
重磅开源:超轻量3.5M中英文OCR模型!
导读
不得不说,2020年绝对是OCR开源界的丰收年,各种开源repo横空出世,一次又一次的刷新开源界的baseline,今天再次给大家种个草,介绍今年OCR开源领域 “真.良心之作”百度飞桨PaddleOCR。
先看下飞桨文字识别套件PaddleOCR自今年年中开源以来,短短几个月在GitHub上的表现:
7月,8.6M超轻量模型发布,GitHub Trending 全球日榜榜单第一!
8月,开源CVPR2020顶会SOTA算法,再上GitHub趋势榜单!
9月,GitHub Star数量已超过3.2K, 近期又带来哪些重磅更新?
果然,看9月最新更新,PaddleOCR再次诚意满满为大家带来真干货,直接看官方介绍:

数量上,这次PaddleOCR一口气发布了三个系列模型,满足移动端、服务器端各种场景需求。而且,多语言也妥妥安排上了,全部训练代码和模型毫无保留开源。其中3.5M超轻量文字识别模型,堪称目前业界开源的最轻量OCR模型了。
质量上,如此轻量的模型,效果有保障吗?不看广告,直接看疗效。先看几个常见的通用场景识别效果:



3.5M的模型能达到这个识别精度,绝对是良心之作了!再看一个非正常显示的图片:

文字倒着也能识别,没毛病(此处可以竖起大拇哥)。
想看更多效果?官方GitHub项目链接走起。
传送门:
Github:
https://github.com/PaddlePaddle/PaddleOCR
论文下载链接:
https://arxiv.org/abs/2009.09941
激动的心,颤抖的手,相信有OCR玩家要问:
有Demo可以动手玩一玩吗?
快速体验PaddleOCR的3.5M超轻量OCR模型
为了让用户快速上手,PaddleOCR也是做足了准备。
PC端快速尝试:(打开网页,选一张图片,即可实时看到结果)
链接地址:
https://www.paddlepaddle.org.cn/hub/scene/ocr
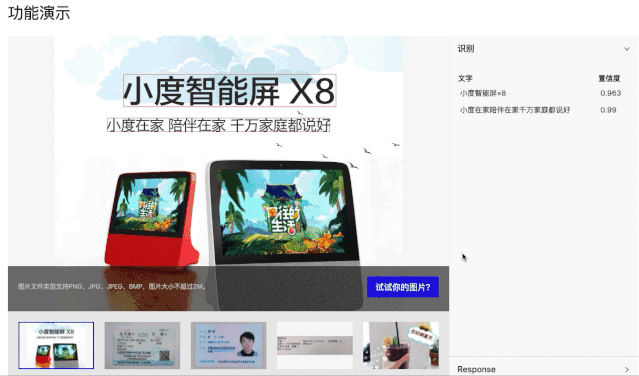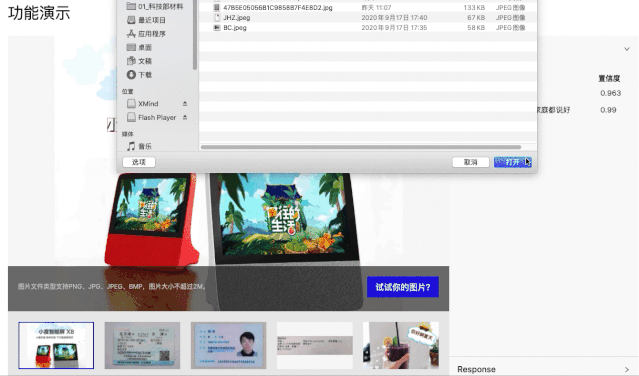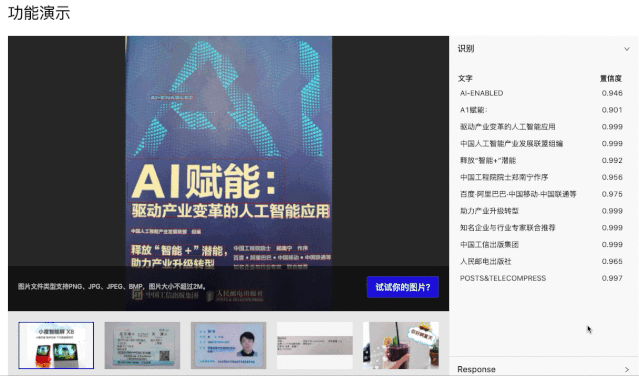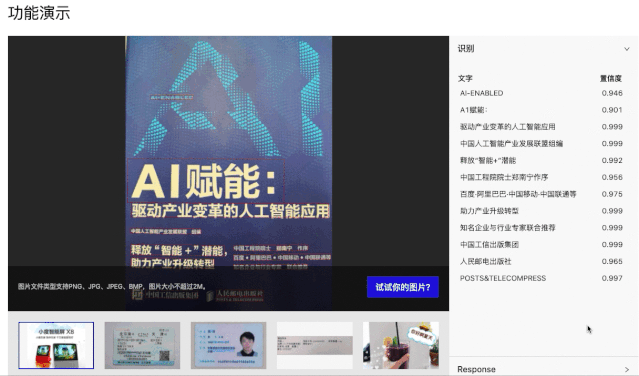
手机端App安装体验
PaddleOCR在百度大脑EasyEdge上开放了文字识别APP demo。安卓手机可直接扫码下载:
iOS版本由于证书限制,需要登录百度EasyEdge网页扫码体验:
https://ai.baidu.com/easyedge/app/openSource?from=paddlelite
效果如下:

通过PIP安装包快速体验PaddleOCR
pip安装
pip install paddleocr快速使用
from paddleocr import PaddleOCR, draw_ocrPaddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换,参数依次为
ch,en,french,german,korean,japan。
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
# 输入待识别图片路径
img_path = 'PaddleOCR/doc/imgs/11.jpg'
# 输出结果保存路径
result = ocr.ocr(img_path, cls=True)
更多内容,可以进入 https://github.com/PaddlePaddle/PaddleOCR 快速开始。
多个开源repo测试对比
对于OCR方向的开发者而言,开源repo最吸引人的莫过于:
①高质量的预训练模型
②简单易上手的训练代码
③好用无坑的部署能力
简单对比一下目前主流OCR方向开源repo的核心能力:
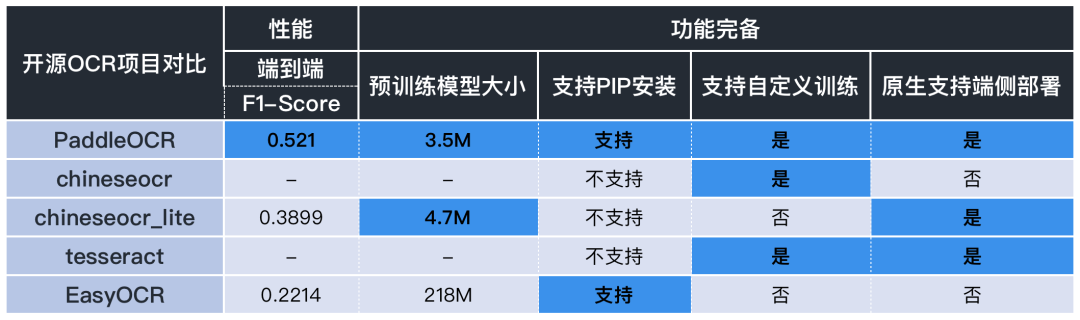
从性能指标来看:
针对OCR实际应用场景,包括合同,车牌,铭牌,火车票,化验单,表格,证书,街景文字,名片,数码显示屏等,收集的300张图像,每张图平均有17个文本框,PaddleOCR的F1-Score超过0.5,这个性能已经很不错了。
从功能完备来看:
预训练模型大小:easyOCR目前暂无超轻量模型,chineseocr_lite最新的模型是4.7M左右,而PaddleOCR提供的3.5M无疑是目前业界已知最轻量的。
PIP安装:目前仅PaddleOCR和easyOCR支持。
自定义训练:实际业务场景中,预训练模型往往不能满足需求,对于自定义训练和模型Finetuning,目前只有PaddleOCR支持。
部署方面:easyOCR模型较大不适合端侧部署,Chineseocr_lite和PaddleOCR都具备端侧部署能力。
开发者可以根据自己的实际需求,选择适合自己的开源方案。
对于PaddleOCR 3.5MB的超轻量模型,是如何做到的,repo中也给出了解释。
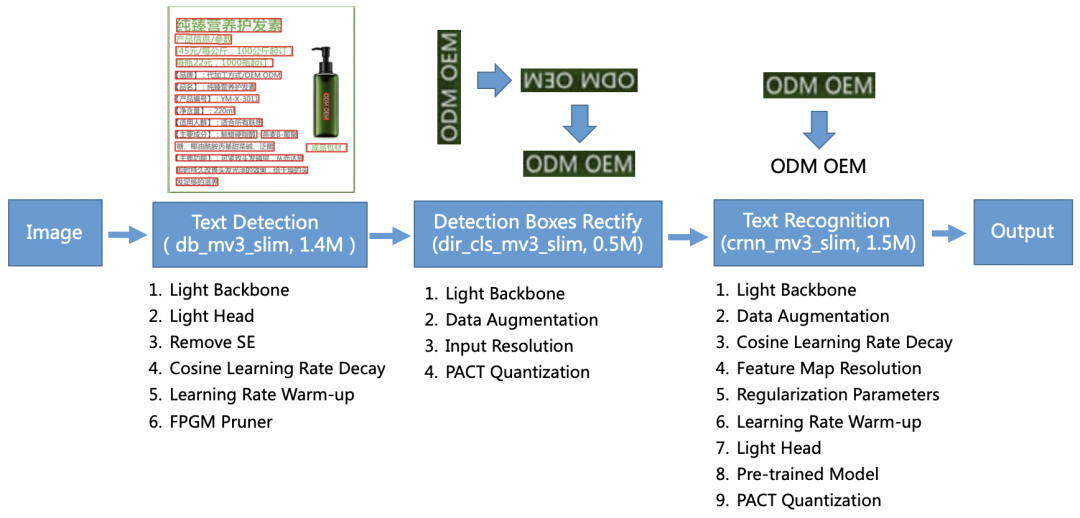
3.5M超轻量模型应用了一套超轻量OCR系统PP-OCR,主要由DB文本检测、检测框矫正和CRNN文本识别三部分组成。该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身,最终得到整体大小为3.5M的超轻量中英文OCR模型和2M的英文数字OCR模型。
更多细节请参考文末PP-OCR技术文章。
其中,飞桨模型压缩库PaddleSlim为PaddleOCR超轻量化模型的实现提供了核心的技术支撑。PaddleSlim集成了模型剪枝、量化(包括量化训练和离线量化)、蒸馏和神经网络搜索等多种业界常用且领先的模型压缩功能。通过PaddleSlim对PP-OCR中检测、检测框矫正和识别模型的压缩,从超轻量模型8.1M的压缩到3.5M,模型大小降低了56.79%,其中检测模型速度提升21%,而且整体模型精度还有一定提升。

更多惊喜
除了3.5M超轻量OCR模型,PaddleOCR还隐藏哪些惊喜,一睹为快:
本次开源的超轻量英文数字识别模型,不得不说,考虑的真周到,英文场景用起来更溜。

2、多语言支持,中、英、德、法、韩、日,据了解还在持续迭代更新并扩充中,欢迎体验。
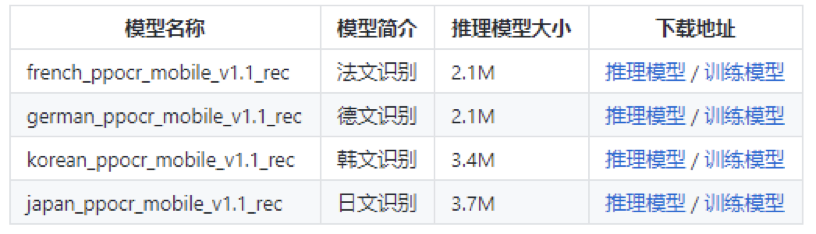
PaddleOCR也提供了多语言的识别模型配置文件如下图所示:
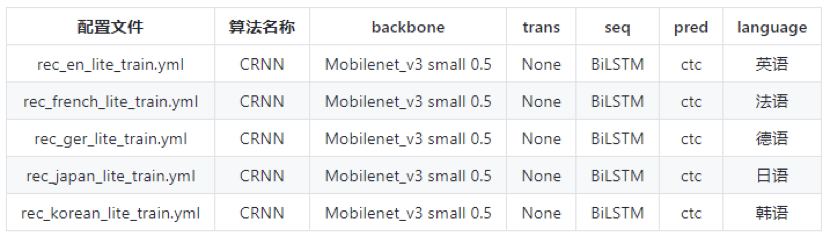
用户可以根据自己需求重新训练,也可以在预训练基础上调优。
3、文档教程,绝对是开源界的一股清流,对于OCR方向,能想到的内容,PaddleOCR应该都覆盖了吧。


其中的FAQ部分强烈推荐,面试OCR算法工程师岗位你应该用的到。
支持自定义训练,丰富部署能力
开发者如果想要使用自定义数据训练超轻量模型,也可以从PaddleOCR提供的基础算法库中选择适合自己的文本检测、识别算法,进行自定义的训练。自定义训练的存在让开发者可以使用自己的数据集打造更为契合自身需求的产品,极大程度满足了不同开发者的需求。
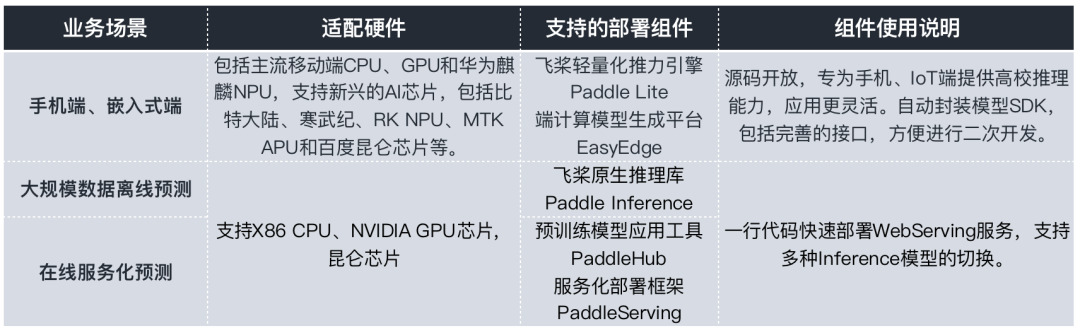
除了贴心的自定义训练,满足开发者产业级训练的需求之外,百度PaddleOCR为了更好的方便开发者和企业应用,打造了一系列的模型部署组件,可以支持开发者和企业在服务端、移动端、嵌入式硬件,云端服务化等多个不同的硬件平台部署,最大化地满足OCR文字识别领域的企业应用。
招募活动预告
9月26日,飞桨将举办OCR方向的线下沙龙活动,欢迎北京OCR方向的开发者们,我们相聚中关村。
(扫描海报中的二维码即可报名获取直播链接或现场门票)
更多飞桨的相关内容,请参阅以下内容。
官网地址:https://www.paddlepaddle.org.cn
飞桨PaddleOCR项目地址:GitHub: https://github.com/PaddlePaddle/PaddleOCR
Gitee: https://gitee.com/paddlepaddle/PaddleOCR飞桨PaddleSlim项目地址:GitHub: https://github.com/PaddlePaddle/PaddleSlim
Gitee: https://gitee.com/paddlepaddle/PaddleSlimPP-OCR技术文章:https://github.com/PaddlePaddle/PaddleOCR/raw/develop/doc/PPOCR.pdf