
模型量化: 训练时噪音带来的极致压缩

极市导读
本文介绍了一篇关于使用噪音的方式进行改进的压缩方法,成功的将Roberta压缩到了14M,将EfficientNetB3压缩到了3.3M,分别达到了34x和14x的压缩倍率。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
我们在模型量化这片文章中,介绍了在训练时是如何做量化的。
https://zhuanlan.zhihu.com/p/353597270
文献[1]基于这个工作,进一步引入了其他的压缩方法,并用噪音的方式进行了改进,成功的将Roberta压缩到了14M,将EfficientNetB3压缩到了3.3M,分别达到了34x和14x的压缩倍率。
量化噪音
这个概念其实挺容易理解,就是在训练时做量化,会带来权重的变化,这个变化称之为噪音。在模型量化: 只有整数计算的高效推理,模型在训练时就把权重和activation做了量化,并基于量化后的参数进行fine-tune。
在文献[1]中,提出了部分量化的做法,即每次只把一部分参数和激活值做量化,其他的值不变,按照原来的方式进行梯度计算。这样的方法比训练时就全部做量化要好一些,见下图:
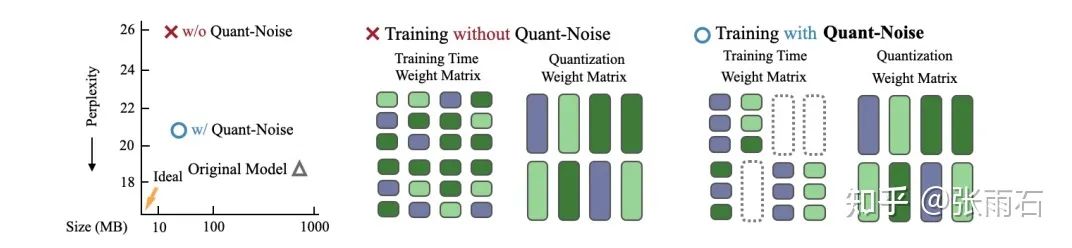
但在inference的时候,是全部都要做量化的。
部分量化是论文[1]的核心点,剩下的就是将训练时部分量化与其他的量化技术结合。
量化压缩
在神经网络中,需要量化的参数一般都是矩阵W,这里假设矩阵的size是n * p。常见的压缩方法是对矩阵进行切分,切分成mxq个小矩阵。然后小矩阵上做codebook查找,即找到K个vector做成codebook,然后m * q个小矩阵,每个都表示成在codebook上查到的索引,从而达到压缩的目的。

基于上面的介绍,量化就分成了两种:
Fixed-point scalar Quantization,即对值进行量化。 Product quantization,即对矩阵进行量化
值量化
其中,对值进行量化就是给当前值找到最接近的量化后的值:
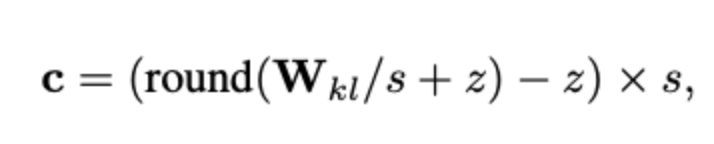
其中,
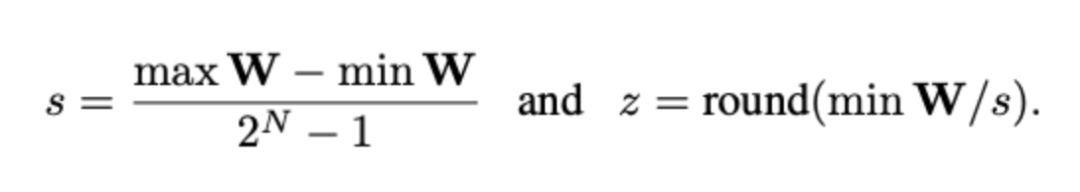
取决于量化后的bit数目,假设量化后是N位bit,那么压缩率就是32/N。如果N=4,那么就是int4 quantization, 如果N=8,则是int8 Quantization
矩阵量化
对于矩阵量化(PQ)来说,传统的方法是:
将大矩阵的每一列分成m个子vector,这样就有m * p个子vector。 每个子vector表达成codebook中离它最近的vector。 codebook使用K-means方法学习得到。 所以矩阵被表示成了索引矩阵,如果codebook中一共只有256个vector,那么索引矩阵中的每个值都是8bit的,就有了量化的效果,注意,此时codebook中的vector还可以是float值。
所以目标函数如下所示,即让原矩阵和量化后矩阵欧氏距离最近。

但这种矩阵量化的方式会导致偏差积累,从而导致层次比较深的时候会发生比较大的漂移。
因此,一个改进的方法就是从底层到高层迭代的去做矩阵量化,称之为迭代式矩阵量化(Iterative Product Quantization, iPQ)。迭代到某一层的时候,会对其上层做fine-tune。
矩阵量化和值量化是可以结合起来达到更高的压缩率。它们还可以和上一部分介绍的噪音也进行叠加。在训练时,矩阵量化可以一个epoch重新运行k-means算法来更新。
实验结果
各种量化方法的对比如下图,其中QAT方法是不加噪音的fine-tune。可以看到加了噪音后会在更高的压缩比上得到不错的效果。
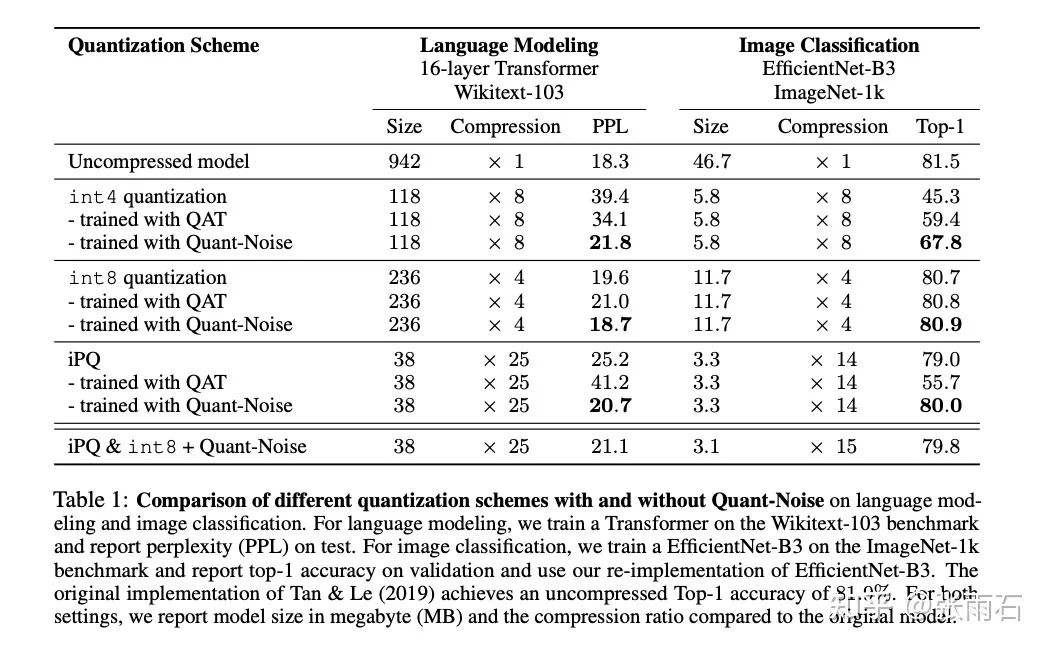
另外,不同的压缩比率和效果与其他模型的对比:
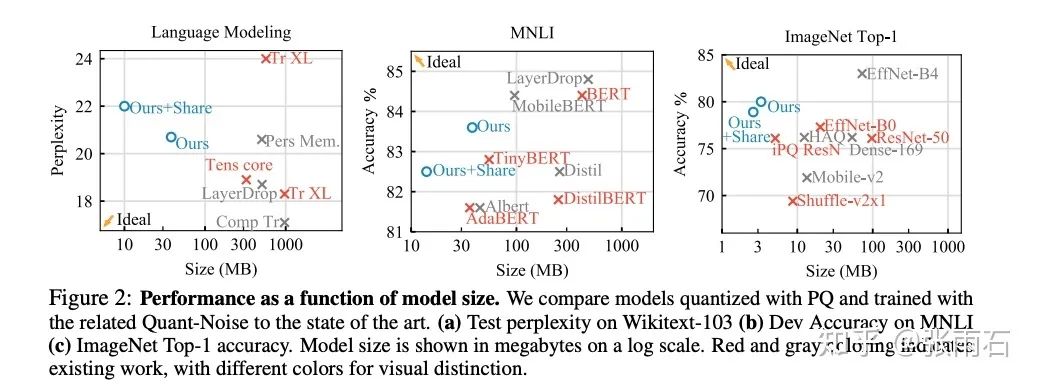
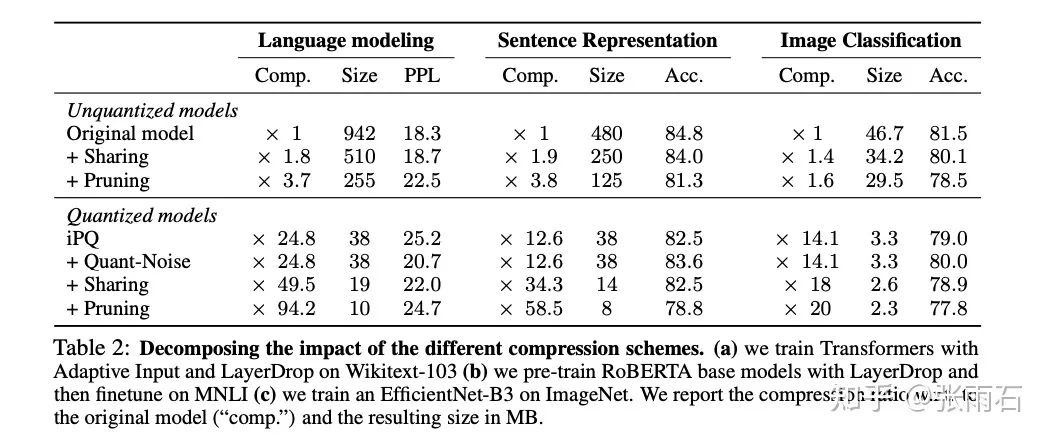
除此之外,还可以和weight sharing与pruning联合使用。得到:
参考文献
[1]. Fan, A., Stock, P., Graham, B., Grave, E., Gribonval, R., Jégou, H. and Joulin, A., 2020. Training with quantization noise for extreme model compression. arXiv e-prints, pp.arXiv-2004.
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“83”获取朱思语:基于深度学习的视觉稠密建图和定位直播链接~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
