
基于深度学习的多目标跟踪(MOT)技术一览
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
本文是一篇多目标跟踪方向的调研报告,从相关方向、核心步骤、评价指标和最新进展等维度出发,对MOT进行了全面的介绍,不仅适合作为入门科普,而且能够帮助大家加深理解。
最近做了一些多目标跟踪方向的调研,因此把调研的结果以图片加文字的形式展现出来,希望能帮助到入门这一领域的同学。也欢迎大家和我讨论关于这一领域的任何问题。
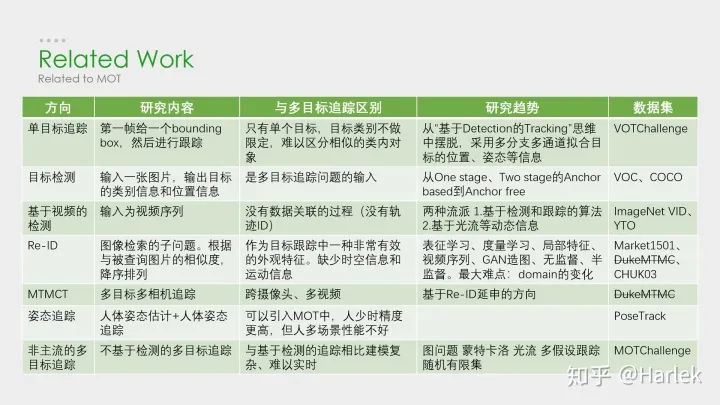
相关方向
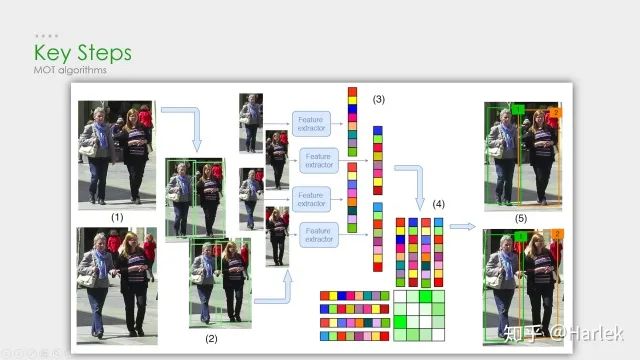
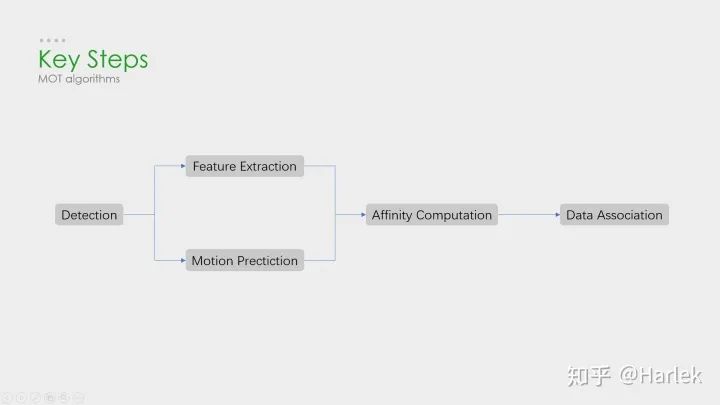
核心步骤
评价指标

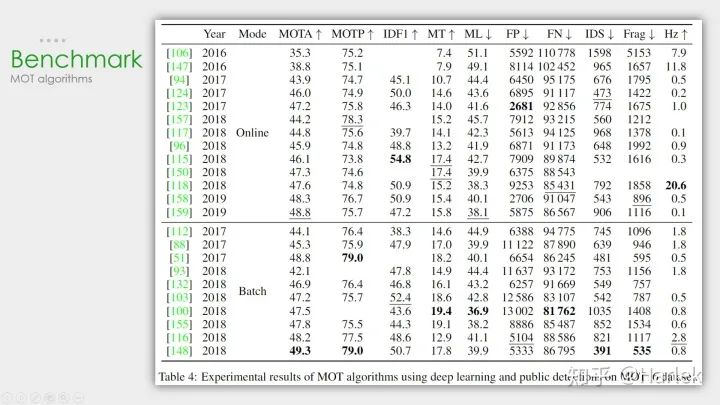
数据集

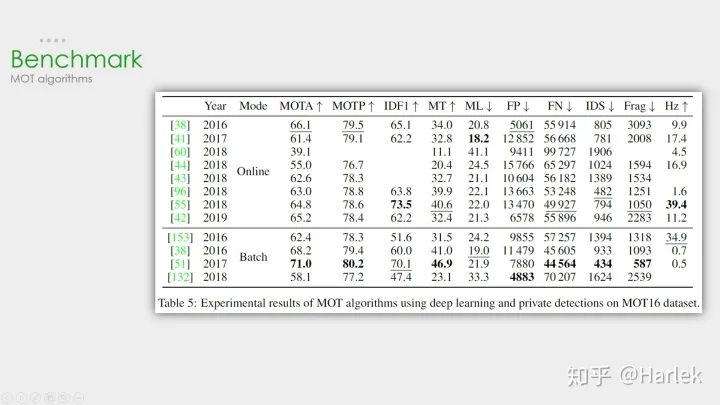

SORT和DeepSORT
关键算法
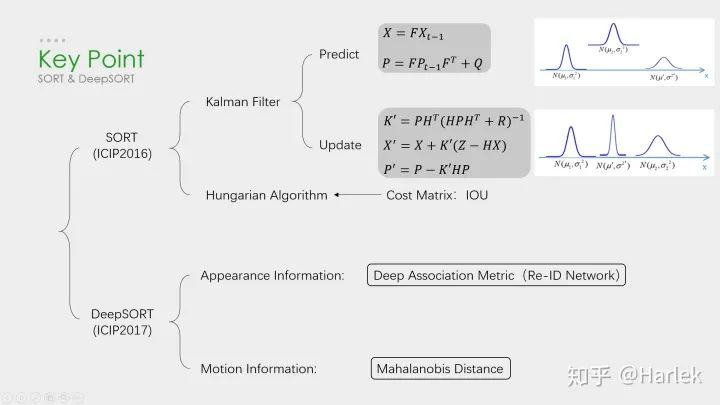
SORT
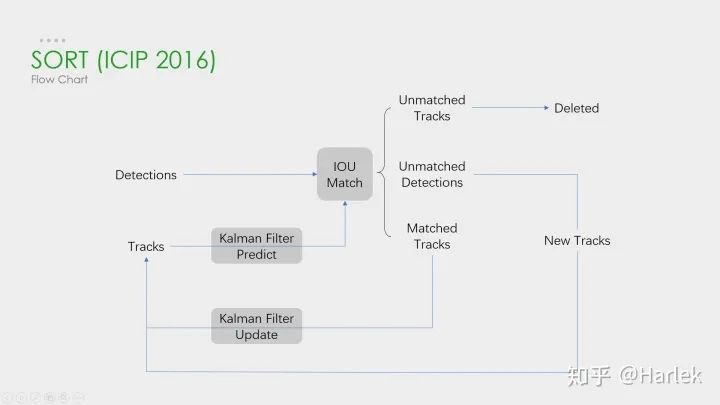
首先,恒定速度模型不能很好地预测真实的动力学,其次,我们主要关注的是帧到帧的跟踪,其中对象的重新识别超出了本文的范围。
DeepSORT
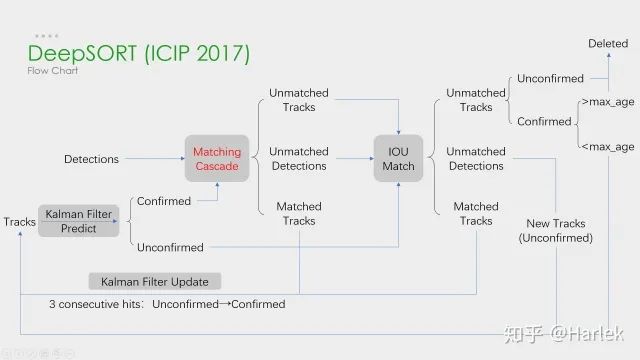
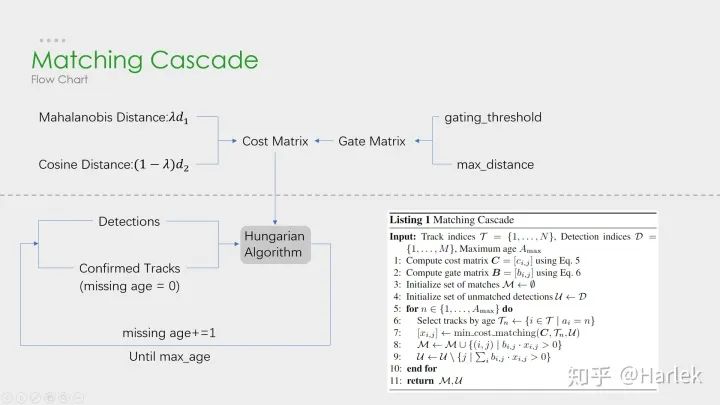
在我们的实验中,我们发现当相机运动明显时,将λ= 0设置是一个合理的选择。
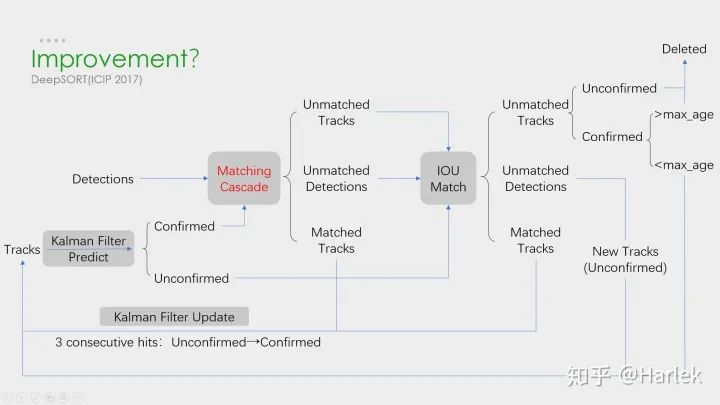
改进策略

最新进展

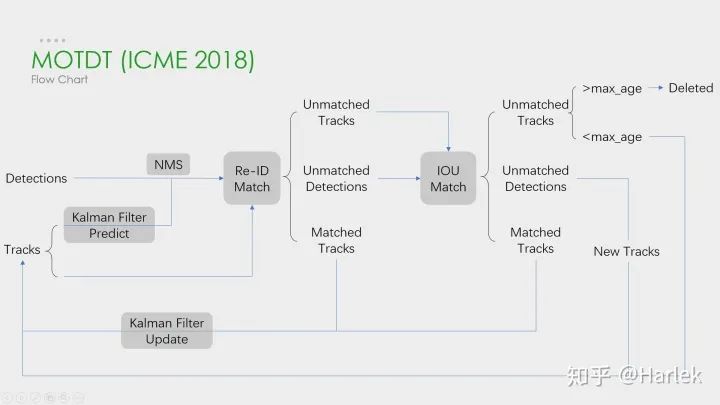
MOTDT
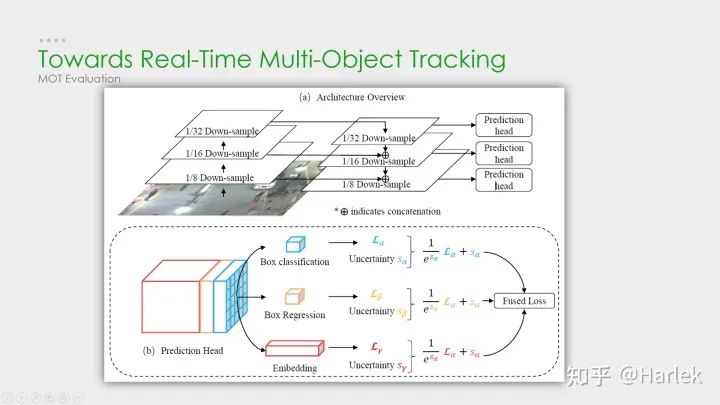
JDE
未来展望

评论