
Diffusion Models 10 篇必读论文(1)DDPMN
【导语】Diffusion Models 是近期人工智能领域最火的方向,也衍生了很多实用的技术。最近开始整理了几篇相关的经典论文,加上一些自己的理解和公式推导,分享出来和大家一起学习,欢迎讨论:702864842(QQ),https://github.com/Huangdebo。
第 1 篇:《Denoising Diffusion Probabilistic Models》
摘要
前一篇介绍了 diffusion model 的设计灵感和主要的思想。这篇沿用了之前的想法,用一个马尔科夫链来构成一个生成模型,训练是是把原始分布逐步扩散到一个噪声分布,然后学习其逆扩散的过程。不同的是此处把模型的逆扩散过程更加形象地看成是去噪过程(DDPM),并优化了训练目标,使得训练和生成过程更加清晰简洁,后面很多论文都是基于这篇论文优化发展的。
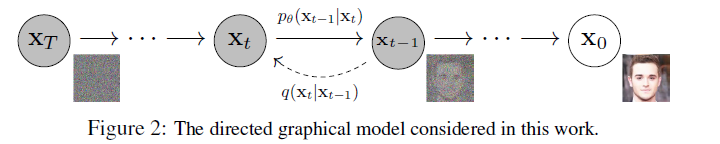
模型生成可以看成是去噪过程
1、背景回顾
1、 扩散(diffusion)
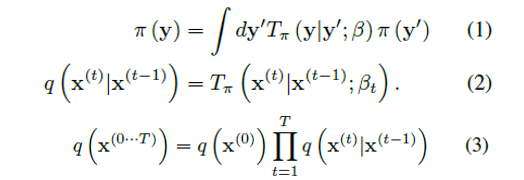
扩散过程
(1) 每一步的新数据都是由上这次的扩散核作用在上一次数据上产生的,(2)扩散核,也就是扩散过程的规则,(3)最终的联合分布。
1.2 反向传播
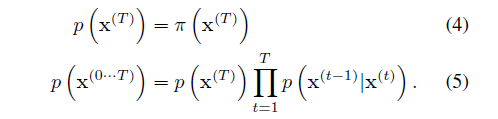
方向传播
在扩散率 β 很小的情况下,可以把正向扩散和反向传播的每一步都可以看成是同一种形式(比如高斯扩散)。而这个反向传播中高斯扩散的均值和方差便可以作为参数进行训练。
2、 模型具体特性
2.1 扩散过程
扩散过程是一个马尔科夫高斯扩散,每个时刻的分布只和前一个分布和扩散核有关:
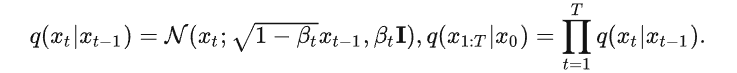
正向扩散过程
设 αt = 1 - βt,则:
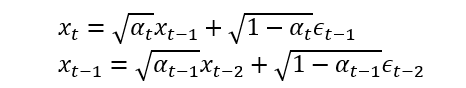
x/x-1
将以上两个式子联立,带入,可以得到:
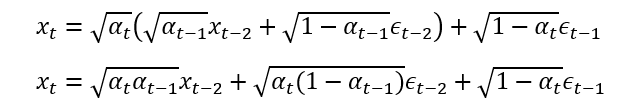
xt
两个独立同分布的高斯分布相加之后有以下公式:
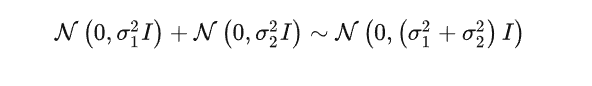
高斯合并特性
最终可以简化并推导可得:

简化结果
2.2 逆扩散过程
q(xt|xt-1) 为扩散的过程,则 q(xt-1|xt) 为理想的逆扩散过程,利用贝叶斯可求解,而且当 β 足够小时候,逆扩散扩展可以看成和扩散过程一样的高斯扩散形式:
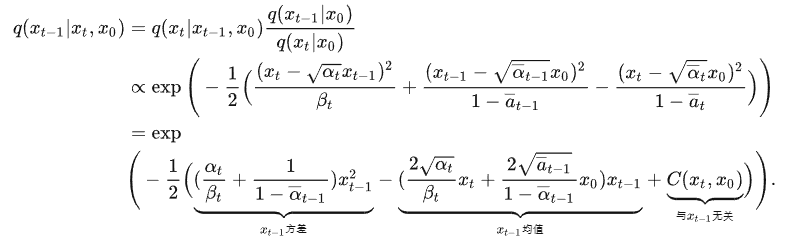
逆扩散
标准正态分布的展开为:
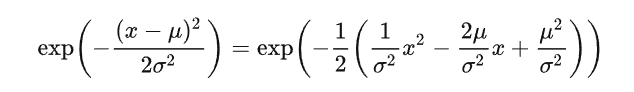
标准高斯分布
对比上面两式子可得:
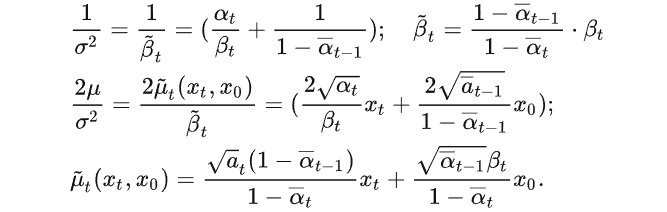
方差和均值
根据 2.1 的扩散特性可消掉 x0,得
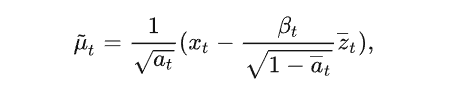
消掉x0
最终得到 q(xt|xt-1) 的表达形式(其中的噪声则是正向扩散时添加的噪声):

q的最终表达式
3、 优化目标
此模型采用了最大化对数似然(交叉熵)来进行优化训练:
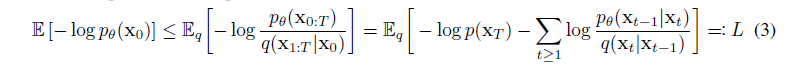
优化目标
经过一些骚作后转化成:
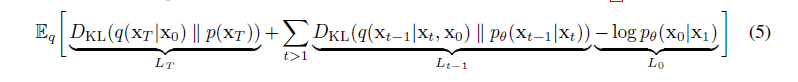
优化目标转化
-
Lt 在训练中是确定的常数,所以可以忽略
-
L0 根据图像的取值范围和归一化范围设定成
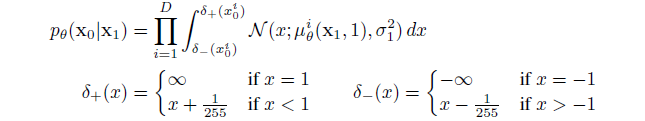
L0
-
设q(xt|xt-1) 为扩散的过程,则 p(xt-1|xt) 都为同形式的高斯生成过程:

逆扩散和生成
其中的 p(xt-1|xt) 中的方差 σ 可以取 2.2 (2)中 β,也可以取值波浪β,结果差别不大,根据两个高斯分布的KL散度公式可得
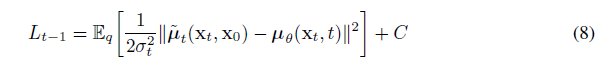
Lt-1
根据 2.2 的 (1)得
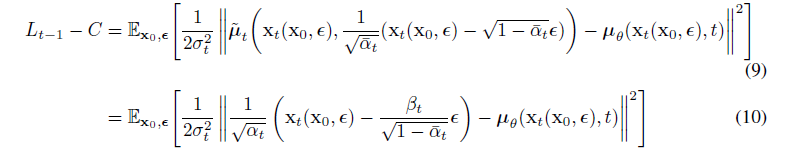
Lt-1 - C
所以最小化 Lt-1 则是让 μθ 来预测
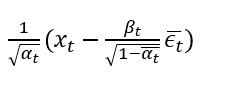
用 u 来预测 Lt-1
所以
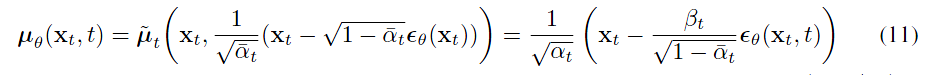
uθ
其中的Eθ 便是用神经网络来根据xt 预测出来的噪声,则取样结果为(z是标准正态分布,加上 σz 是为了把方差转变成 σ):
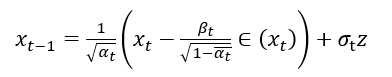
xt-1
然后模型最终的优化目标可以简化成:
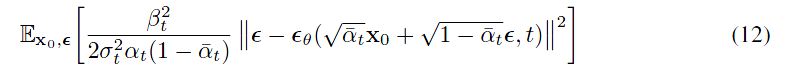
最终的优化目标
但在训练中发现,去掉其中的系数能简化训练:
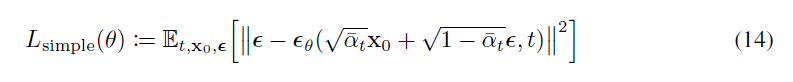
简化后的优化目标
算法流程

算法流程
4.1 训练过程
不断取样本x0~q(x0)和一个随机正态分布的噪声E,利用1~T 步中由神经网络输出的噪声和E计算误差来训练,直到网络收敛。神经网络的输入则是扩散过程中每一步扩散得到的 xt。
4.2 生成过程
训练中计算的 1~T 步中扩散的 方差 p(xt-1|xt) 中的方差 σ^2 ,然后先生成一个随机高斯噪声,再逐步利用训练得到的噪声E和方差,使用第4 步的式子来计算。在 x1->x0时,z 则取值为0。
结论
这篇文章把模型的逆扩散过程更加形象地看成是去噪过程(DDPM),并优化了训练目标,使得训练和生成过程更加清晰简洁,使得模型能生成质量更高的图像。由于在图像数据上出色的inductive biases, diffusion model 后续的在生成模型的发展上大放异彩,甚至超越了 GANs.