
2021年必读的10 个计算机视觉论文总结

极市导读
本文是作者总结的今年计算机视觉领域最有趣的 10 篇研究论文,它是一个精选的 AI 和 CV 最新突破列表,本篇文章将带有清晰的视频解释和代码(如果有)。本文末尾列出了对每篇论文的完整参考。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
2021 年排名前 10 的计算机视觉论文,包括视频演示、文章、代码和论文参考。
世界的经济活动在病毒的冲击下陷入了历史罕见的停滞中,但研究并没有放慢其狂热的步伐,尤其是在人工智能领域。今年的论文中除了一般的研究结果外还强调了许多重要方面,例如道德方面、重要偏见、治理、透明度等等。人工智能和我们对人脑及其与人工智能的联系的理解不断发展,显示出在不久的将来改善我们生活质量的有前景的应用。不过,我们应该谨慎选择应用哪种技术。
“科学不能告诉我们应该做什么,只能告诉我们可以做什么。”—— Jean-Paul Sartre, Being and Nothingness
以下是作者总结的今年计算机视觉领域最有趣的 10 篇研究论文,简而言之,它基本上是一个精选的 AI 和 CV 最新突破列表,本篇文章将带有清晰的视频解释和代码(如果有)。本文末尾列出了对每篇论文的完整参考。
完整视频链接:
DALL·E: Zero-Shot Text-to-Image Generation from OpenAI [1]
OpenAI 成功训练了一个能够从文本标题生成图像的网络。它与 GPT-3 和 Image GPT 非常相似,并产生了惊人的结果。
代码:https://github.com/openai/DALL-E

Taming Transformers for High-Resolution Image Synthesis [2]
将 GAN 和卷积方法的效率与Transformers 的表达能力相结合,为语义引导的高质量图像合成提供了一种强大且省时的方法。
代码:https://github.com/CompVis/taming-transformers
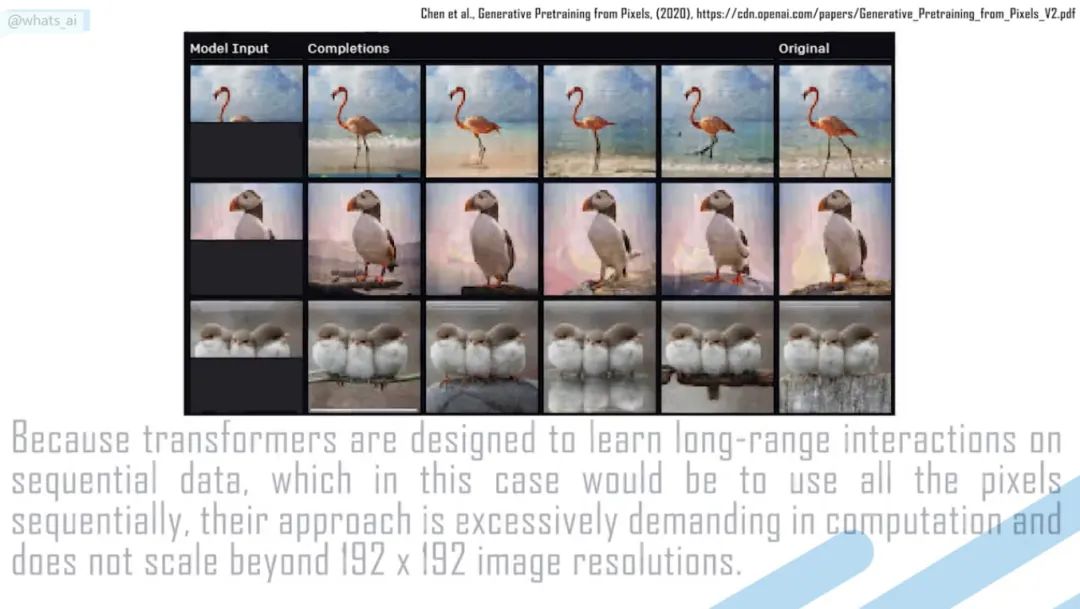
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows [3]
Transformers 会取代计算机视觉中的 CNNs 吗?在不到 5 分钟的时间内,通过一篇名为 Swin Transformer 的新论文了解如何将 Transformer 架构应用于计算机视觉。
代码:https://github.com/microsoft/Swin-Transformer

Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image [4]
视图合成的下一步:目标是拍摄一张图像,然后就可以进到图像中去探索风景!
DEMO:
https://colab.research.google.com/github/google-research/google-research/blob/master/infinite_nature/infinite_nature_demo.ipynb#scrollTo=sCuRX1liUEVM

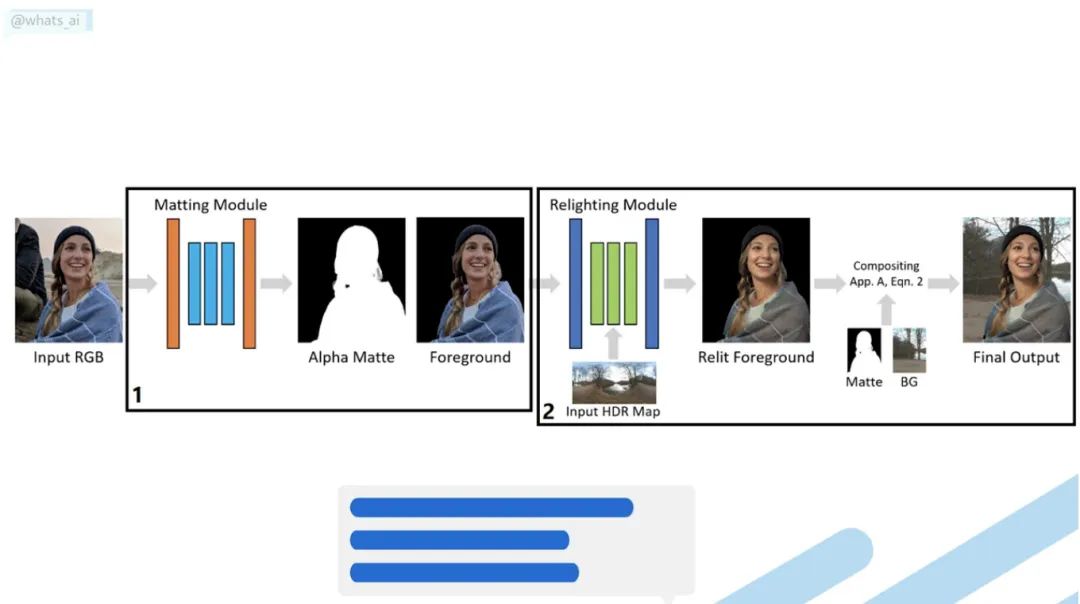
Total Relighting: Learning to Relight Portraits for Background Replacement [5]
根据添加的新背景的亮度重新为肖像补光。你有没有想过改变图片的背景,但让它看起来很逼真?如果已经尝试过就会知道这并不简单。你在家里拍一张自己的照片然后改变成海滩的背景, 任何人都会在一秒钟内说“那是经过Photoshop处理的”。对于电影和专业视频,需要完美的灯光和艺术家来再现高质量的图像,这非常昂贵。你无法用自己的照片做到这一点。但是这篇论文做到了
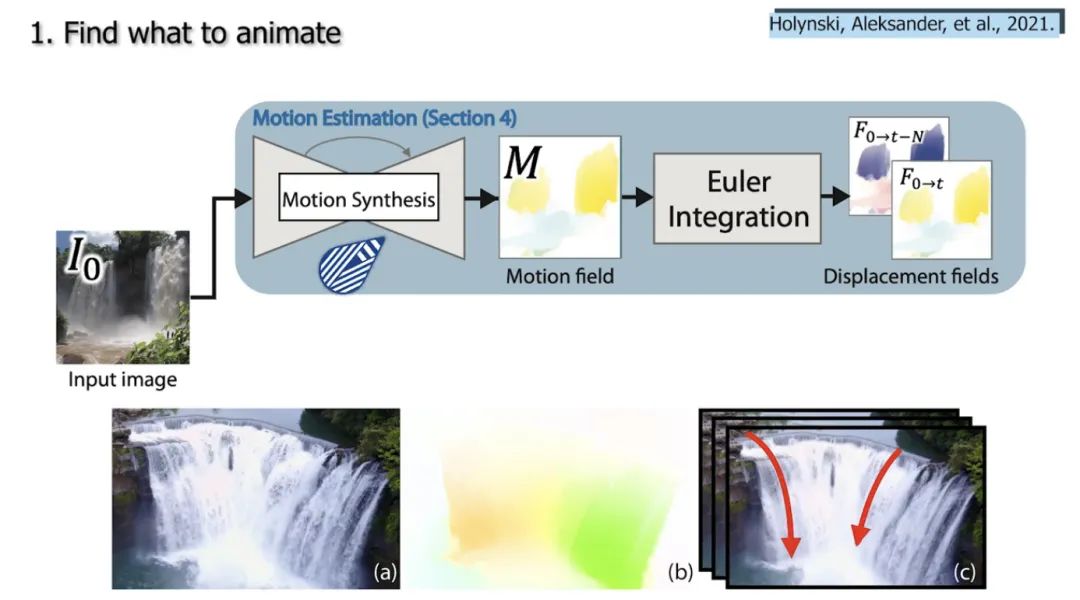
Animating Pictures with Eulerian Motion Fields [6]
该模型只通过拍摄一张照片,就能够了解哪些粒子应该在移动,并可以在限循环中为它们设置逼真的动画,同时完全保留图片的其余部分,这样我们可以将图片转换成动画……
代码:https://eulerian.cs.washington.edu/
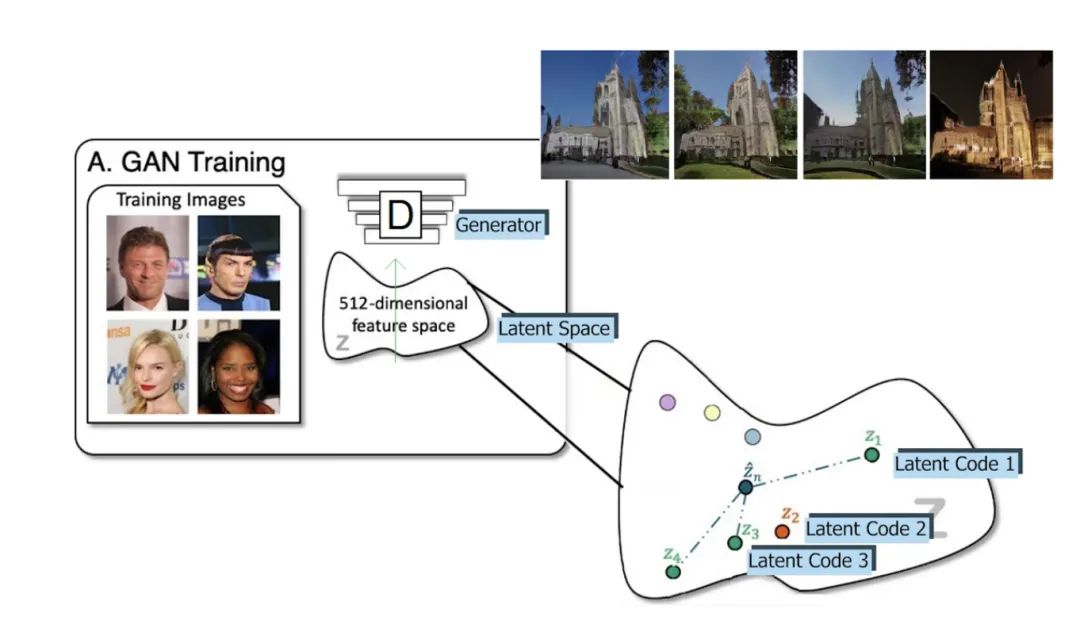
CVPR 2021 Best Paper Award: GIRAFFE — Controllable Image Generation [7]
使用修改后的 GAN 架构,他们可以在不影响背景或其他对象的情况下移动图像中的对象!
代码:https://github.com/autonomousvision/giraffe
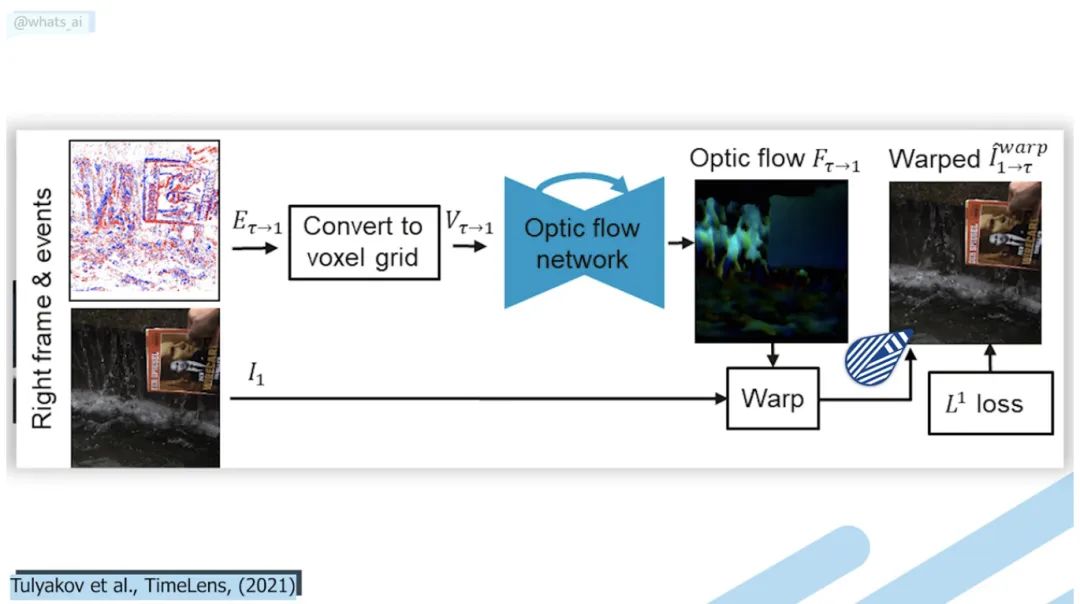
TimeLens: Event-based Video Frame Interpolation [8]
TimeLens 可以理解视频帧之间粒子的运动,用我们肉眼看不到的速度重建真正发生的事情。它达到了智能手机和其他机型无法达到的效果!
代码:https://github.com/uzh-rpg/rpg_timelens
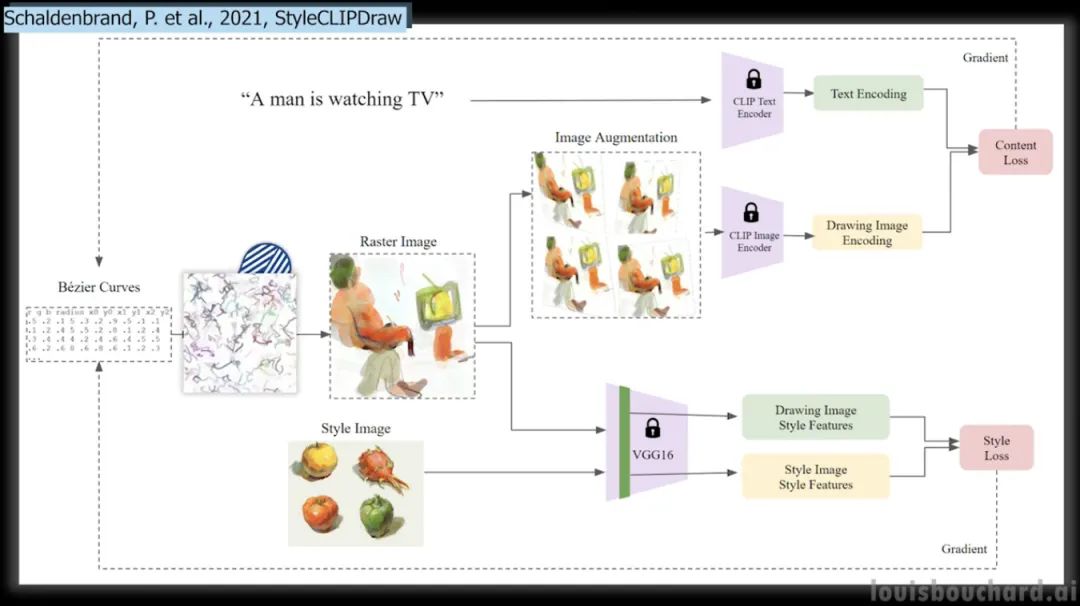
CLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis [9]
你有没有想过把照片的风格,比如左边这个很酷的绘画风格,应用到你选择的新照片上?这个模型能够做到,甚至可以仅从文本中实现这一点,并且还提供了可以立即尝试使用这种新方法及其适用于所有人的 Google Colab 。简单的拍一张你要复制的样式的图片,输入你要生成的文字,这个算法就会生成一张新的图片!结果非常令人印象深刻,特别它们可以由一行文本制成的!
DEMO:https://colab.research.google.com/github/kvfrans/clipdraw/blob/main/clipdraw.ipynb
https://colab.research.google.com/github/pschaldenbrand/StyleCLIPDraw/blob/master/Style_ClipDraw.ipynb
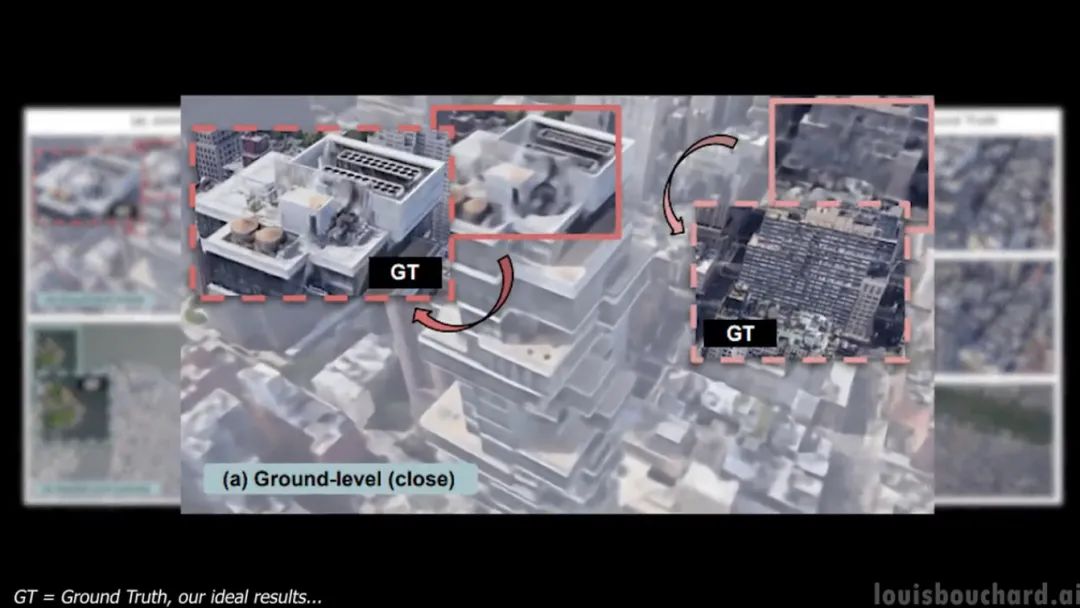
CityNeRF: Building NeRF at City Scale [10]
该模型称为 CityNeRF,是从 NeRF 发展而来的, NeRF 是最早使用辐射场和机器学习从图像构建 3D 模型的模型之一。但 NeRF 效率不高而且只适用于单一规模。在这里,CityNeRF 同时应用于卫星和地面图像,生成各种 3D 模型。简而言之他们将 NeRF 带入了城市规模。
代码:https://city-super.github.io/citynerf/
引用:
[1] A. Ramesh et al., Zero-shot text-to-image generation, 2021. arXiv:2102.12092
[2] Taming Transformers for High-Resolution Image Synthesis, Esser et al., 2020.
[3] Liu, Z. et al., 2021, “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”, arXiv preprint https://arxiv.org/abs/2103.14030v1[bonus] Yuille, A.L., and Liu, C., 2021. Deep nets: What have they ever done for vision?. International Journal of Computer Vision, 129(3), pp.781–802, https://arxiv.org/abs/1805.04025.
[4] Liu, A., Tucker, R., Jampani, V., Makadia, A., Snavely, N. and Kanazawa, A., 2020. Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image, https://arxiv.org/pdf/2012.09855.pdf
[5] Pandey et al., 2021, Total Relighting: Learning to Relight Portraits for Background Replacement, doi: 10.1145/3450626.3459872, https://augmentedperception.github.io/total_relighting/total_relighting_paper.pdf.
[6] Holynski, Aleksander, et al. “Animating Pictures with Eulerian Motion Fields.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[7] Michael Niemeyer and Andreas Geiger, (2021), “GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields”, Published in CVPR 2021.
[8] Stepan Tulyakov, Daniel Gehrig, Stamatios Georgoulis, Julius Erbach, Mathias Gehrig, Yuanyou Li, Davide Scaramuzza, TimeLens: Event-based Video Frame Interpolation, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, 2021, http://rpg.ifi.uzh.ch/docs/CVPR21_Gehrig.pdf
[9] a) CLIPDraw: exploring text-to-drawing synthesis through language-image encodersb) StyleCLIPDraw: Schaldenbrand, P., Liu, Z. and Oh, J., 2021. StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis.
[10] Xiangli, Y., Xu, L., Pan, X., Zhao, N., Rao, A., Theobalt, C., Dai, B. and Lin, D., 2021. CityNeRF: Building NeRF at City Scale.
本文作者:Louis Bouchard
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
