
5行Python就能爬取 3000+ 上市公司的信息?
入门爬虫很容易,几行代码就可以,可以说是学习 Python 最简单的途径。
刚开始动手写爬虫,你只需要关注最核心的部分,也就是先成功抓到数据,其他的诸如:下载速度、存储方式、代码条理性等先不管,这样的代码简短易懂、容易上手,能够增强信心。
基本环境配置
版本:Python3 系统:Windows 相关模块:pandas、csv
爬取目标网站
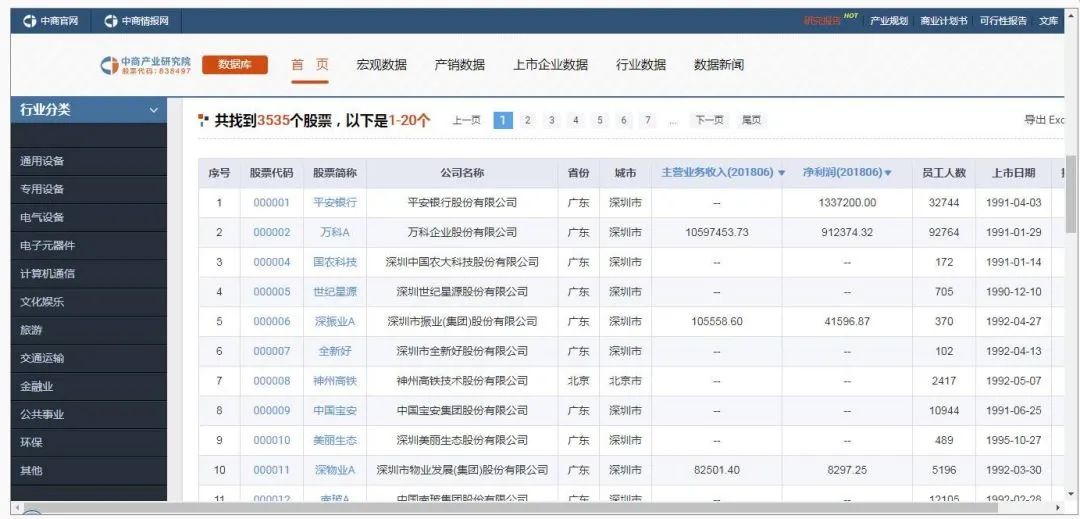
实现代码
import pandas as pd
import csv
for i in range(1,178): # 爬取全部页
tb = pd.read_html('http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum=%s' % (str(i)))[3]
tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)
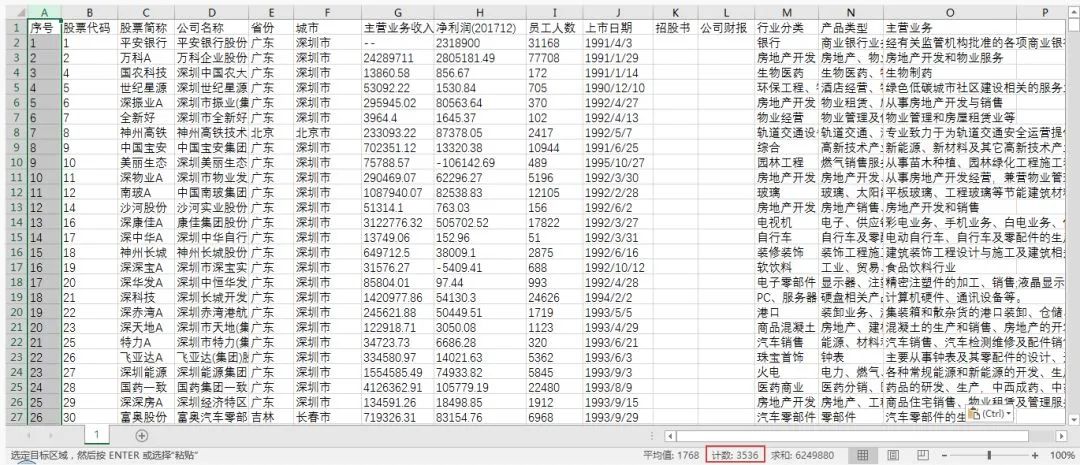
3000+ 上市公司的信息,安安静静地躺在 Excel 中:
有了上面的信心后,我开始继续完善代码,因为 5 行代码太单薄,功能也太简单,大致从以下几个方面进行了完善:
增加异常处理
由于爬取上百页的网页,中途很可能由于各种问题导致爬取失败,所以增加了 try except 、if 等语句,来处理可能出现的异常,让代码更健壮。
增加代码灵活性
初版代码由于固定了 URL 参数,所以只能爬取固定的内容,但是人的想法是多变的,一会儿想爬这个一会儿可能又需要那个,所以可以通过修改 URL 请求参数,来增加代码灵活性,从而爬取更灵活的数据。
修改存储方式
初版代码我选择了存储到 Excel 这种最为熟悉简单的方式,人是一种惰性动物,很难离开自己的舒适区。但是为了学习新知识,所以我选择将数据存储到 MySQL 中,以便练习 MySQL 的使用。
加快爬取速度
初版代码使用了最简单的单进程爬取方式,爬取速度比较慢,考虑到网页数量比较大,所以修改为了多进程的爬取方式。
经过以上这几点的完善,代码量从原先的 5 行增加到了下面的几十行:
import requests
import pandas as pd
from bs4 import BeautifulSoup
from lxml import etree
import time
import pymysql
from sqlalchemy import create_engine
from urllib.parse import urlencode # 编码 URL 字符串
start_time = time.time() #计算程序运行时间
def get_one_page(i):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
paras = {
'reportTime': '2017-12-31',
#可以改报告日期,比如2018-6-30获得的就是该季度的信息
'pageNum': i #页码
}
url = 'http://s.askci.com/stock/a/?' + urlencode(paras)
response = requests.get(url,headers = headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('爬取失败')
def parse_one_page(html):
soup = BeautifulSoup(html,'lxml')
content = soup.select('#myTable04')[0] #[0]将返回的list改为bs4类型
tbl = pd.read_html(content.prettify(),header = 0)[0]
# prettify()优化代码,[0]从pd.read_html返回的list中提取出DataFrame
tbl.rename(columns = {'序号':'serial_number', '股票代码':'stock_code', '股票简称':'stock_abbre', '公司名称':'company_name', '省份':'province', '城市':'city', '主营业务收入(201712)':'main_bussiness_income', '净利润(201712)':'net_profit', '员工人数':'employees', '上市日期':'listing_date', '招股书':'zhaogushu', '公司财报':'financial_report', '行业分类':'industry_classification', '产品类型':'industry_type', '主营业务':'main_business'},inplace = True)
return tbl
def generate_mysql():
conn = pymysql.connect(
host='localhost',
user='root',
password='',
port=3306,
charset = 'utf8',
db = 'wade')
cursor = conn.cursor()
sql = 'CREATE TABLE IF NOT EXISTS listed_company (serial_number INT(20) NOT NULL,stock_code INT(20) ,stock_abbre VARCHAR(20) ,company_name VARCHAR(20) ,province VARCHAR(20) ,city VARCHAR(20) ,main_bussiness_income VARCHAR(20) ,net_profit VARCHAR(20) ,employees INT(20) ,listing_date DATETIME(0) ,zhaogushu VARCHAR(20) ,financial_report VARCHAR(20) , industry_classification VARCHAR(20) ,industry_type VARCHAR(100) ,main_business VARCHAR(200) ,PRIMARY KEY (serial_number))'
cursor.execute(sql)
conn.close()
def write_to_sql(tbl, db = 'wade'):
engine = create_engine('mysql+pymysql://root:@localhost:3306/{0}?charset=utf8'.format(db))
try:
tbl.to_sql('listed_company2',con = engine,if_exists='append',index=False)
# append表示在原有表基础上增加,但该表要有表头
except Exception as e:
print(e)
def main(page):
generate_mysql()
for i in range(1,page):
html = get_one_page(i)
tbl = parse_one_page(html)
write_to_sql(tbl)
# # 单进程
if __name__ == '__main__':
main(178)
endtime = time.time()-start_time
print('程序运行了%.2f秒' %endtime)
# 多进程
from multiprocessing import Pool
if __name__ == '__main__':
pool = Pool(4)
pool.map(main, [i for i in range(1,178)]) #共有178页
endtime = time.time()-start_time
print('程序运行了%.2f秒' %(time.time()-start_time))
结语
这个过程觉得很自然,因为每次修改都是针对一个小点,一点点去学,搞懂后添加进来,而如果让你上来就直接写出这几十行的代码,你很可能就放弃了。
所以,你可以看到,入门爬虫是有套路的,最重要的是给自己信心。
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对小编的支持。
恋习Python 关注恋习Python,Python都好练
好文章,我在看❤️
评论