
全球首个开源图像识别系统上线了!人脸、商品、车辆识别一网打尽!
大家好,我是老表,你知道人脸、商品、车辆识别,以图搜图乃至自动驾驶,背后的技术是什么嘛?今天给大家来唠唠嗑,分享下前沿技术和应用。
起初老表觉得不就是图像分类、目标检测这些东西嘛,还能比人肉眼厉害?有什么难的?但能现实是我拿着几千的工资,而熟练这些应用的BAT高级工程师们都已经轻松年薪百万,笑傲人生了!!!
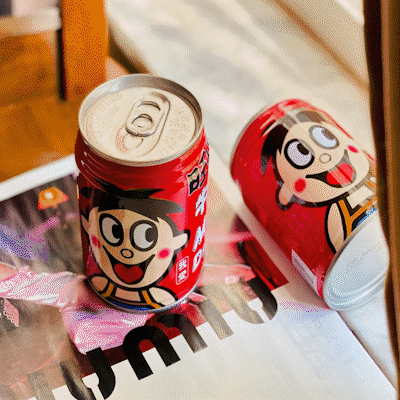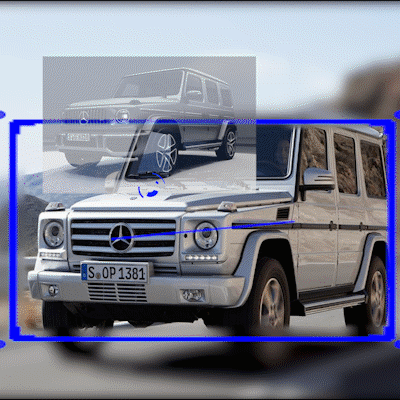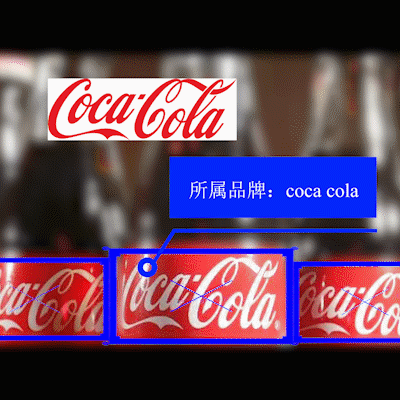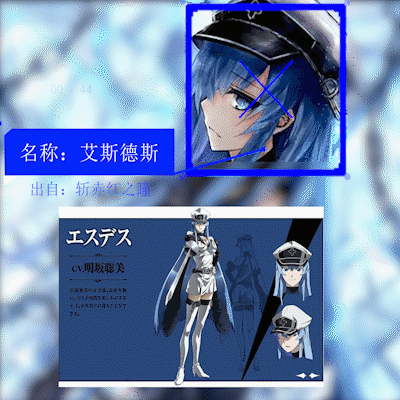
当老表正在酸成柠檬精的时候,BAT大神幽幽的说:这背后是综合使用目标检测、图像分类、度量学习、图像检索的【通用图像识别系统】…

度量学习是啥?图像检索是啥?通用图像识别系统又是啥?!看来还是我Too Simple,Too Naive了…
难道我真的就无缘年薪百万了嘛?!正在老表捶胸顿足的时候,老表突然发现了一个通用图像识别系统快速搭建神器— PP-ShiTu!OMG!这不梦想一下就要实现了嘛!
赶紧Star收藏:
https://github.com/PaddlePaddle/PaddleClas
那这个项目到底有什么过人之处,图像识别又比图像分类、目标检测强在哪里呢?
拿[商品识别]举个栗子,如果你用单纯的图像分类和目标检测,你会发现:
商品类别数以万计:根本没法事先把所有类别都放入训练集!训练集都不完备怎么训练算法?

样本差别极小,区分难度极大:细分类差别极其细微,实际图像的拍摄角度也多变刁钻,识别准确率非常非常低。

产业上线速度要求极高:每张复杂的图片处理速度要求在毫秒级别,在闸机前让你等个3秒绝对要炸锅!

而这个PP-ShiTu图像识别系统就可以完美解决以上问题!
准备好需要识别的物体图片后,只需三步,多类别、微差异、高速度等问题通通不再是问题,绝对的 “开箱即用”,而且它不仅可以用作商品识别,还可以进行车辆、人脸、Logo、行人识别!!!
第一步通过目标检测模型,进行主体检测;
第二步对每个候选区域进行特征提取;
第三步将特征提取后的向量在检索库中进行检索,完成匹配,返回识别结果。
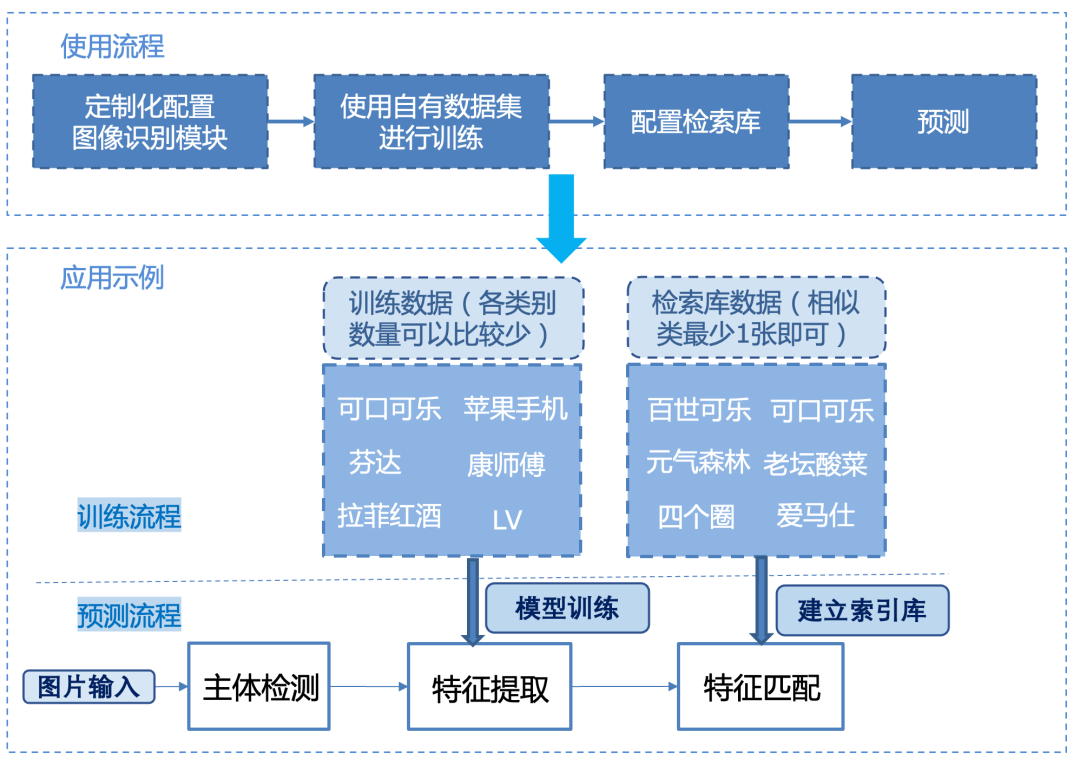
PP-ShiTu使用流程示例
而这个图像识别系统的4个核心构成模块,都是经过精心打磨。无论是单独使用亦或是串联开发,都有非凡的效果:
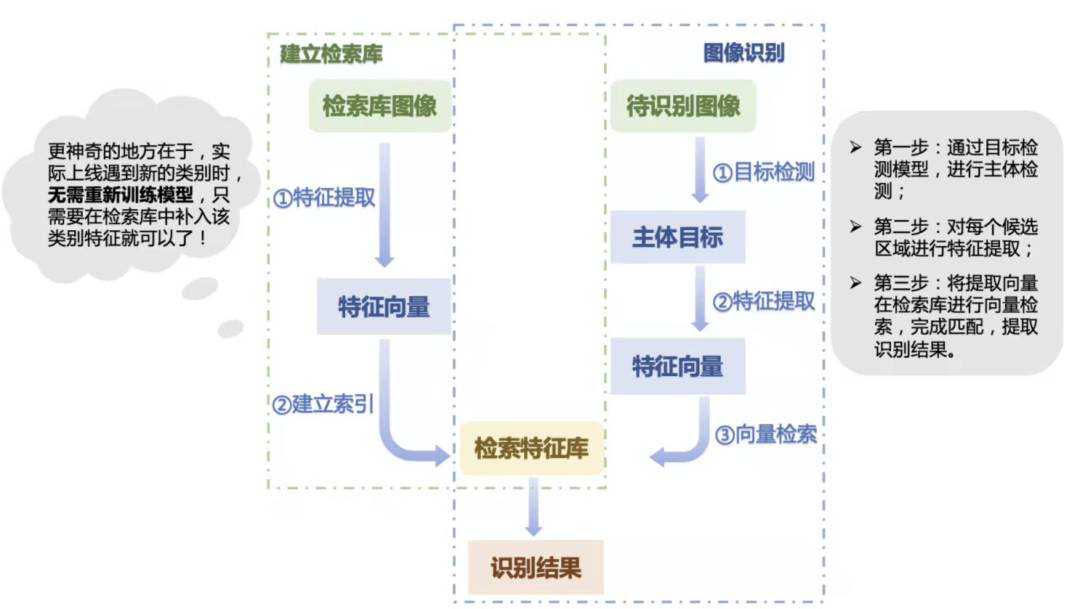
PP-ShiTu架构图
主体检测:采用高精度超轻量的PP-PicoDet检测算法,它的出现,使PP-ShiTu的主体检测模块预测速度提升了15倍以上,而精度几乎不衰减。
骨干网络:采用CPU级超高性价比的轻量化骨干网络PP-LCNet,它的准确率不仅超越大模型ResNet50的模型效果,预测速度还是后者的3倍!简直香个跟头!而PP-ShiTu充分挖掘该网络的潜力,学习一个具有超强泛化能力的特征提取模型,同一模型可在多个数据集上同时实现高精度识别。
度量学习:集成ArcMargin度量学习方法,轻松将图像转换成特征向量,训练出鲁棒的图像特征,以供后续进行检索识别。
检索系统:集成Faiss算法,高效完成向量检索。当增加新的品类时,不需要重新训练提取特征模型,仅需要更新检索库即可识别新的目标,一次训练长期使用,还兼容(Linux, Windows, MacOS)多平台。
开发者不仅可以单独或自主组装使用这四个模块,还可以直接采用构建好的车辆识别、LOGO识别、商品识别、动漫识别四个系统。只需要补充好检索库,就可以直接投产使用了!

有了它们的助力,看齐大厂程序员,年薪百万不是梦!(逐渐露出暴富的笑容~ )
这么强大、用心的项目 ,你还在等什么?!还不赶紧Star🌟收藏上车吧!
传送门:
https://github.com/PaddlePaddle/PaddleClas
快速体验:
https://github.com/PaddlePaddle/PaddleClas/blob/release/2.3/docs/zh_CN/quick_start/quick_start_recognition.md
直播预告
精彩内容抢先看!长按收藏海报~

