
ICCV 2023 | 图像分割类扩散模型diffusion的 8 篇论文
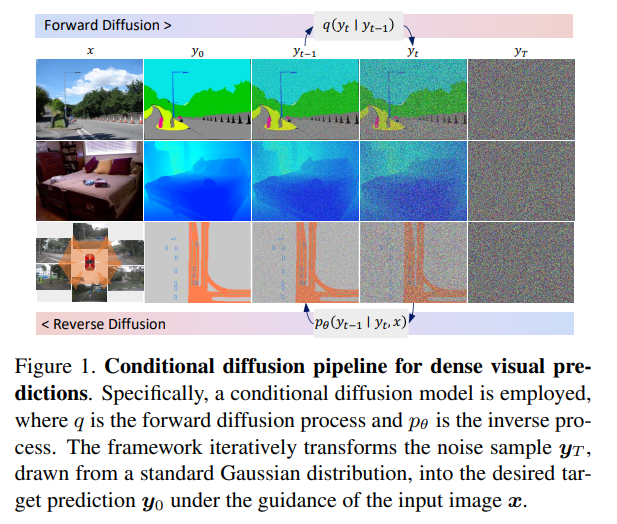
提出一种简单、高效但功能强大的基于条件扩散流程(density visual predictions)的框架。方法采用“噪声到分割图”(noise-to-map)的生成范式进行预测,通过逐步从随机高斯分布中去除噪声来引导图像生成。这种方法称为DDP,无需特定于任务的设计和架构定制,易于推广到大多数密集预测任务,例如语义分割和深度估计。
DDP在六个不同的基准任务上展示了三个代表性任务的顶级结果。例如,语义分割在Cityscapes上的mIoU达到83.9,BEV地图分割在nuScenes上的mIoU达到70.6,深度估计在KITTI上的REL达到0.05。https://github.com/JiYuanFeng/DDP
2、Unleashing Text-to-Image Diffusion Models for Visual Perception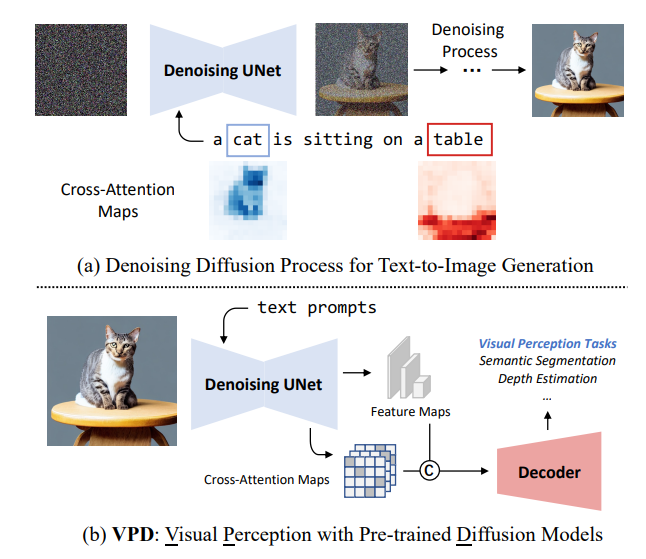
本文提出VPD(视觉感知与预训练的扩散模型),利用预训练的文本到图像扩散模型,在视觉感知任务中利用语义信息。不使用扩散预训练去噪自编码器,而将其简单地用作主干,并旨在研究如何充分利用所学知识。
用适当的文本输入提示去噪解码器,并通过适配器改进文本特征,从而更好地与预训练阶段对齐,并使视觉内容与文本提示进行交互。还提出利用视觉特征和文本特征之间的交叉注意力图来提供明确的引导。与其他预训练方法相比,展示了利用视觉语言预训练的扩散模型可以更快地适应基于视觉感知任务的提出的VPD的有效性。
对语义分割、引用图像分割和深度估计的广泛实验证明了方法的有效性。值得注意的是,VPD在NYUv2深度估计上达到了0.254的RMSE和RefCOCO-val引用图像分割上的73.3%的oIoU,创造了这两个基准的新纪录。已开源在:https://github.com/wl-zhao/VPD
3、Open-vocabulary Object Segmentation with Diffusion Models 本文的目标是从预训练文本到图像扩散模型中提取视觉语言对应关系,以分割图的形式,即同时生成图像和分割掩模,描述文本提示中相应的视觉实体。
本文的目标是从预训练文本到图像扩散模型中提取视觉语言对应关系,以分割图的形式,即同时生成图像和分割掩模,描述文本提示中相应的视觉实体。
(i)将现有的扩散模型与一种新的基于定位的模块配对,只需要少量目标类别的训练可以使扩散模型的视觉和文本嵌入空间对齐;(ii)建立一个自动的流水线来构建数据集,其中包含{图像、分割掩模、文本提示}三元组,以训练所提出的定位模块;(iii)评估从文本到图像扩散模型生成的图像上的开放词汇定位的性能,并展示了该模块可以很好地对训练时已见过的类别之外的类别的对象进行分割;(iv)采用增强的扩散模型构建了一个合成的语义分割数据集,并展示了在这样的数据集上训练标准分割模型在零样本分割(ZS3)基准测试中表现出有竞争力的性能,为采用强大的扩散模型用于判别任务开辟了新的机会。
已开源在:https://github.com/Lipurple/Grounded-Diffusion
4、Diffusion Action Segmentation
时间动作分割对于理解长事件视频至关重要。以往针对这个任务的作品通常采用迭代细化范式,使用多阶段模型。本文提出一种通过去噪扩散模型的新框架,然而它与这种迭代优化的本质精神是相同的。
根据输入视频特征,动作预测是从随机噪声中迭代生成。为增强对人类动作的三个显著特征建模,包括位置先验、边界模糊度和关系依赖性,为条件输入设计了统一的遮罩策略。对GTEA、50Salads和Breakfast三个基准数据集进行大量实验,方法在性能上达到了优于或与最先进方法可比的结果,显示了采用生成方法进行动作分割的有效性。已开源在:https://github.com/Finspire13/DiffAct
5、LD-ZNet: A Latent Diffusion Approach for Text-Based Image Segmentation
大规模的预训练任务,如图像分类、描述生成或自监督技术,并不鼓励学习对象的语义边界。然而,使用基于文本的潜在扩散技术构建的最新生成基础模型可能会学习语义边界。这是因为它们必须基于文本描述综合生成图像中所有对象的细节。因此,提出一种在互联网规模数据集上训练的潜在扩散模型(LDMs)来对实际图像和AI生成图像进行分割的技术。
首先表明LDMs的潜在空间(z空间)作为输入表示相对于其他特征表示如RGB图像或CLIP编码而言更好用于基于文本的图像分割。通过在潜在z空间上训练分割模型,该模型在各种形式的艺术、卡通、插图和照片等不同领域之间创建了压缩表示,也能够弥合实际图像和AI生成图像之间的领域差距。
展示了LDMs的内部特征包含丰富的语义信息,并提出LD-ZNet,进一步提高基于文本的分割的性能。总体而言,在自然图像的文本到图像分割上显示了超过标准基线的6%改进。对于AI生成的图像,与最先进技术相比,接近20%改进。已开源在:https://github.com/koutilya-pnvr/LD-ZNet
6、Diffusion-based Image Translation with Label Guidance for Domain Adaptive Semantic Segmentation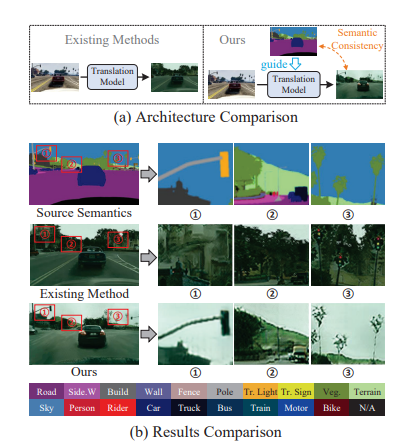
将图像从源域转换到目标域以学习目标模型是域自适应语义分割(DASS)中最常见的策略之一。然而,现有方法仍然很难在原始图像和转换后的图像之间保持语义一致的局部细节。
这项工作提出一种新方法,通过使用源域标签作为显式引导来进行图像转换,以解决这个挑战。具体而言,将跨域图像转换形式化为去噪扩散过程,并利用一种新颖的语义梯度引导(SGG)方法来约束转换过程,将其作为像素级源标签的条件。此外,设计渐进式转换学习(PTL)策略,使SGG方法能够在具有较大差距的域之间可靠地工作。广泛实验证明了方法优越性。
7、DiffuMask: Synthesizing Images with Pixel-level Annotations for Semantic Segmentation Using Diffusion Models
收集和标注像素级标签的图像耗时且费力。相比下,用生成模型(例如DALL-E、Stable Diffusion)可自由生成数据。本文展示通过Off-the-shelf Stable Diffusion模型生成,自动获取准确的语义掩膜,该模型在训练过程中仅用文本-图像对。
方法称为DiffuMask,利用文本和图像之间的交叉注意力图的潜力,将文本驱动的图像合成扩展到语义掩膜生成中。DiffuMask利用文本引导的交叉注意力信息来定位类别/词特定的区域,结合实用技术创建一个新的高分辨率和类别区分的像素级掩膜。这些方法有助于显著降低数据收集和标注成本。实验表明,使用DiffuMask的合成数据训练的现有分割方法在与真实数据(VOC 2012、Cityscapes)相比的性能上取得了竞争力。对于某些类别(例如鸟类),DiffuMask呈现出有希望的性能,接近真实数据的最新结果(mIoU误差在3%以内)。
此外,在开放式词汇分割(零点)设置中,DiffuMask在VOC 2012的未见类别上取得了新的最新结果。已开源在:https://weijiawu.github.io/DiffusionMask/
8、Stochastic Segmentation with Conditional Categorical Diffusion Models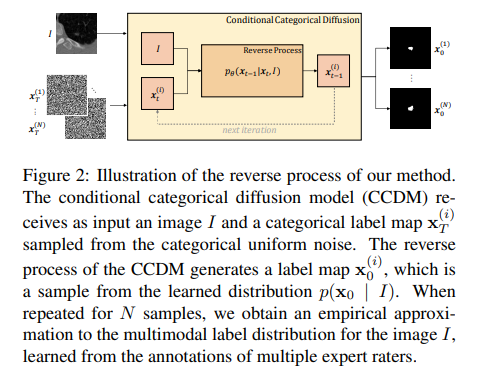
近年来深度神经网络发展,语义分割取得重大进展,但对于医学诊断和自动驾驶等安全关键领域而言,生成与图像内容精确匹配的单一分割输出可能并不合适。相反,可能需要多个正确的分割图来反映标注图的真实分布。在这种情况下,随机语义分割方法必须学习预测在给定图像的条件下标签的条件分布,但是由于通常是多模态分布、高维输出空间和有限的标注数据,这是一项具有挑战性的任务。
为解决这些挑战,提出一种基于去噪扩散概率模型的条件分类扩散模型(CCDM),用于语义分割。模型以输入图像为条件,能够生成多个分割标签图,考虑到由不同的真实标注产生的aleatoric不确定性。实验结果表明,CCDM在LIDC(一种随机语义分割数据集)上取得了最新的最佳性能,并在经典分割数据集Cityscapes上优于已经建立的基线。
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
不是一杯奶茶喝不起,而是我T M直接用来跟进 AIGC+CV视觉 前沿技术,它不香?!
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
 戳我,查看GAN的系列专辑~! 最新最全100篇汇总!生成扩散模型Diffusion Models ECCV2022 | 生成对抗网络GAN部分论文汇总
戳我,查看GAN的系列专辑~! 最新最全100篇汇总!生成扩散模型Diffusion Models ECCV2022 | 生成对抗网络GAN部分论文汇总 CVPR 2022 | 25+方向、最新50篇GAN论文
ICCV 2021 | 35个主题GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击 跟进 AIGC+CV视觉 前沿技术,真香! ,加入 AI生成创作与计算机视觉 知识星球!