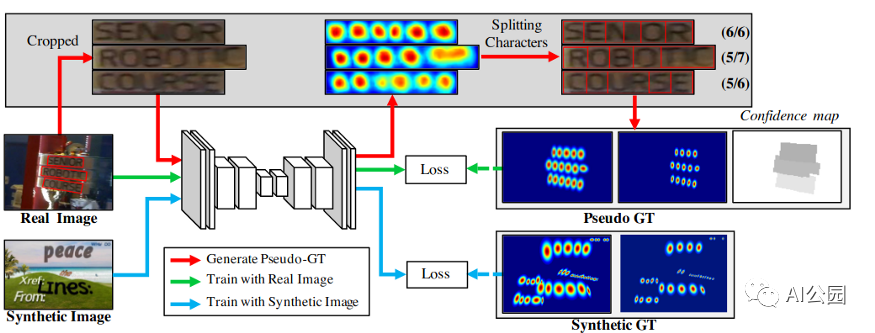
CRAFT模型概要
该模型在P和R上的h均值约为80%,在大多数数据集上也有很好的分词效果,使模型的识别更加容易。
实际的例子
我们已经到了实际应用的阶段。你应该用什么?所以我们已经在前面回答了这个问题(Easy OCR…),但是让我们查看一些流行的解决方案。
开源
需要注意的一件非常重要的事情是,尽管OCR受到学术界缺乏健壮性的影响,但它却享受着开源软件的繁荣,它允许研究人员和实践者在彼此的工作基础上进行构建。以前的开源工具(如Tesseract,见下文)在数据收集和从头开始的开发中遇到了困难。最近的库,比如Easy OCR,通过一组构建块,从数据生成到所有pipeline模型上可以有更多的调整。
工具
Tesseract
在很长一段时间里,Tesseract OCR是领先的开源OCR工具(不考虑偶尔与论文相关的库)。然而,这个工具是作为一个经典的计算机视觉工具构建的,并没有很好地过渡到深度学习。
APIs
OCR是大型云提供商谷歌、亚马逊和微软的一些早期计算机视觉API。这些API并不共享它们的能力基准,所以测试成为了我们的责任。
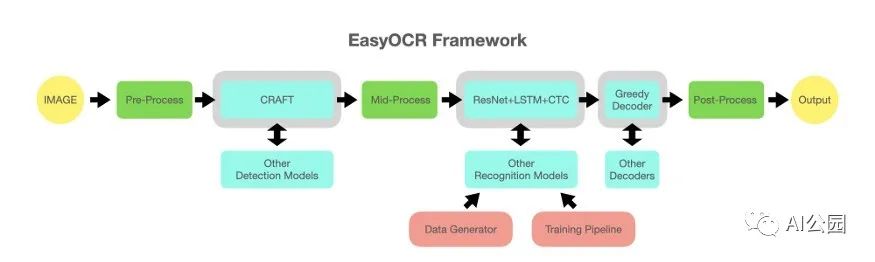
Easy OCR
在某种程度上,Easy OCR包是这篇文章的驱动。从不同的构建块构建一个开源的、最先进的工具的能力是很厉害的。
下面是它的工作原理:
使用MJ-Synth包生成数据。
用于检测的CRAFT模型(见上图)。
根据“what is wrong”的论文(见上文)训练一个调整后的pipeline,用于文本识别。
其他优化。
多语言:如上所述,OCR包含一些NLP元素。因此,处理不同的语言有不同之处,但我们也可以从工艺模型(可能还有其他检测模型)的多语言中受益。识别模型是特定于语言的,但训练过程是相同的。
最后一个问题是性能,这使得它在这个阶段成为“go to OCR tech” 。你可以从下面看到,它们甚至比付费API结果还要好。
在Easy OCR中需要改进的一点是调整能力:虽然语言选择很容易,但是可以根据不同的目的改变模型和再训练。在下一篇文章中,我们将展示如何做到这一点。
运行时间怎么样?
OCR的推断可能会很慢,这并不奇怪。检测模型是一个标准的深度学习模型,在GPU上运行约1秒(每张图像),而识别模型需要一遍又一遍的运行检测。在GPU上,一个包含许多目标的图像可能需要几十秒,更不用说CPU了。如果你想在你的手机或PC应用程序上运行OCR,使用较弱的硬件呢?
Easy OCR可以让你学到:首先,这个库引入了一些技巧,使推理更快(例如更紧凑的图像切片形状用于目标识别)。此外,由于是模块化的,你可以(目前需要一些代码调整)集成你自己的模型,这样就可以更小更快。
代码样例
因此,在讨论了不同的包和模型之后,是时候见证实际的结果了。这个notebook:https://colab.research.google.com/drive/1kNwHLmAtvwQjesqNZ9BenzRzXT9_S80W尝试了Easy OCR vs Google OCR vs Tesseract的对比,我选择了2张图像:


一种是常见的OCR case —— 来自文档的标准结构化文本,另一种是具有挑战性的书籍封面集合:多种字体、背景、朝向(不是很多)等等。
我们将尝试三种不同的方法:Easy OCR、Google OCR API(在大型技术云API中被认为是最好的)和古老的Tesseract。

在这类文本上,Tesseract和Google OCR的性能是完美的。这是有意义的,因为Google OCR可能在某种程度上基于Tesseract。
注意Google OCR对于这种文本有一个特殊的模式 — DOCUMENT_TEXT_DETECTION,应该用这个,而不是标准的TEXT_DETECTION。
Easy OCR的准确率约为95%。
有挑战的图像

左:Google OCR,右:Easy OCR
总体而言,Easy OCR效果最好。具体来说,检测部分捕获了大约80%的目标,包括非常具有挑战性的对角线目标。
Google OCR更糟,大约60%。
在识别方面,他们在字符级别上的识别率约为70%,这使得他们在单词或书的级别上识别率不高。看起来,Google OCR在单本书上没有100%正确的,而Easy OCR有一些可以。
我注意到的另外一件事是,Easy OCR在字符级别上表现更好,Google OCR在单词级别上更好 —— 这让我认为它可能在后台使用了字典。
英文原文:
https://towardsdatascience.com/ocr-101-all-you-need-to-know-e6a5c5d5875b
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
—THE END—