40亿条/秒!Flink流批一体在阿里双11首次落地的背后

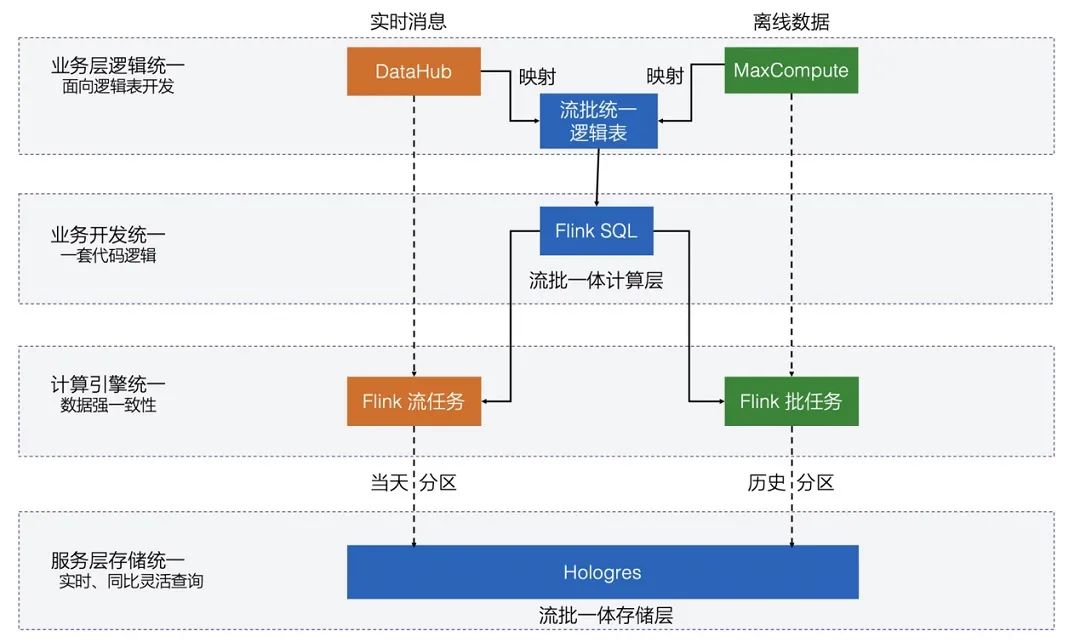
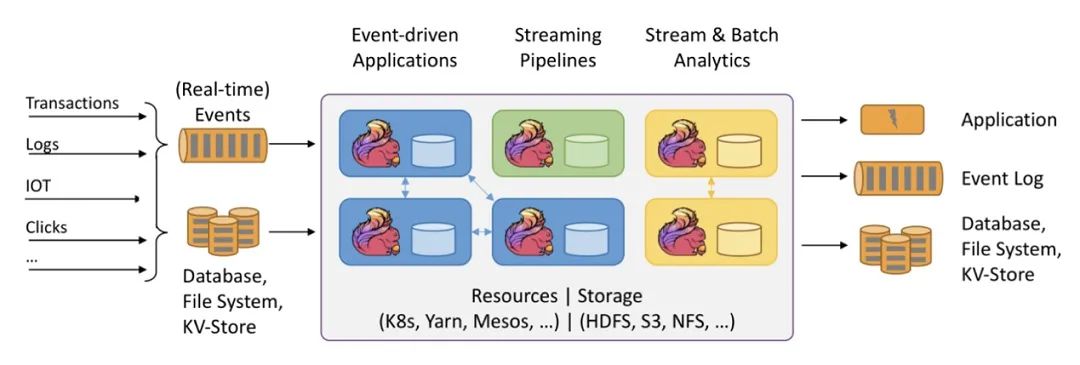
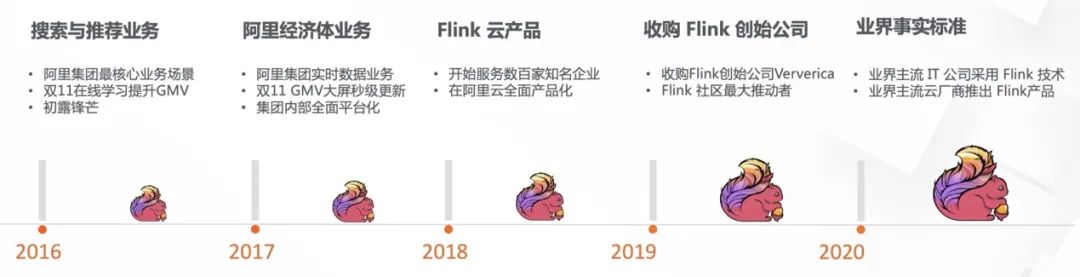
阿里妹导读:今年的双11,实时计算处理的流量洪峰创纪录地达到了每秒40亿条的记录,数据体量也达到了惊人的每秒7TB,基于Flink的流批一体数据应用开始在阿里巴巴最核心的数据业务场景崭露头角,并在稳定性、性能和效率方面都经受住了严苛的生产考验。本文深度解析“流批一体”在阿里核心数据场景首次落地的实践经验,回顾“流批一体”大数据处理技术的发展历程。





评论
 下载APP
下载APP
阿里妹导读:今年的双11,实时计算处理的流量洪峰创纪录地达到了每秒40亿条的记录,数据体量也达到了惊人的每秒7TB,基于Flink的流批一体数据应用开始在阿里巴巴最核心的数据业务场景崭露头角,并在稳定性、性能和效率方面都经受住了严苛的生产考验。本文深度解析“流批一体”在阿里核心数据场景首次落地的实践经验,回顾“流批一体”大数据处理技术的发展历程。